dynpose-100k
收藏魔搭社区2025-12-05 更新2025-04-26 收录
下载链接:
https://modelscope.cn/datasets/nv-community/dynpose-100k
下载链接
链接失效反馈官方服务:
资源简介:
# DynPose-100K
**[Dynamic Camera Poses and Where to Find Them](https://research.nvidia.com/labs/dir/dynpose-100k)** \
[Chris Rockwell<sup>1,2</sup>](https://crockwell.github.io), [Joseph Tung<sup>3</sup>](https://jot-jt.github.io/), [Tsung-Yi Lin<sup>1</sup>](https://tsungyilin.info/),
[Ming-Yu Liu<sup>1</sup>](https://mingyuliu.net/), [David F. Fouhey<sup>3</sup>](https://cs.nyu.edu/~fouhey/), [Chen-Hsuan Lin<sup>1</sup>](https://chenhsuanlin.bitbucket.io/) \
<sup>1</sup>NVIDIA <sup>2</sup>University of Michigan <sup>3</sup>New York University
## 🎉 Updates
- **[2025.05]** We have released the Lightspeed benchmark, a new dataset with ground-truth camera poses for validating DynPose-100K's pose annotation method. See [download instructions](#lightspeed-benchmark-download) below.
- **[2025.04]** We have made the initial release of DynPose-100K, a large-scale dataset of diverse, dynamic videos with camera annotations. See [download instructions](#dynpose-100k-download) below.
[](https://research.nvidia.com/labs/dir/dynpose-100k) [](https://arxiv.org/abs/2504.17788)

## Overview
DynPose-100K is a large-scale dataset of diverse, dynamic videos with camera annotations. We curate 100K videos containing dynamic content while ensuring cameras can be accurately estimated (including intrinsics and poses), addressing two key challenges:
1. Identifying videos suitable for camera estimation
2. Improving camera estimation algorithms for dynamic videos
| Characteristic | Value |
| --- | --- |
| **Size** | 100K videos |
| **Resolution** | 1280×720 (720p) |
| **Annotation type** | Camera poses (world-to-camera), intrinsics |
| **Format** | MP4 (videos), PKL (camera data), JPG (frames) |
| **Frame rate** | 12 fps (extracted frames) |
| **Storage** | ~200 GB (videos) + ~400 GB (frames) + 0.7 GB (annotations) |
| **License** | NVIDIA License (for DynPose-100K) |
## DynPose-100K Download
DynPose-100K contains diverse Internet videos annotated with state-of-the-art camera pose estimation. Videos were selected from 3.2M candidates through advanced filtering.
### 1. Camera annotation download (0.7 GB)
```bash
git clone https://huggingface.co/datasets/nvidia/dynpose-100k
cd dynpose-100k
unzip dynpose_100k.zip
export DYNPOSE_100K_ROOT=$(pwd)/dynpose_100k
```
### 2. Video download (~200 GB for all videos at 720p)
```bash
git clone https://github.com/snap-research/Panda-70M.git
pip install -e Panda-70M/dataset_dataloading/video2dataset
```
- For experiments we use (1280, 720) video resolution rather than the default (640, 360). To download at this resolution (optional), modify [download size](https://github.com/snap-research/Panda-70M/blob/main/dataset_dataloading/video2dataset/video2dataset/configs/panda70m.yaml#L5) to 720
```bash
video2dataset --url_list="${DYNPOSE_100K_ROOT}/metadata.csv" --output_folder="${DYNPOSE_100K_ROOT}/video" \
--url_col="url" --caption_col="caption" --clip_col="timestamp" \
--save_additional_columns="[matching_score,desirable_filtering,shot_boundary_detection]" \
--config="video2dataset/video2dataset/configs/panda70m.yaml"
```
### 3. Video frame extraction (~400 GB for 12 fps over all videos at 720p)
```bash
python scripts/extract_frames.py --input_video_dir ${DYNPOSE_100K_ROOT}/video \
--output_frame_parent ${DYNPOSE_100K_ROOT}/frames-12fps \
--url_list ${DYNPOSE_100K_ROOT}/metadata.csv \
--uid_mapping ${DYNPOSE_100K_ROOT}/uid_mapping.csv
```
### 4. Camera pose visualization
Create a conda environment if you haven't done so:
```bash
conda env create -f environment.yml
conda activate dynpose-100k
```
Run the below under the `dynpose-100k` environment:
```bash
python scripts/visualize_pose.py --dset dynpose_100k --dset_parent ${DYNPOSE_100K_ROOT}
```
### Dataset structure
```
dynpose_100k
├── cameras
| ├── 00011ee6-cbc1-4ec4-be6f-292bfa698fc6.pkl {uid}
| ├── poses {camera poses (all frames) ([N',3,4])}
| ├── intrinsics {camera intrinsic matrix ([3,3])}
| ├── frame_idxs {corresponding frame indices ([N']), values within [0,N-1]}
| ├── mean_reproj_error {average reprojection error from SfM ([N'])}
| ├── num_points {number of reprojected points ([N'])}
| ├── num_frames {number of video frames N (scalar)}
| # where N' is number of registered frames
| ├── 00031466-5496-46fa-a992-77772a118b17.pkl
| ├── poses # camera poses (all frames) ([N',3,4])
| └── ...
| └── ...
├── video
| ├── 00011ee6-cbc1-4ec4-be6f-292bfa698fc6.mp4 {uid}
| ├── 00031466-5496-46fa-a992-77772a118b17.mp4
| └── ...
├── frames-12fps
| ├── 00011ee6-cbc1-4ec4-be6f-292bfa698fc6 {uid}
| ├── 00001.jpg {frame id}
| ├── 00002.jpg
| └── ...
| ├── 00031466-5496-46fa-a992-77772a118b17
| ├── 00001.jpg
| └── ...
| └── ...
├── metadata.csv {used to download video & extract frames}
| ├── uid
| ├── 00031466-5496-46fa-a992-77772a118b17
| └── ...
├── uid_mapping.csv {used to download video & extract frames}
| ├── videoID,url,timestamp,caption,matching_score,desirable_filtering,shot_boundary_detection
| ├── --106WvnIhc,https://www.youtube.com/watch?v=--106WvnIhc,"[['0:13:34.029', '0:13:40.035']]",['A man is swimming in a pool with an inflatable mattress.'],[0.44287109375],['desirable'],"[[['0:00:00.000', '0:00:05.989']]]"
| └── ...
├── viz_list.txt {used as index for pose visualization}
| ├── 004cd3b5-8af4-4613-97a0-c51363d80c31 {uid}
| ├── 0c3e06ae-0d0e-4c41-999a-058b4ea6a831
| └── ...
```
## Lightspeed Benchmark Download
Lightspeed is a challenging, photorealistic benchmark for dynamic pose estimation with **ground-truth** camera poses. It is used to validate DynPose-100K's pose annotation method.
Original video clips can be found here: https://www.youtube.com/watch?v=AsykNkUMoNU&t=1s
### 1. Downloading cameras, videos and frames (8.1 GB)
```bash
git clone https://huggingface.co/datasets/nvidia/dynpose-100k
cd dynpose-100k
unzip lightspeed.zip
export LIGHTSPEED_PARENT=$(pwd)/lightspeed
```
### 2. Dataset structure
```
lightspeed
├── poses.pkl
| ├── 0120_LOFT {id_setting}
| ├── poses {camera poses (all frames) ([N,3,4])}
| # where N is number of frames
| ├── 0180_DUST
| ├── poses {camera poses (all frames) ([N,3,4])}
| └── ...
├── video
| ├── 0120_LOFT.mp4 {id_setting}
| ├── 0180_DUST.mp4
| └── ...
├── frames-24fps
| ├── 0120_LOFT/images {id_setting}
| ├── 00000.png {frame id}
| ├── 00001.png
| └── ...
| ├── 0180_DUST/images
| ├── 00000.png
| └── ...
| └── ...
├── viz_list.txt {used as index for pose visualization}
| ├── 0120_LOFT.mp4 {id_setting}
| ├── 0180_DUST.mp4
| └── ...
```
### 3. Camera pose visualization
Create a conda environment if you haven't done so:
```bash
conda env create -f environment.yml
conda activate dynpose-100k
```
Run the below under the `dynpose-100k` environment:
```bash
python scripts/visualize_pose.py --dset lightspeed --dset_parent ${LIGHTSPEED_PARENT}
```
## FAQ
**Q: What coordinate system do the camera poses use?**
A: Camera poses are world-to-camera and follow OpenCV "RDF" convention (same as COLMAP): X axis points to the right, the Y axis to the bottom, and the Z axis to the front as seen from the image.
**Q: How do I map between frame indices and camera poses?**
A: The `frame_idxs` field in each camera PKL file contains the corresponding frame indices for the poses.
**Q: How can I contribute to this dataset?**
A: Please contact the authors for collaboration opportunities.
## Citation
If you find this dataset useful in your research, please cite our paper:
```bibtex
@inproceedings{rockwell2025dynpose,
author = {Rockwell, Chris and Tung, Joseph and Lin, Tsung-Yi and Liu, Ming-Yu and Fouhey, David F. and Lin, Chen-Hsuan},
title = {Dynamic Camera Poses and Where to Find Them},
booktitle = {CVPR},
year = 2025
}
```
## Acknowledgements
We thank Gabriele Leone and the NVIDIA Lightspeed Content Tech team for sharing the original 3D assets and scene data for creating the Lightspeed benchmark. We thank Yunhao Ge, Zekun Hao, Yin Cui, Xiaohui Zeng, Zhaoshuo Li, Hanzi Mao, Jiahui Huang, Justin Johnson, JJ Park and Andrew Owens for invaluable inspirations, discussions and feedback on this project.
# DynPose-100K
**[动态相机位姿及其获取方法](https://research.nvidia.com/labs/dir/dynpose-100k)**
[克里斯·罗克韦尔<sup>1,2</sup>](https://crockwell.github.io), [约瑟夫·滕<sup>3</sup>](https://jot-jt.github.io/), [林宗毅<sup>1</sup>](https://tsungyilin.info/),
[刘明宇<sup>1</sup>](https://mingyuliu.net/), [大卫·F·福伊<sup>3</sup>](https://cs.nyu.edu/~fouhey/), [林辰轩<sup>1</sup>](https://chenhsuanlin.bitbucket.io/)
<sup>1</sup>英伟达 <sup>2</sup>密歇根大学 <sup>3</sup>纽约大学
## 🎉 更新
- **[2025.05]** 我们发布了Lightspeed基准测试集,这是一个带有真实标注(ground-truth)相机位姿的全新数据集,用于验证DynPose-100K的位姿标注方法。详见下文的[下载说明](#lightspeed-benchmark-download)。
- **[2025.04]** 我们首次发布了DynPose-100K,这是一个包含多样动态视频与相机标注的大规模数据集。详见下文的[下载说明](#dynpose-100k-download)。
[](https://research.nvidia.com/labs/dir/dynpose-100k) [](https://arxiv.org/abs/2504.17788)

## 概述
DynPose-100K是一个包含多样动态视频与相机标注的大规模数据集。我们从动态内容中精选了10万条视频,并确保可精准估算相机参数(包括内参与位姿),该数据集解决了两大核心挑战:
1. 筛选适用于相机参数估算的视频
2. 优化针对动态视频的相机参数估算算法
| 数据集属性 | 参数值 |
| --- | --- |
| **规模** | 10万条视频 |
| **分辨率** | 1280×720(720p) |
| **标注类型** | 相机位姿(世界坐标系到相机坐标系变换)、内参 |
| **文件格式** | MP4(视频)、PKL(相机数据)、JPG(帧图像) |
| **帧率** | 12 fps(提取的帧图像) |
| **存储占用** | 约200 GB(视频) + 约400 GB(帧图像) + 0.7 GB(标注数据) |
| **授权协议** | 英伟达授权协议(DynPose-100K) |
## DynPose-100K 下载
DynPose-100K包含经先进相机位姿估算模型标注的多样互联网视频,其视频来源为320万条候选视频,经过严格筛选得到。
### 1. 相机标注数据下载(0.7 GB)
bash
git clone https://huggingface.co/datasets/nvidia/dynpose-100k
cd dynpose-100k
unzip dynpose_100k.zip
export DYNPOSE_100K_ROOT=$(pwd)/dynpose_100k
### 2. 视频下载(720p全量视频约200 GB)
bash
git clone https://github.com/snap-research/Panda-70M.git
pip install -e Panda-70M/dataset_dataloading/video2dataset
- 实验中我们采用(1280, 720)分辨率而非默认的(640, 360)。若需按该分辨率下载(可选),请将[下载配置](https://github.com/snap-research/Panda-70M/blob/main/dataset_dataloading/video2dataset/video2dataset/configs/panda70m.yaml#L5)中的尺寸修改为720
bash
video2dataset --url_list="${DYNPOSE_100K_ROOT}/metadata.csv" --output_folder="${DYNPOSE_100K_ROOT}/video"
--url_col="url" --caption_col="caption" --clip_col="timestamp"
--save_additional_columns="[matching_score,desirable_filtering,shot_boundary_detection]"
--config="video2dataset/video2dataset/configs/panda70m.yaml"
### 3. 视频帧提取(720p全量视频按12 fps提取,约400 GB)
bash
python scripts/extract_frames.py --input_video_dir ${DYNPOSE_100K_ROOT}/video
--output_frame_parent ${DYNPOSE_100K_ROOT}/frames-12fps
--url_list ${DYNPOSE_100K_ROOT}/metadata.csv
--uid_mapping ${DYNPOSE_100K_ROOT}/uid_mapping.csv
### 4. 相机位姿可视化
若尚未创建conda环境,请先执行以下命令创建:
bash
conda env create -f environment.yml
conda activate dynpose-100k
在`dynpose-100k`环境中运行以下命令:
bash
python scripts/visualize_pose.py --dset dynpose_100k --dset_parent ${DYNPOSE_100K_ROOT}
### 数据集目录结构
dynpose_100k
├── cameras
| ├── 00011ee6-cbc1-4ec4-be6f-292bfa698fc6.pkl {唯一标识符uid}
| ├── poses {所有帧的相机位姿 ([N',3,4])}
| ├── intrinsics {相机内参矩阵 ([3,3])}
| ├── frame_idxs {对应帧索引 ([N']), 取值范围为[0,N-1]}
| ├── mean_reproj_error {基于运动恢复结构(Structure from Motion,SfM)的平均重投影误差 ([N'])}
| ├── num_points {每个位姿对应的重投影点数量 ([N'])}
| ├── num_frames {视频总帧数N(标量)}
| # 其中N'为已配准的帧数
| ├── 00031466-5496-46fa-a992-77772a118b17.pkl
| ├── poses # 所有帧的相机位姿 ([N',3,4])
| └── ...
| └── ...
├── video
| ├── 00011ee6-cbc1-4ec4-be6f-292bfa698fc6.mp4 {唯一标识符uid}
| ├── 00031466-5496-46fa-a992-77772a118b17.mp4
| └── ...
├── frames-12fps
| ├── 00011ee6-cbc1-4ec4-be6f-292bfa698fc6 {唯一标识符uid}
| ├── 00001.jpg {帧ID}
| ├── 00002.jpg
| └── ...
| ├── 00031466-5496-46fa-a992-77772a118b17
| ├── 00001.jpg
| └── ...
| └── ...
├── metadata.csv {用于下载视频与提取帧的元数据文件}
| ├── uid
| ├── 00031466-5496-46fa-a992-77772a118b17
| └── ...
├── uid_mapping.csv {用于下载视频与提取帧的映射文件}
| ├── videoID,url,timestamp,caption,matching_score,desirable_filtering,shot_boundary_detection
| ├── --106WvnIhc,https://www.youtube.com/watch?v=--106WvnIhc,"[['0:13:34.029', '0:13:40.035']]",["A man is swimming in a pool with an inflatable mattress."],[0.44287109375],["desirable"]],"[[['0:00:00.000', '0:00:05.989']]]"
| └── ...
├── viz_list.txt {用于位姿可视化的索引文件}
| ├── 004cd3b5-8af4-4613-97a0-c51363d80c31 {唯一标识符uid}
| ├── 0c3e06ae-0d0e-4c41-999a-058b4ea6a831
| └── ...
## Lightspeed 基准测试集下载
Lightspeed是一个用于动态相机位姿估算的高难度、照片级真实感基准测试集,带有真实标注(ground-truth)的相机位姿,用于验证DynPose-100K的位姿标注方法。原始视频片段可在此处获取:https://www.youtube.com/watch?v=AsykNkUMoNU&t=1s
### 1. 下载相机、视频与帧数据(8.1 GB)
bash
git clone https://huggingface.co/datasets/nvidia/dynpose-100k
cd dynpose-100k
unzip lightspeed.zip
export LIGHTSPEED_PARENT=$(pwd)/lightspeed
### 2. 数据集目录结构
lightspeed
├── poses.pkl
| ├── 0120_LOFT {场景设置ID}
| ├── poses {所有帧的相机位姿 ([N,3,4])}
| # 其中N为总帧数
| ├── 0180_DUST
| ├── poses {所有帧的相机位姿 ([N,3,4])}
| └── ...
├── video
| ├── 0120_LOFT.mp4 {场景设置ID}
| ├── 0180_DUST.mp4
| └── ...
├── frames-24fps
| ├── 0120_LOFT/images {场景设置ID}
| ├── 00000.png {帧ID}
| ├── 00001.png
| └── ...
| ├── 0180_DUST/images
| ├── 00000.png
| └── ...
| └── ...
├── viz_list.txt {用于位姿可视化的索引文件}
| ├── 0120_LOFT.mp4 {场景设置ID}
| ├── 0180_DUST.mp4
| └── ...
### 3. 相机位姿可视化
若尚未创建conda环境,请先执行以下命令创建:
bash
conda env create -f environment.yml
conda activate dynpose-100k
在`dynpose-100k`环境中运行以下命令:
bash
python scripts/visualize_pose.py --dset lightspeed --dset_parent ${LIGHTSPEED_PARENT}
## 常见问题(FAQ)
**Q: 相机位姿采用何种坐标系?**
**A: 相机位姿为世界坐标系到相机坐标系的变换,遵循OpenCV的「RDF」约定(与COLMAP一致):从图像视角出发,X轴指向右侧,Y轴指向下方,Z轴指向前方。**
**Q: 如何将帧索引与相机位姿进行映射?**
**A: 每个相机PKL文件中的`frame_idxs`字段包含了位姿对应的帧索引。**
**Q: 如何为该数据集贡献内容?**
**A: 请联系作者获取合作机会。**
## 引用格式
若您在研究中使用该数据集,请引用我们的论文:
bibtex
@inproceedings{rockwell2025dynpose,
author = {Rockwell, Chris and Tung, Joseph and Lin, Tsung-Yi and Liu, Ming-Yu and Fouhey, David F. and Lin, Chen-Hsuan},
title = {Dynamic Camera Poses and Where to Find Them},
booktitle = {CVPR},
year = 2025
}
## 致谢
我们感谢Gabriele Leone与英伟达Lightspeed内容技术团队分享原始3D资产与场景数据,用于构建Lightspeed基准测试集。我们感谢Yunhao Ge、Zekun Hao、Yin Cui、Xiaohui Zeng、Zhaoshuo Li、Hanzi Mao、Jiahui Huang、Justin Johnson、JJ Park与Andrew Owens为本项目提供的宝贵灵感、讨论与反馈。
提供机构:
maas
创建时间:
2025-04-25
搜集汇总
数据集介绍
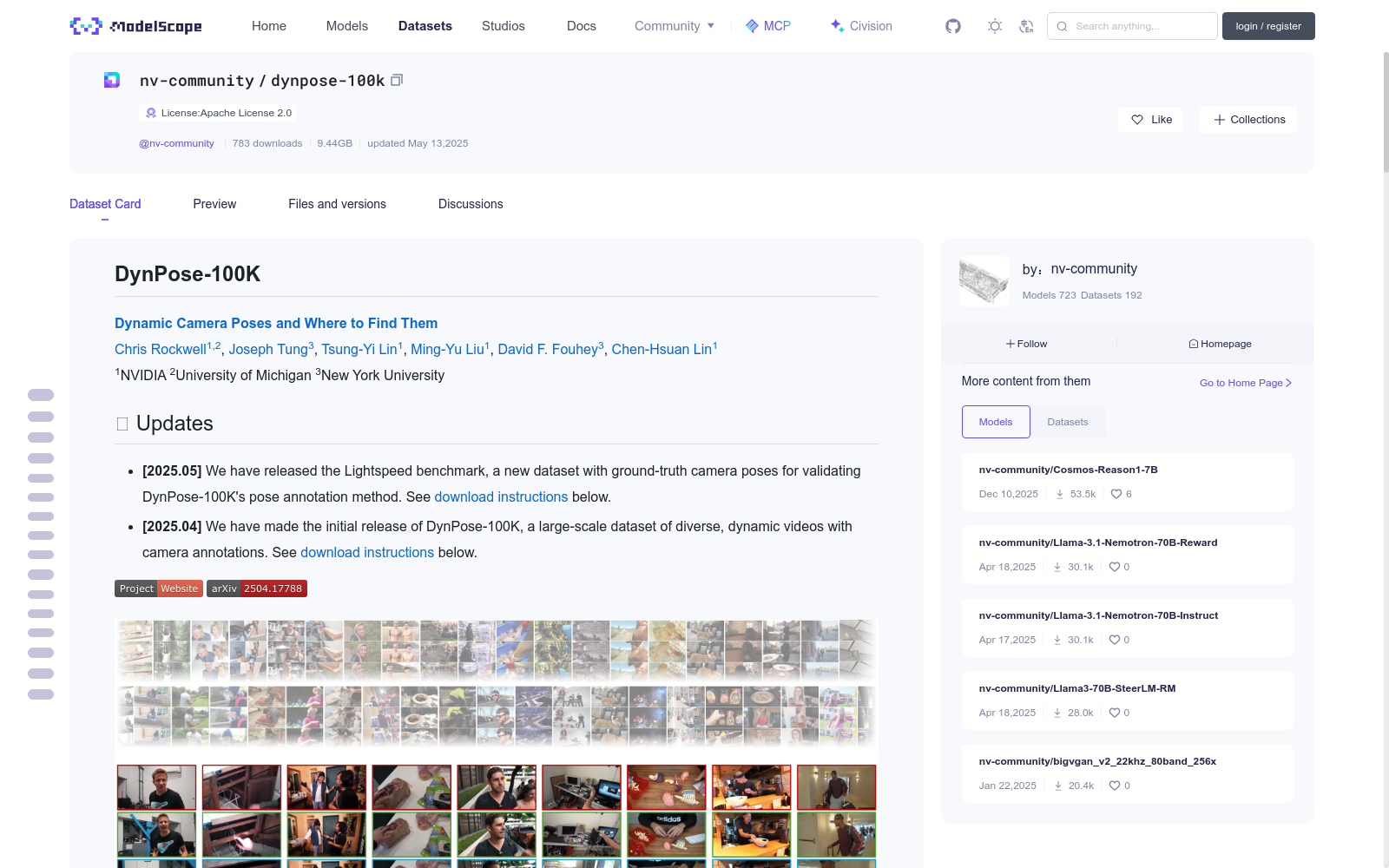
背景与挑战
背景概述
DynPose-100K是一个包含10万段动态视频的大规模数据集,每段视频均标注了相机姿态和内参,旨在解决动态视频中相机估计的挑战。数据集提供了视频、帧和相机标注的详细下载和处理流程,适用于计算机视觉和图形学研究。
以上内容由遇见数据集搜集并总结生成


