Thai-Thangkarn-sentence
收藏Hugging Face2025-05-25 更新2025-05-26 收录
下载链接:
https://huggingface.co/datasets/nnudee/Thai-Thangkarn-sentence
下载链接
链接失效反馈官方服务:
资源简介:
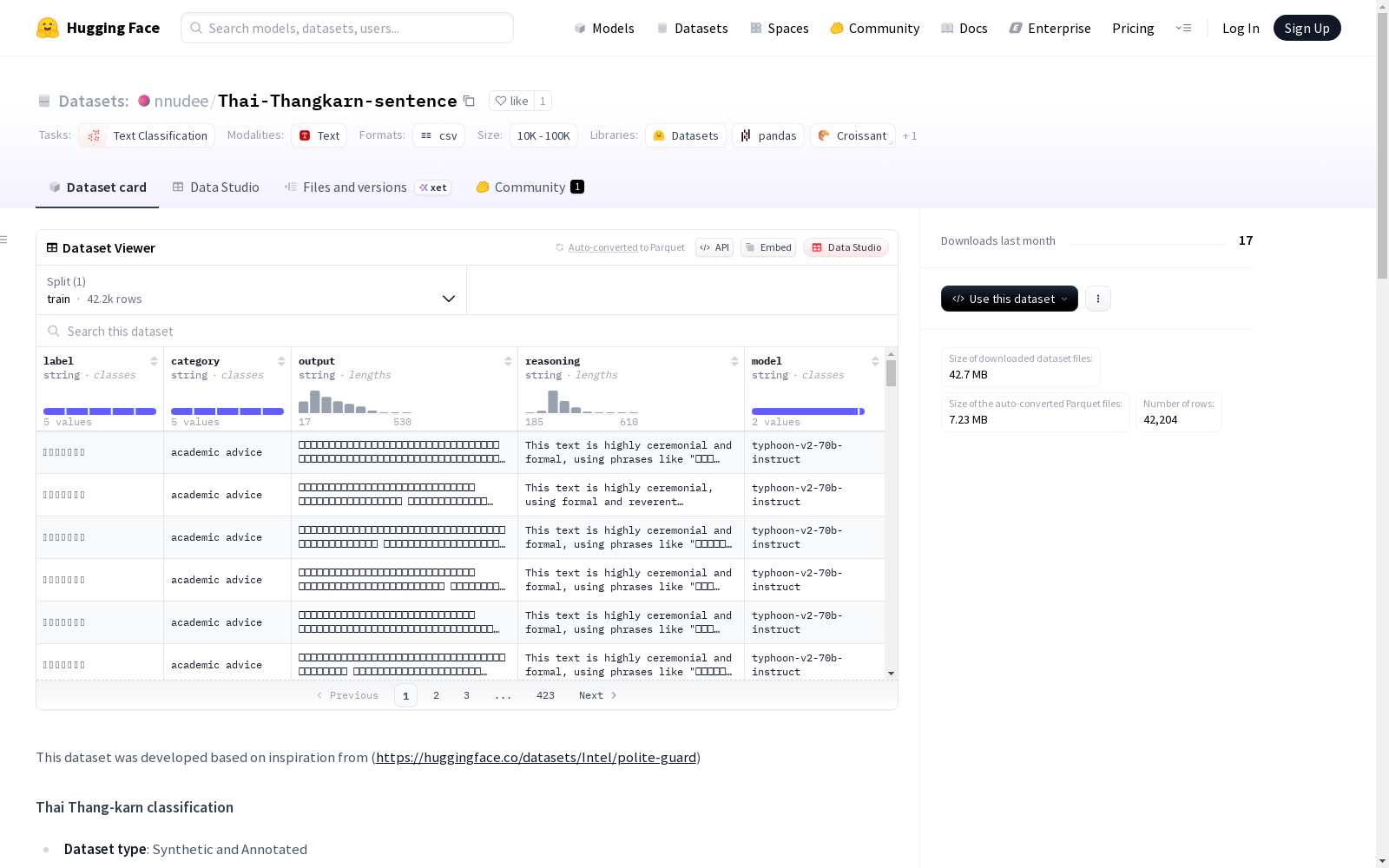
该数据集是基于少量样本提示(Few-shot prompting)生成的合成和注释数据集,用于文本分类任务。数据集分为五大类别:礼仪、官方、半官方、非正式和口语。每个类别下的样本数量分别为:官方8500个,非正式8500个,半官方8500个,礼仪8498个,口语8206个。数据集按80%训练集、10%验证集和10%测试集的比例进行划分,并且每个集合都根据标签进行了平衡。数据集中的每个样例都包括文本输入、分类标签、使用的LLM模型以及生成文本的理由。数据集包含学生和老师之间的对话,话题涉及学术建议、出勤问题、提交通知、文件请求和感激尊重等。数据生成过程中使用了两种模型:typhoon-v2-70b-instruct和OpenAI GPT 4.1。
创建时间:
2025-05-20
原始信息汇总
数据集概述
基本信息
- 数据集名称: Thai Thang-karn classification
- 任务类型: 文本分类 (text-classification)
- 数据集类型: 合成与标注 (Synthetic and Annotated)
- 领域: 泰语语法中的礼仪分类 (Ceremonial [พิธีการ], Official [ทางการ], Semi-Official [กึ่งทางการ], Informal [ไม่เป็นทางการ], coloquial [กันเอง])
- 数据来源: 基于Few-shot prompting生成
- 源代码: https://github.com/nnudee/Thai-Thang-karn_text-classification/tree/main/data-generator
数据集统计
- 总样本数: 42204
- Official [ทางการ]: 8500
- Informal [ไม่เป็นทางการ]: 8500
- Semi-Official [กึ่งทางการ]: 8500
- Ceremonial [พิธีการ]: 8498
- coloquial [กันเอง]: 8206
- 数据分割:
- 训练集: 80%
- 验证集: 10%
- 测试集: 10%
- 每个集合均按标签平衡
数据内容
- 字段:
text: 文本输入 (字符串)label: 分类标签 (5个类别)model: 用于生成合成文本的LLM模型reasoning: 语言模型生成文本时的推理依据 (字符串)
主题与子主题
数据包含师生对话,涵盖以下主题及子主题:
- Academic advice:
- Project consultation, Thesis guidance, Research help, Supervision request, Academic support, Topic approval, Proposal feedback, Revision discussion, Advisor meeting, Outline clarification
- Attendance issue:
- Request leave, Class absence, Late arrival, Early leave, Absence notification, Sick leave, Personal leave, Unexpected issue, Urgent matter, Inform absence in advance
- Submission notification:
- Late submission, Delay in assignment, Extension request, Submission issue, Technical problem, File error, Missed deadline, Re-submission request, Upload failed, Report delay
- Document request:
- Request certificate, Transcript request, Official letter, Endorsement letter, Confirmation document, Attendance letter, Internship certificate, Recommendation letter, Student status proof, Degree verification
- Gratitude respect:
- Thank you, Appreciation, Show respect, Gratitude expression, Farewell message, Warm regards, Thankful note, Respectful message, Honor expression, Final thanks
生成细节
- 模型: typhoon-v2-70b-instruct, OpenAI GPT 4.1
- 多样性处理: 随机代词和例句
- 数据正则化: 均衡选择标签和类别
- 排除内容: 不符合预期的电子邮件/聊天风格输出
搜集汇总
数据集介绍
构建方式
在泰语语体分类研究领域,Thai-Thangkarn-sentence数据集采用了先进的少样本提示技术构建而成。该数据集通过typhoon-v2-70b-instruct和OpenAI GPT 4.1两种大语言模型,围绕师生对话场景生成了42,204条合成数据。构建过程中设计了学术指导、考勤事务、作业提交、文件申请与致谢尊重五大主题,每个主题下细分十类具体情境,并通过随机代词和例句注入多样性。为确保数据均衡性,各类别标签按等比例随机分配,同时引入邮件与聊天双渠道生成机制以丰富语体特征,最终通过统一系统提示词实现标准化数据生成。
特点
该数据集最显著的特征在于其精细划分的五级泰语语体分类体系,涵盖仪式用语、正式用语、半正式用语、非正式用语及亲密用语五个维度。每条数据不仅包含原始文本和分类标签,还保留了大语言模型的生成逻辑说明,为研究提供可解释性依据。数据内容紧密贴合教育场景的实际需求,通过师生对话呈现不同语体在词汇选择、句式结构和礼貌程度上的梯度差异,其中仪式用语的礼貌程度达到100%,而亲密用语则低于25%,形成完整的语体光谱。这种多维度标注体系为泰语自然语言处理研究提供了珍贵的语料资源。
使用方法
研究人员可将该数据集直接应用于泰语文本分类模型的训练与评估,尤其适用于教育领域的语体识别任务。使用时应首先解析数据集的JSON结构,重点关注text字段的原始文本和label字段的五分类标签。模型生成过程中的推理记录可作为可解释人工智能的研究素材。鉴于数据已按主题和语体均衡分布,建议采用分层抽样方式划分训练集与测试集,以确保各类别数据的代表性。对于跨文化语体研究,可结合标签描述中的礼貌百分比指标进行对比分析,探索泰语语体与社会语境的内在关联。
背景与挑战
背景概述
Thai-Thangkarn-sentence数据集作为泰语语体分类领域的重要资源,由泰国研究团队于近期开发完成,其设计灵感源于Intel的polite-guard数据集。该数据集聚焦于泰语文本的语体层级划分,依据泰国语法规范将语料精确归类为仪式性、正式性、半正式性、非正式性及口语化五个等级。通过采用大语言模型生成合成数据,数据集覆盖了学术咨询、考勤事务、作业提交、文件申请与致谢礼仪等典型师生对话场景,共计42204条标注样本,为泰语自然语言处理中的语体分析提供了结构化数据支撑。
当前挑战
在泰语语体分类任务中,核心挑战在于如何精准捕捉不同语体间细微的语言特征差异,例如仪式性文本的严格语法结构与口语化文本的俚语混杂现象。数据构建过程中,研究团队面临合成数据质量控制的难题,尤其在生成过程中发现电子邮件与聊天渠道的文本风格边界模糊,导致部分标签下语义一致性不足。此外,为确保数据多样性而随机化代词与例句的策略,虽增强了样本丰富度,但也对生成内容的标签对齐提出了更高要求。
常用场景
经典使用场景
在泰语自然语言处理领域,Thai-Thangkarn-sentence数据集为文本分类任务提供了关键支持。该数据集通过模拟师生对话场景,涵盖了学术建议、考勤问题、提交通知、文件请求和感谢表达等五个主题,每个主题下细分为多个具体子类。这种设计使得数据集能够广泛应用于泰语礼貌级别分类研究,帮助模型识别从高度仪式化到亲密随意的五种语言风格。数据集通过少样本提示技术生成合成数据,确保了样本的多样性和均衡性,为泰语语言模型的微调和评估奠定了坚实基础。
衍生相关工作
围绕该数据集衍生的经典工作主要集中在多模态礼貌策略分析领域。研究者利用其层次化标签体系开发了联合嵌入模型,将语言风格与社交语境进行关联建模。例如,有研究将仪式化文本与典礼场景的视觉特征相结合,构建了跨模态的礼貌识别系统。另一项重要工作是通过对比学习框架,利用数据集中并行的主题内容不同风格表达,实现了泰语风格迁移模型的突破。这些研究不仅扩展了数据集的应用边界,还推动了东南亚语言处理社区对语境感知计算方法的探索。
数据集最近研究
最新研究方向
在泰语自然语言处理领域,Thai-Thangkarn-sentence数据集聚焦于泰语语体风格的精细分类研究,为语言形式化分析提供了重要支撑。当前前沿探索主要围绕大语言模型在低资源语言中的合成数据生成能力,通过Few-shot提示技术构建涵盖礼仪、正式、半正式、非正式及口语化五级语体的标注语料。热点方向涉及跨文化语境下语体迁移的自动化建模,特别是在教育对话场景中学术咨询、考勤事务等主题的风格适配性研究。该数据集推动了泰语语法规范与计算语言学的前沿交叉,对多语种社会语言智能应用具有显著意义。
以上内容由遇见数据集搜集并总结生成


