QuangDuy/mmarco-vi-hard-negatives
收藏Hugging Face2026-04-11 更新2026-04-12 收录
下载链接:
https://hf-mirror.com/datasets/QuangDuy/mmarco-vi-hard-negatives
下载链接
链接失效反馈官方服务:
资源简介:
---
language:
- vi
license: apache-2.0
task_categories:
- text-retrieval
pretty_name: Vietnamese mMARCO Hard Negatives
size_categories:
- 1M<n<10M
configs:
- config_name: default
data_files:
- split: train
path: data/train/*.parquet
- config_name: bm25_rank10_50_2neg_1m
data_files:
- split: train
path: data/bm25_rank10_50_2neg_1m/train/*.parquet
- config_name: bm25_rank1_10_1m
data_files:
- split: train
path: data/bm25_rank1_10_1m/train/*.parquet
---
# Vietnamese mMARCO Hard Negatives
This dataset is a Vietnamese triplet dataset for dense retrieval training.
It combines Vietnamese text from `unicamp-dl/mmarco` with hard-negative passage ids from `sentence-transformers/msmarco-hard-negatives`.
## Available Configs
| config | rows | neg source | sampling | rank window |
| --- | ---: | --- | --- | --- |
| `default` | 532,743 | bm25 | 1 per positive | 10-50 |
| `bm25_rank10_50_2neg_1m` | 1,000,000 | bm25 | 2 per positive | 10-50 |
| `bm25_rank1_10_1m` | 1,000,000 | bm25 | 2 per positive | 1-10 |
## Repository
- Hub repo: `QuangDuy/mmarco-vi-hard-negatives`
- splits: `train`
- configs: `3`
## Columns
- `query`: Vietnamese query text
- `positive`: Vietnamese positive passage text
- `negative`: Vietnamese hard-negative passage text
- `qid`: original MSMARCO query id
- `pos_pid`: original MSMARCO positive passage id
- `neg_pid`: original MSMARCO negative passage id
- `neg_source`: source retriever used to mine the hard negative
- `neg_rank`: 1-based rank of the selected negative inside the upstream candidate list
## How It Was Built
1. Stream the upstream hard-negative metadata and choose deterministic negatives from the configured retriever pool.
2. Collect only the Vietnamese query ids and passage ids needed for the selected triplets.
3. Stream the Vietnamese mMARCO query and collection files and extract the required text.
4. Join ids back into text triplets and write Parquet shards for Hub-native loading.
## Usage
```python
from datasets import load_dataset
dataset = load_dataset("QuangDuy/mmarco-vi-hard-negatives")
print(dataset["train"][0])
dataset = load_dataset("QuangDuy/mmarco-vi-hard-negatives", "bm25_rank10_50_2neg_1m")
print(dataset["train"][0])
dataset = load_dataset("QuangDuy/mmarco-vi-hard-negatives", "bm25_rank1_10_1m")
print(dataset["train"][0])
```
## Provenance
- Vietnamese text source: `unicamp-dl/mmarco`
- Hard-negative ids source: `sentence-transformers/msmarco-hard-negatives`
This repository republishes derived triplets. Please review the upstream dataset cards and licenses before using the data in production or redistribution-sensitive settings.
## Build Statistics
### `default`
- rows: `532,743`
- parquet shards: `22`
- negative source: `bm25`
- negatives per positive: `1`
- preferred rank window: `10` to `50`
- seed: `42`
- selected metadata rows: `532,743`
- extracted queries: `502,931`
- extracted passages: `941,468`
- build seconds: `1,702.56`
### `bm25_rank10_50_2neg_1m`
- rows: `1,000,000`
- parquet shards: `40`
- negative source: `bm25`
- negatives per positive: `2`
- preferred rank window: `10` to `50`
- seed: `42`
- selected metadata rows: `1,000,000`
- extracted queries: `471,977`
- extracted passages: `1,232,544`
- build seconds: `1,569.63`
### `bm25_rank1_10_1m`
- rows: `1,000,000`
- parquet shards: `40`
- negative source: `bm25`
- negatives per positive: `2`
- preferred rank window: `1` to `10`
- seed: `42`
- selected metadata rows: `1,000,000`
- extracted queries: `471,977`
- extracted passages: `1,210,442`
- build seconds: `2,551.79`
## Citation
If you use this dataset, please cite the upstream sources:
```bibtex
@article{DBLP:journals/corr/abs-2108-13897,
author = {Luiz Bonifacio and
Israel Campiotti and
Roberto de Alencar Lotufo and
Rodrigo Frassetto Nogueira},
title = {mMARCO: A Multilingual Version of MS MARCO Passage Ranking Dataset},
journal = {CoRR},
volume = {abs/2108.13897},
year = {2021},
url = {https://arxiv.org/abs/2108.13897}
}
```
提供机构:
QuangDuy
搜集汇总
数据集介绍
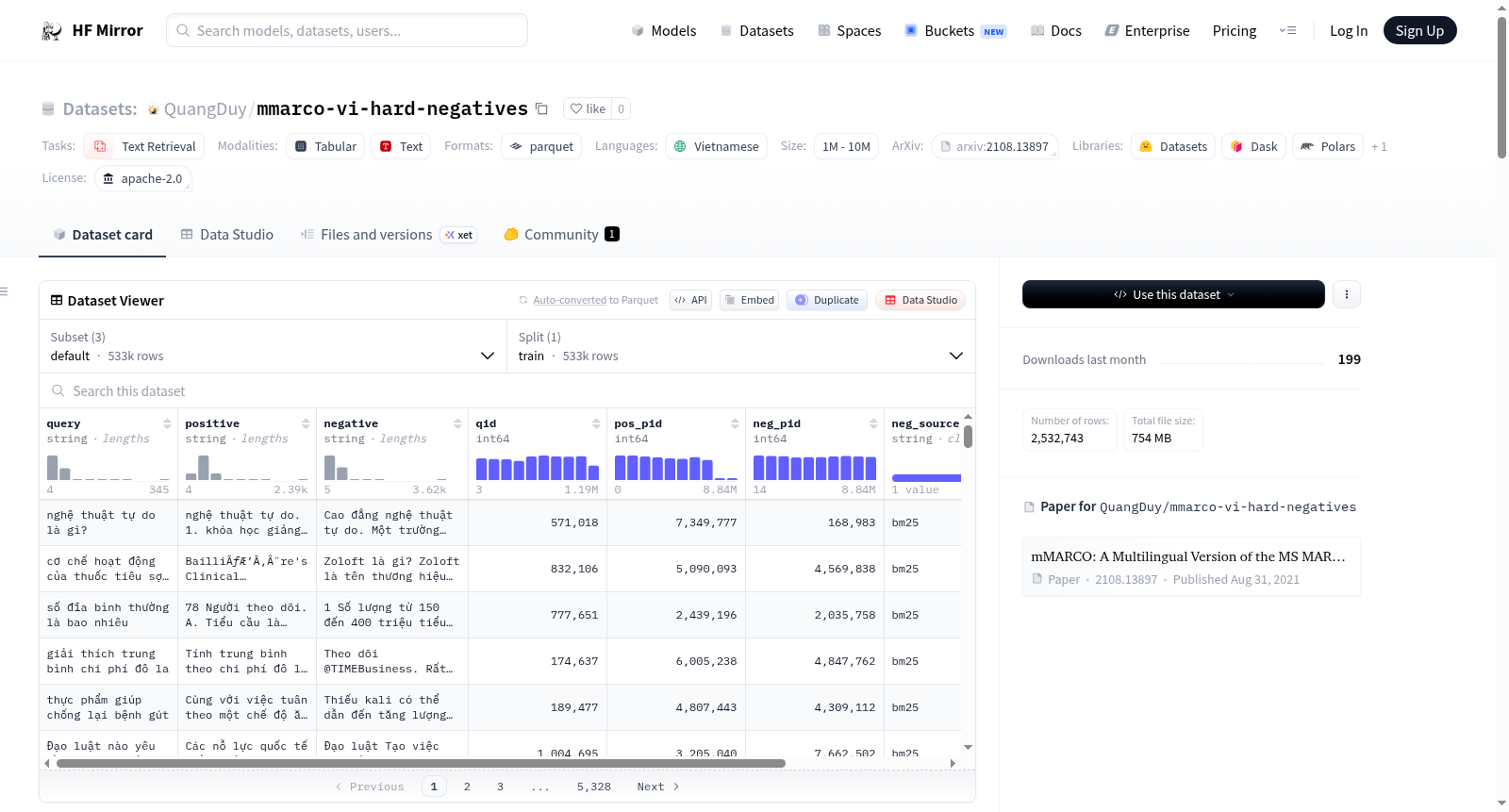
构建方式
在跨语言信息检索领域,构建高质量的训练数据对提升稠密检索模型性能至关重要。mmarco-vi-hard-negatives数据集通过整合unicamp-dl/mmarco中的越南语文本与sentence-transformers/msmarco-hard-negatives提供的困难负例标识符,采用系统化流程构建而成。具体而言,首先从上游元数据流中筛选基于BM25检索器确定的负例,随后收集越南语查询与段落标识符,再从越南语mMARCO源文件中提取对应文本,最终将标识符与文本融合生成三元组数据并以Parquet分片格式存储,确保数据加载的高效性与一致性。
特点
该数据集专为越南语稠密检索训练设计,其核心特征体现在多配置的困难负例采样策略上。通过提供三种不同配置,包括默认配置及两种基于BM25排名窗口的变体,每种配置在负例数量、排名区间和采样密度上各有侧重,例如bm25_rank1_10_1m配置聚焦于排名前10的高竞争性负例。数据集规模介于百万至千万级别,涵盖丰富的查询与段落文本,并完整保留原始MSMARCO标识符及负例来源信息,为模型训练提供了层次化的挑战性样本。
使用方法
为便于研究人员快速开展实验,该数据集可通过Hugging Face的datasets库直接加载。用户只需调用load_dataset函数并指定数据集名称及可选配置参数,即可访问不同版本的三元组数据。加载后的数据以结构化形式呈现,包含查询、正例段落、困难负例段落及其元数据字段,支持即时迭代与批量处理。这种集成化访问方式显著降低了数据预处理负担,使开发者能专注于模型优化与评估工作。
背景与挑战
背景概述
在信息检索领域,跨语言密集检索模型的训练需要高质量的多语言三元组数据集。mmarco-vi-hard-negatives数据集应运而生,由研究者QuangDuy于近年构建,其核心研究问题聚焦于为越南语密集检索任务提供包含困难负例的训练样本。该数据集基于unicamp-dl/mmarco的越南语文本与sentence-transformers/msmarco-hard-negatives的困难负例标识符整合而成,旨在提升模型在越南语语境下区分相关与不相关文档的能力。作为多语言MS MARCO数据集的重要衍生资源,它不仅推动了越南语信息检索技术的发展,也为低资源语言的检索模型训练提供了关键数据支撑。
当前挑战
该数据集致力于解决越南语密集检索中模型难以区分语义相近文档的挑战,通过引入困难负例来增强模型的判别能力。然而,构建过程中面临多重挑战:其一,从上游数据源筛选并确定性地提取困难负例需要精细的元数据处理与对齐策略,以确保负例的质量与多样性;其二,将越南语查询与文档标识符重新整合为文本三元组时,需高效处理大规模数据流并保持文本一致性,这对计算资源与工程实现提出了较高要求。此外,如何平衡不同排名窗口的负例采样策略,以优化模型训练效果,亦是数据集构建中的关键考量。
常用场景
经典使用场景
在跨语言信息检索领域,越南语密集检索模型的训练常面临高质量负样本稀缺的挑战。mmarco-vi-hard-negatives数据集通过整合越南语mMARCO文本与硬负例段落,构建了结构化的查询-正例-负例三元组,为模型提供了具有区分度的训练样本。该数据集支持多种配置,允许研究者根据需求选择不同排名窗口的负例,从而优化模型在复杂语义匹配任务中的判别能力。
衍生相关工作
该数据集的构建方法启发了后续多语言硬负例挖掘研究,如扩展至其他低资源语言的检索数据集构建。相关经典工作包括基于mMARCO框架的跨语言检索模型优化,以及结合硬负例训练的稠密检索器(如DPR、ANCE等)在越南语任务上的适应性改进。这些工作进一步推动了稀疏-稠密混合检索范式在非英语语种中的实践与应用。
数据集最近研究
最新研究方向
在跨语言信息检索领域,越南语密集检索模型的训练正面临高质量负样本稀缺的挑战。mmarco-vi-hard-negatives数据集通过整合越南语mMARCO文本与硬负样本标识,为研究者提供了结构化的三元组训练资源。当前前沿研究聚焦于利用该数据集优化双编码器架构,探索不同排名窗口的硬负样本对模型区分能力的影响。随着多语言预训练技术的演进,该数据集在提升越南语检索性能、缓解低资源语言数据不平衡问题方面展现出重要意义,相关成果正推动东南亚语言信息处理技术的实际应用。
以上内容由遇见数据集搜集并总结生成


