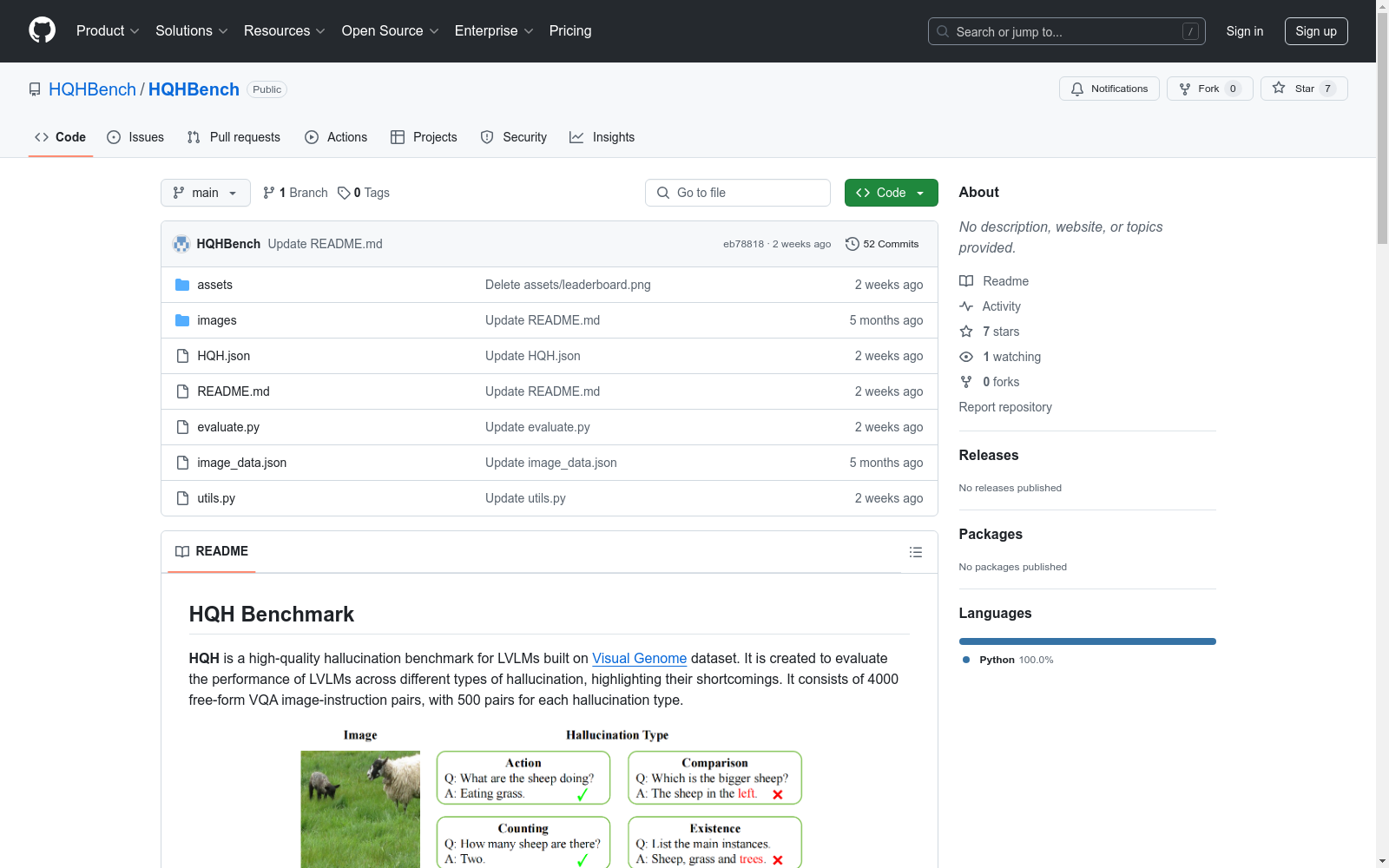
High-Quality Hallucination Benchmark (HQH)
收藏数据集概述
数据集名称
HQH Benchmark
数据集描述
HQH 是一个高质量的幻觉基准测试数据集,专为大型视觉-语言模型(LVLMs)设计。该数据集基于 Visual Genome 数据集构建,旨在评估 LVLMs 在不同类型的幻觉问题上的表现,并突出其不足之处。数据集包含 1600 个自由形式的视觉问答(VQA)图像-指令对,每种幻觉类型有 200 对。
数据结构
数据集文件 HQH.json 的格式如下:
python [ {"id": 1, "image_id": 150494, "image": "./images/150494.jpg", "instruction": "What is the man in a suit doing?", "ground_truth": "Giving a speech.", "type": "action"}, ... ]
其中:
id:数据在 HQH 中的标识符。image_id:图像在 Visual Genome 中的标识符。image:图像路径。instruction:指令。ground_truth:标准答案。type:幻觉类型。
数据下载
图像可以从 此链接 下载。图像注释保存在 image_data.json 文件中。
评估方法
使用 GPT-3.5 计算幻觉率作为评估指标。评估代码在 evaluate.py 中提供,运行方式如下:
python python evaluate.py --ans_file path/to/your/answer/file --openai_key your/openai/api/key --num model/num/for/evaluation
LVLMs 的答案应组织在一个 JSON 文件中,格式如下:
python [ {"id": 1, "image_id": 150494, "image": "./images/150494.jpg", "instruction": "What is the man in a suit doing?", "ground_truth": "Giving a speech.", "type": "action", "answers": ["The man in the suit is giving a speech to a group of soldiers.",...]}, ... ]
即在 HQH.json 的每个实例中添加一个 "answers" 字段。