LeX-10K
收藏arXiv2025-03-28 更新2025-03-29 收录
下载链接:
https://zhaoshitian.github.io/lexart/
下载链接
链接失效反馈官方服务:
资源简介:
LeX-10K是一个由上海人工智能实验室和香港中文大学创建的高质量文本图像数据集。该数据集包含10,000张高分辨率、审美精致、1024×1024像素的图像,通过DeepSeek-R1增强提示和多层次筛选与润色构建而成。数据集的构建旨在提高文本图像合成的质量,特别是在文本准确性和审美质量方面。
LeX-10K is a high-quality text-to-image dataset developed by the Shanghai AI Laboratory and The Chinese University of Hong Kong. This dataset includes 10,000 high-resolution, aesthetically refined 1024×1024 pixel images, constructed using DeepSeek-R1 enhanced prompts and multi-level filtering and polishing processes. The dataset is developed to improve the quality of text-to-image synthesis, particularly in terms of textual accuracy and aesthetic quality.
提供机构:
上海人工智能实验室, 香港中文大学
创建时间:
2025-03-28
搜集汇总
数据集介绍
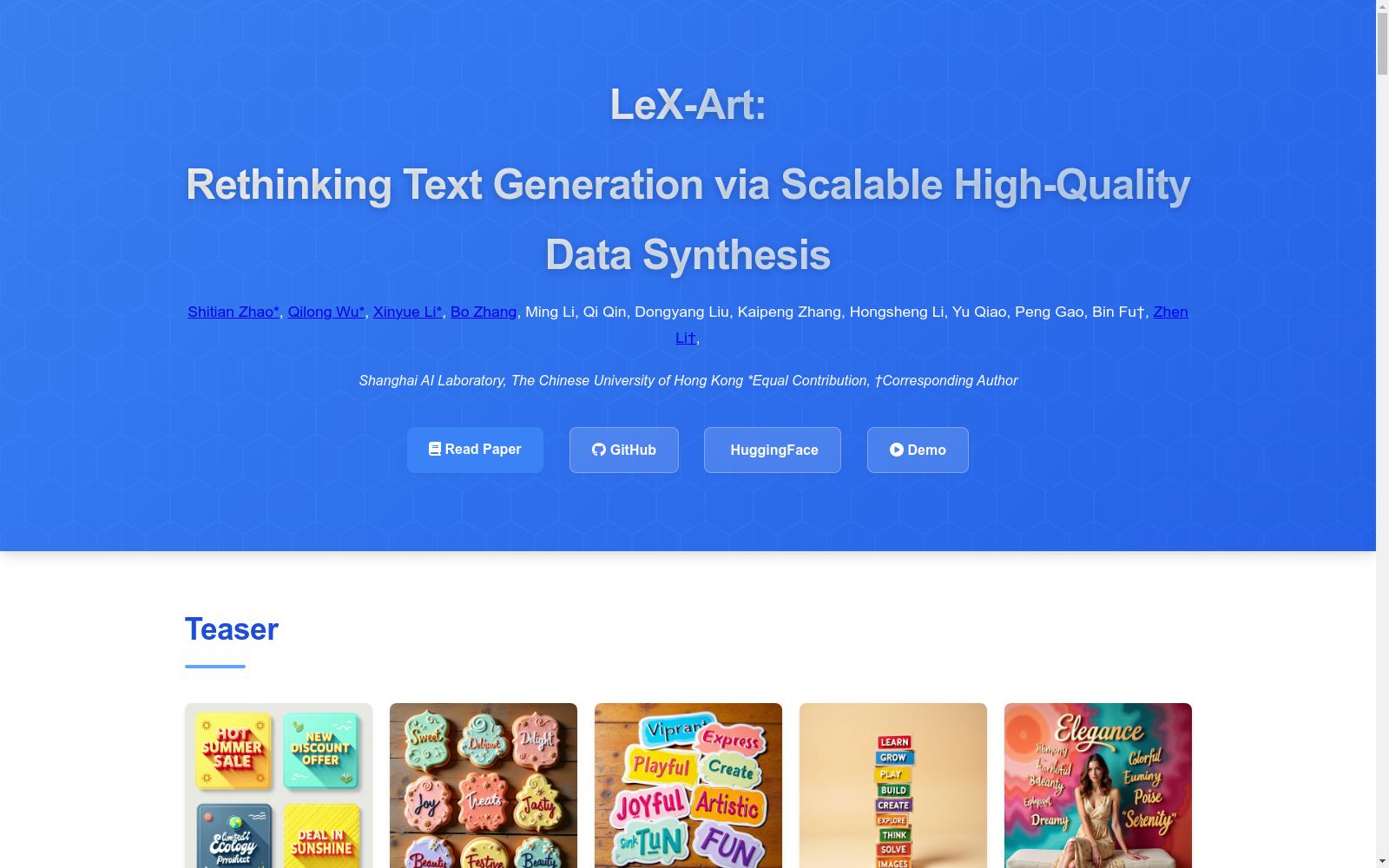
构建方式
在视觉文本生成领域,高质量数据集的构建是提升文本渲染能力的关键。LeX-10K数据集通过四阶段结构化流程构建:首先利用DeepSeek-R1对初始提示进行增强,生成包含字体、颜色和空间布局等细粒度视觉属性的详细描述;随后采用多阶段过滤策略,基于Q-Align和Paddle-OCR-v3对合成图像进行质量评估与筛选,确保图像分辨率为1024×1024且具有美学吸引力;继而通过GPT-4o驱动的知识增强重标注模块,修正图像与文本描述间的对齐偏差;最终构建的10K图像-文本对经过严格的质量控制流程,包括最佳样本选择(Best-of-N)和文本区域阈值过滤,形成具有精确空间布局与丰富文本属性的高质量数据集。
特点
作为视觉文本生成领域的专项数据集,LeX-10K具有三个显著特征:其多模态特性体现在每张图像均配有经过知识增强的详细文本描述,涵盖字体样式、色彩搭配与动态布局等17类视觉属性;数据质量方面,通过定量分析显示其图像质量分数(Q-Align)比AnyWord-3M基准提升38.7%,美学评分分布呈现明显的右偏特征;场景覆盖维度上,数据集包含创意设计、商业标识、艺术排版等8大应用场景,其中复杂布局样本占比达63%,且所有文本均通过PNED指标(阈值<0.3)验证其OCR识别准确性。
使用方法
该数据集主要服务于文本到图像生成模型的微调与评估。使用时需注意三阶段流程:预处理阶段建议采用提供的分层抽样策略(70%训练/15%验证/15%测试),并搭配LeX-Enhancer提示增强模型以释放数据潜力;训练阶段推荐使用FSDP框架进行分布式训练,对于FLUX架构模型建议采用1e-6学习率与batch size 8的配置;评估阶段应结合LeX-Bench基准工具包,通过PNED指标(Pairwise Normalized Edit Distance)量化文本渲染准确性,同时使用CLIPScore评估视觉-文本对齐度。对于学术研究,建议重点分析数据集中复杂布局样本(单词数≥5)的跨模态对齐表现。
背景与挑战
背景概述
LeX-10K是由上海人工智能实验室和香港中文大学的研究团队于2025年提出的高质量文本图像合成数据集,旨在解决文本到图像生成模型在视觉文本渲染方面的关键挑战。该数据集包含10,000张高分辨率(1024×1024)的文本图像,每张图像均经过美学优化和精细标注。LeX-10K的构建基于DeepSeek-R1的强推理能力,通过多阶段过滤和知识增强的重标注流程,显著提升了文本渲染的保真度与美学质量。其核心研究问题聚焦于如何通过数据中心的范式,弥合提示表达与高质量文本渲染之间的鸿沟,为设计、广告和艺术创作等领域提供了重要的基准资源。
当前挑战
LeX-10K面临的挑战主要体现在两方面:领域问题与构建过程。在领域层面,文本到图像生成模型常因文本编码失真导致渲染失败,需解决多文本场景、细粒度属性控制(如字体、颜色)和复杂布局的难题。构建过程中,数据质量的不一致性(如低分辨率、模糊文本)和美学缺失需通过多阶段筛选(Q-Align和OCR检测)克服;此外,生成图像与提示的对齐问题需依赖GPT-4o的知识增强重标注模块进行修正。这些挑战要求兼顾文本准确性与视觉和谐性,推动了对新型评估指标(如PNED)的需求。
常用场景
经典使用场景
在视觉文本生成领域,LeX-10K数据集通过其高分辨率(1024×1024)和美学优化的图像,为文本到图像(T2I)模型的训练提供了高质量的基准。该数据集特别适用于多词语境下的复杂布局文本生成,能够支持模型学习如何在保持文本清晰度的同时,实现字体风格、颜色和空间布局的精确控制。例如,在生成海报设计、艺术字体或品牌标志时,LeX-10K能够帮助模型生成既美观又与背景和谐融合的文本图像。
实际应用
在实际应用中,LeX-10K支持的设计场景包括动态标语生成、品牌视觉系统开发和个性化艺术创作。例如,广告行业可利用其生成符合品牌调性的多语言标语,确保文字在复杂背景中的可读性与风格统一;电商平台能快速产出带有促销文本的商品海报,精确控制价格标识的字体和颜色。此外,教育领域可借助该数据集生成图文并茂的学习材料,其中嵌入的术语文本既能保持学术准确性,又能与插图自然融合。
衍生相关工作
LeX-10K催生了多项创新工作,包括轻量级提示增强模型LeX-Enhancer和两代文本生成模型(LeX-FLUX与LeX-Lumina)。这些模型在LeX-Bench基准测试中展现了卓越性能,其中LeX-Lumina的2B参数量版本在文本召回率上超越基线34%。相关研究还提出了PNED指标,通过匈牙利算法优化无序文本匹配,成为评估非字形条件生成的新标准。后续工作如Glyph-ByT5等均借鉴了该数据集的数据合成策略,推动领域从控制驱动向数据驱动范式转变。
以上内容由遇见数据集搜集并总结生成


