cs2_dataset_render
收藏Hugging Face2026-04-30 更新2026-05-01 收录
下载链接:
https://huggingface.co/datasets/blanchon/cs2_dataset_render
下载链接
链接失效反馈官方服务:
资源简介:
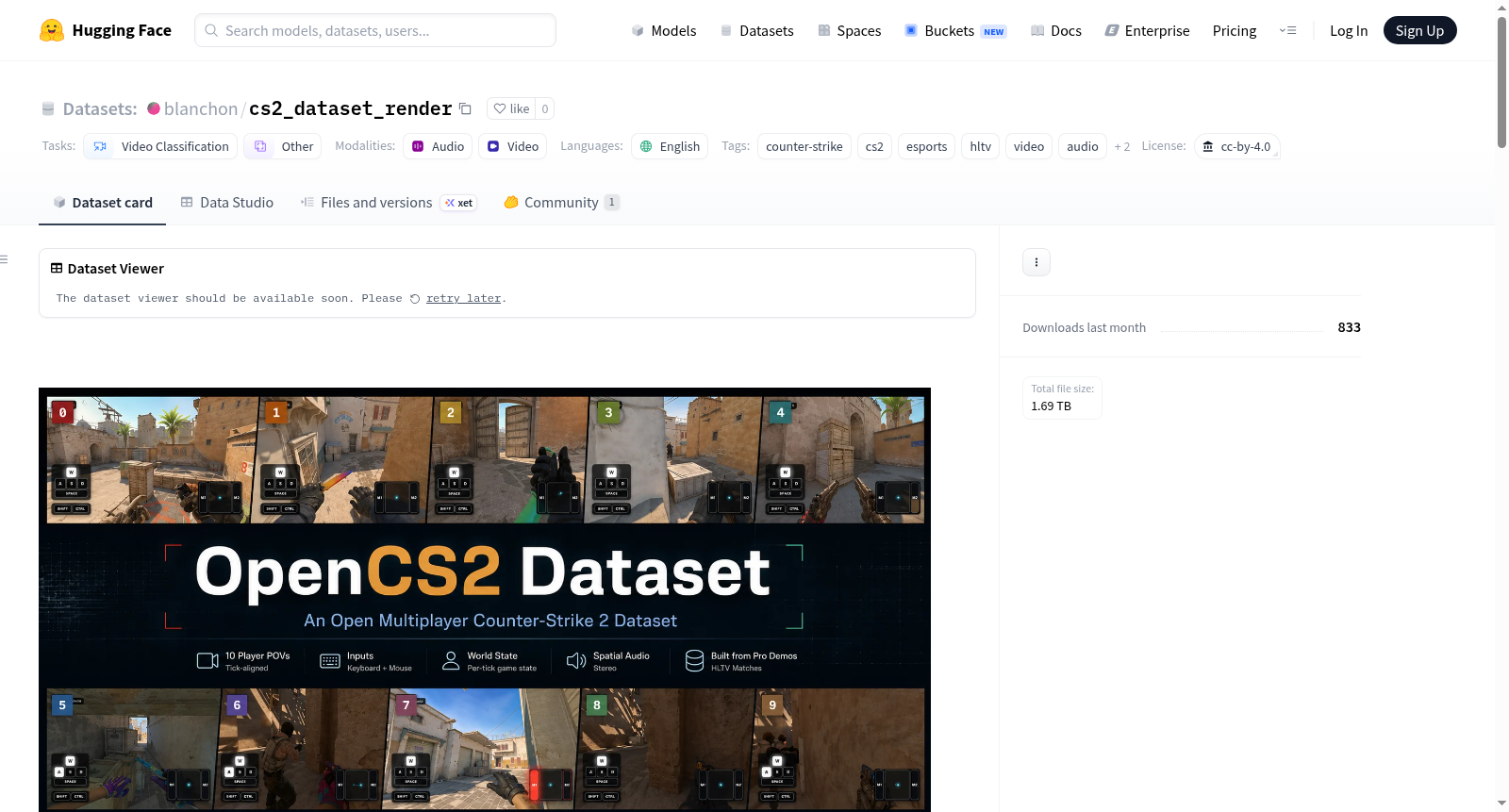
OpenCS2 — POV Renders 是一个专注于《反恐精英2》(Counter-Strike 2)第一人称视角(POV)训练片段的数据集。每个数据行包含≤1分钟的一名玩家的视角,每回合的10个玩家视角共享相同的时间轴。数据集包含以下内容:视频(1280×720分辨率,32帧/秒,近乎无损的H.264编码)、音频(每个玩家的立体声音频,根据其位置和方向混合)、输入(每个时间点的按键、鼠标移动、视角角度、开火/跳跃/使用动作、武器切换等)和世界状态(每个时间点所有10名玩家的位置、速度、视角、生命值、护甲、武器、存活状态等)。数据集提供四种配置:`previews`(默认,低分辨率预览)、`chunks`(完整的训练数据)、`matches`(比赛元数据)和`rounds`(回合元数据)。适用于视频分类、强化学习等任务。数据集使用CC-BY-4.0许可证,源数据受原始比赛条款约束。
OpenCS2 — POV Renders is a dataset focused on first-person perspective (POV) training clips of Counter-Strike 2. Each data row contains ≤1 minute of a players perspective, with all 10 player perspectives per round sharing the same timeline. The dataset includes the following: video (1280×720 resolution, 32 FPS, near-lossless H.264 encoding), audio (stereo audio for each player, mixed according to their position and orientation), input (key presses, mouse movements, view angles, fire/jump/use actions, weapon switches at each time point), and world state (position, velocity, view angles, health, armor, weapons, alive status of all 10 players at each time point). The dataset offers four configurations: `previews` (default, low-resolution previews), `chunks` (complete training data), `matches` (match metadata), and `rounds` (round metadata). Suitable for tasks like video classification and reinforcement learning. The dataset uses the CC-BY-4.0 license, with source data subject to original match terms.
创建时间:
2026-04-28
原始信息汇总
OpenCS2 — POV Renders 数据集概述
基本信息
- 许可证: CC-BY-4.0
- 任务类型: 视频分类、其他
- 语言: 英语
- 标签: Counter-Strike, CS2, 电子竞技, HLTV, 视频, 音频, Parquet, 强化学习
- 数据集名称: OpenCS2 — POV Renders
数据集描述
该数据集包含基于 ticks 对齐的《反恐精英2》(CS2)第一人称视角(POV)训练片段,源自 blanchon/cs2_dataset_demo 数据集。每一行数据代表一名玩家视角中不超过1分钟的视频片段;每局比赛(round)中10名玩家的POV共享同一 tick 时钟。
每个数据块包含
- 视频: 1280×720 分辨率,32 fps,近无损 H.264 编码
- 音频: 每名玩家的立体声,根据该玩家的位置和朝向混合
- 输入: 每个 tick 记录:按键、鼠标移动、视角角度、开火/跳跃/使用、武器切换
- 世界状态: 每个 tick 记录所有10名玩家的位置、速度、视角、生命值、护甲、武器、存活状态
配置与数据划分
| 配置名称 | 说明 | 用途 |
|---|---|---|
previews(默认) |
低分辨率 preview.mp4 + 1 Hz 输入/世界侧数据 |
浏览、快速检查 |
chunks |
仅包含路径的 video.mp4 + audio.wav,嵌入输入/世界数据 |
训练 |
matches |
每行对应一个 (match_id, map_name),包含队伍/赛事元数据 |
筛选/索引 |
rounds |
每行对应一个 (match_id, map_name, round),包含 tick 边界 |
筛选/索引 |
数据仓库结构
data/ match_id=<id>/map_name=<map>/player=<0-9>/ chunks-preview-<machine>-<uuid>.parquet chunks-full-<machine>-<uuid>.parquet chunks/chunk_<n>/{video.mp4, audio.wav} previews/chunk_<n>/{preview.mp4, inputs.preview.json, world.preview.jsonl} index/ manifest-<machine>-<uuid>.parquet # 每行对应一个 (match, map) rounds-<machine>-<uuid>.parquet # 每行对应一个 (match, map, round)
行语义
player: 规范化的0-9玩家索引,对于同一场比赛保持稳定spec_slot: 临时的 CS2 观众位编号,仅用于调试- 录制从可玩回合开始(
freeze_end_tick)开始,在玩家死亡 tick 处停止,幸存者则在回合结束时停止。同一局中不同POV的时长可能不同 inputs和worlds在 chunks parquet 中是结构体数组格式- 可用于
chunks的热门筛选列:match_id,map_name,player,round,chunk_index,primary_weapon,player_side,survived_chunk,damage_taken,shots_fired,distance_traveled,weapons_used
数据创建流程
- Demo文件: 从
blanchon/cs2_dataset_demo拉取 - 渲染: 使用无头 CS2 + 自定义插件回放每个 demo,逐 tick 捕获每名玩家的POV,并将原始帧流式传输到 NVENC
- Parquet: 将小于等于1分钟的块按
(round, chunk_index)排序写入 - 上传: 每个渲染工作线程写入自己的
<machine>-<uuid>分片
引用
bibtex @misc{blanchon2026opencs2, author = {Julien Blanchon}, title = {OpenCS2 Dataset}, year = {2026}, publisher = {Hugging Face}, howpublished = {url{https://github.com/julien-blanchon/opencs2-dataset}} }
搜集汇总
数据集介绍
构建方式
该数据集通过一套精心设计的渲染管线构建而成,其源头为HLTV平台收录的职业比赛Demo,主要存储于`cs2_dataset_demo`数据集中。构建过程首先通过定制的无头CS2客户端与插件,逐Tick重放比赛录像,从全部十名选手的第一人称视角捕获原始帧流,并利用NVENC编码器进行近乎无损的H.264压缩。随后,将每名选手视角的连续片段按不超过一分钟的时长切分为数据块,并嵌入对应的按键输入、鼠标操作、视角变化等指令信息,以及包含全部玩家位置、速度、生命值等属性的全局世界状态。最终,所有数据以Parquet格式存储,并通过Xet技术实现高效的增量上传,确保数据一致性与低带宽消耗。
特点
该数据集最为显著的特征在于其严格的时间同步与视角完备性。在一个回合内,十名选手的第一人称视频、音频及操作数据均共享同一Tick时钟基准,实现了像素级与输入级的精确对齐,这对于多智能体模仿学习与因果推断研究至关重要。视频规格为1280×720分辨率、32帧每秒,并伴有根据玩家位置与朝向混合的立体声音频。此外,数据集提供了丰富的过滤列,如主武器类型、存活状态、造成伤害等,使得研究者能够便捷地筛选出特定情境下的游戏片段,如狙击枪操作或残局处理,极大提升了数据检索的灵活性与针对性。
使用方法
数据集提供了四种配置以适配不同使用场景。默认的`previews`配置适用于快速浏览与数据校验,包含低分辨率预览视频与低频采样的输入/状态侧车文件。训练场景应选用`chunks`配置,该配置包含完整的高清视频与音频文件,并将输入与状态数据内嵌于Parquet文件中。用户可通过Hugging Face `datasets`库流式加载数据,并利用`filters`参数在加载时即完成列筛选,例如仅加载特定选手或武器类型的数据。高级用户亦可借助DuckDB直接查询Parquet文件的索引与数据块,或通过`hf` CLI工具结合Hive分区路径对单个比赛、地图或选手的数据进行精准的部分下载,从而实现高效的存储与计算资源利用。
背景与挑战
背景概述
OpenCS2数据集(cs2_dataset_render)由Julien Blanchon于2026年创建,旨在为强化学习与视频分类研究提供高质量的《反恐精英2》第一人称视角训练数据。该数据集基于HLTV职业比赛回放,通过定制化渲染管线将每局比赛10名玩家的视角同步为1280×720@32fps的视频片段,并附带逐Tick的输入指令与世界状态信息。其核心研究问题在于弥合高动态电子竞技环境与机器学习模型之间的数据鸿沟,为智能体训练、比赛分析及视频理解提供标准化基准。作为一个开放资源,OpenCS2采用CC-BY-4.0许可,对电子竞技AI领域产生了深远影响,推动了从环境建模到策略推理的多项研究工作。
当前挑战
构建OpenCS2面临的双重挑战:首先,电子竞技领域缺乏同步多视角的高保真数据集,现有方案往往牺牲时空一致性或忽略输入输出细节,难以支撑细粒度的强化学习任务;其次,渲染流水线需处理每局比赛10路POV的实时捕获与编码,包括头戴式CS2插件的无头渲染、NVENC硬件编码的流式传输、以及按Tick对齐的Parquet分块存储,同时确保百万级片段的上传效率与可复现性。此外,数据索引的分区策略需兼顾不同查询模式,如按比赛、地图或玩家过滤,这对元数据设计与分布式存储提出了严苛要求。
常用场景
经典使用场景
在电子竞技与计算机视觉交叉研究领域,cs2_dataset_render 数据集为多视角游戏视频理解提供了标准化基准。其最经典的使用场景是面向第一人称射击游戏(FPS)的智能体训练与行为分析,研究者可借助十名玩家同步的32帧/秒视频、音频、按键输入及完整世界状态,开发能够感知游戏进程、预测玩家行动或学习战术策略的深度学习模型。数据集精心设计了预览与完整块两种配置,既支持快速浏览与数据质量校验,又为大规模训练提供了丰富的多维特征,是探索FPS游戏中视觉、听觉与交互信号融合建模的理想起点。
实际应用
在产业界,cs2_dataset_render 数据集为电子竞技分析平台与游戏辅助系统提供了核心技术支撑。实际应用中,分析团队可利用多视角视频与元数据生成自动化的赛事复盘工具,为教练和选手提供包含每位玩家视角、战术节点与微观操作的深度回放分析。游戏开发商可借助该数据集训练能够模拟真实玩家行为的非玩家角色(NPC),提升人工智能对手的智能程度与训练价值。此外,视频内容创作平台能够基于该数据集开发自动集锦生成、精彩镜头识别等功能,极大地提高了赛事直播与赛后内容的制作效率。
衍生相关工作
基于cs2_dataset_render 数据集,学界与工业界已经衍生出一系列具有代表性的研究工作。在强化学习领域,研究人员利用同步的多智能体轨迹构建了面向团队合作的稀疏奖励学习框架,使得AI智能体能够自主学会烟雾弹战术协同与火力掩护等高阶策略。在计算机视觉方向,开发者提出了基于对比学习的多视角行为识别模型,能够仅通过单一玩家视角解码整支队伍的战术意图。此外,该数据集还催生了面向FPS游戏的时序动作分割基准与事件预测挑战,并引出了一系列关于游戏沉浸式回放与自动化解说生成的前沿探索。
以上内容由遇见数据集搜集并总结生成


