PyCode-Vul
收藏Hugging Face2026-04-25 更新2026-04-26 收录
下载链接:
https://huggingface.co/datasets/S-AIR-L/PyCode-Vul
下载链接
链接失效反馈官方服务:
资源简介:
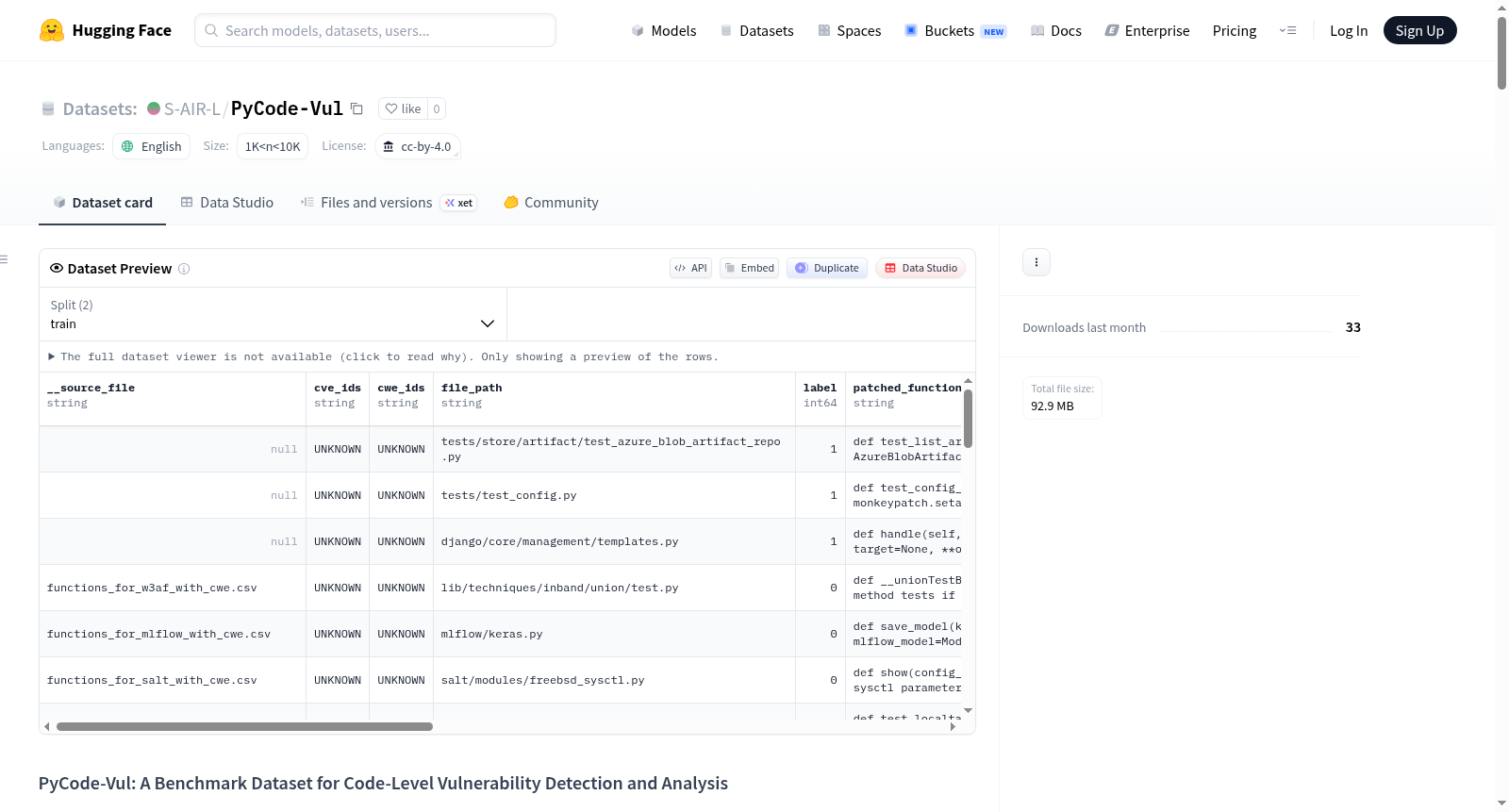
PyCode-Vul 是一个用于代码级漏洞检测和分析的基准数据集,收录于 IEEE BigData 2025。该数据集通过挖掘广泛使用的 Python GitHub 仓库中与安全相关的提交,提取变更文件、识别变更行、恢复前后代码、通过 AST 解析验证 Python 函数、应用 CWE 映射并去除重复样本而构建。数据集包含来自 15 个真实世界 Python 仓库的 7899 个样本,涵盖 Web 框架、安全工具、DevOps 自动化、机器学习生命周期管理等多个领域。数据集分为训练集和测试集,适用于代码级漏洞检测、漏洞分类以及代码预训练模型的实证评估。
PyCode-Vul is a benchmark dataset for code-level vulnerability detection and analysis, included in IEEE BigData 2025. The dataset is constructed by mining security-related commits from widely used Python GitHub repositories, extracting changed files, identifying changed lines, recovering pre- and post-code, validating Python functions through AST parsing, applying CWE mapping, and removing duplicate samples. The dataset contains 7899 samples from 15 real-world Python repositories, covering various domains such as web frameworks, security tools, DevOps automation, and machine learning lifecycle management. The dataset is divided into training and test sets, suitable for code-level vulnerability detection, vulnerability classification, and empirical evaluation of code pre-training models.
创建时间:
2026-04-24
原始信息汇总
PyCode-Vul 数据集概述
基本信息
- 数据集名称: PyCode-Vul (Python Vulnerability Benchmark Dataset)
- 许可协议: CC-BY-4.0
- 语言: 英语
- 数据规模: 1K-10K 样本
- 论文收录: IEEE BigData 2025
数据集简介
PyCode-Vul 是一个用于代码级漏洞检测和分析的真实世界 Python 漏洞基准数据集。该数据集通过从广泛使用的 Python GitHub 仓库中挖掘安全相关提交、提取变更文件、识别变更行、恢复修改前后代码、通过 AST 解析验证 Python 函数、应用 CWE 映射以及去除重复样本构建而成。
数据集用途
- 代码级漏洞检测
- 漏洞分类
- 代码预训练模型的实证评估
数据来源
数据集来源于15个真实世界的 Python 仓库,涵盖Web框架、安全工具、DevOps自动化、机器学习生命周期管理、数据工作流系统、网络库和数字取证工具等领域:
| 仓库 | 样本数 | 用途 |
|---|---|---|
| Sqlmap | 1000 | SQL注入测试工具 |
| Salt | 1006 | 自动化与配置管理 |
| Django | 835 | Web框架 |
| Mlflow | 812 | ML生命周期管理 |
| W3af | 776 | Web应用安全扫描器 |
| Ansible | 727 | IT自动化框架 |
| Airflow | 731 | 工作流编排 |
| Tornado | 423 | Web服务器与网络框架 |
| Paramiko | 336 | SSH通信库 |
| Bandit | 310 | 安全静态分析器 |
| Jupyter | 369 | 交互式计算环境 |
| Volatility | 241 | 内存取证框架 |
| Flask | 141 | 轻量级Web框架 |
| Requests | 139 | HTTP网络库 |
| Yaml | 53 | YAML解析与序列化 |
| 总计 | 7899 |
数据集文件
数据集提供了训练集和测试集划分:
train.csv:训练集test.csv:测试集
每个样本包含:Python代码、仓库信息、提交信息、修改前后函数信息、变更行、哈希值、漏洞相关标签或元数据。
实验评估结果
论文在 PyCode-Vul 测试集上评估了多种代码预训练模型(CodePTMs),包括:CodeBERT、CodeGPT、CodeBERTa、DeBERTa-v3、CodeParrot、GraphCodeBERT、DistilBERT、UniXcoder、CodeGen-Mono、CodeT5+。
关键结果总结
在 PyCode-Vul 测试集上:
- UniXcoder 在准确性、精确率、召回率、特异性、F1、MCC、Kappa、MSE和MAE指标上取得了最佳表现
- CodeBERTa 在AUC分数上取得了最高值(0.9954)
相关链接
- Hugging Face: https://huggingface.co/datasets/S-AIR-L/PyCode-Vul
- Zenodo: https://zenodo.org/records/19746552
- GitHub: https://github.com/S-AiRLab/-PyCode_Vul-A-Benchmark-Dataset-for-Code-Level-Vulnerability-Detection-and-Analysis/tree/main
- Kaggle: https://www.kaggle.com/datasets/oulabspring/pycode-vul-a-benchmark-dataset-for-python/data
引用信息
A Benchmark Dataset for Code-Level Vulnerability Detection and Analysis, Tasmin Karim, Mst Shapna Akter, and Alfredo Cuzzocrea. In 2025 IEEE International Conference on Big Data (BigData), pp. 4237–4246, IEEE, 2025.
搜集汇总
数据集介绍
构建方式
在软件安全日益受到关注的背景下,PyCode-Vul数据集应运而生,旨在为代码级漏洞检测与分析提供高质量的基准资源。该数据集的构建遵循一套严谨且系统的流水线:首先从广泛使用的Python GitHub仓库中挖掘与安全相关的提交记录,随后提取变更文件并定位具体的变更行,恢复函数在修改前后的代码片段;通过抽象语法树(AST)解析来验证函数的合法性,确保仅保留结构完整的Python函数;接着应用通用弱点枚举(CWE)映射以标准化漏洞类型,并借助Bandit工具进行启发式分析辅助标注;最后通过去重与数据清洗,形成最终的样本集合。这一流程融合了版本控制挖掘、代码解析与安全分析技术,确保了数据集的真实性与可靠性。
特点
PyCode-Vul数据集独具多项显著特点。其样本源自15个真实世界的Python项目,覆盖Web框架(如Django、Flask)、安全工具(如Sqlmap、Bandit)、DevOps自动化(如Salt、Ansible)、机器学习生命周期管理(如Mlflow)及数字取证(如Volatility)等多个关键领域,具有高度的代表性与多样性。数据集包含7899个经严格验证的样本,每个样本均提供漏洞修复前后的代码对比、变更行号、CWE类型标签及元数据,支持二分类与多分类任务。此外,该数据集已划分为训练集与测试集,便于直接用于模型训练与评估,并在多项实验中展现出对预训练代码模型的强区分能力,为漏洞检测研究提供了可靠且富有挑战性的基准。
使用方法
PyCode-Vul数据集的使用便捷且灵活,适用于多种研究场景。用户可通过Hugging Face平台直接加载数据,获取包含训练集(train.csv)与测试集(test.csv)在内的CSV文件,每个样本包含完整的Python代码、仓库与提交信息、函数变更细节及标签。研究者可将其用于微调主流代码预训练模型(如CodeBERT、UniXcoder、CodeT5+等),执行漏洞检测与分类任务;亦可结合CWE标签进行细粒度分析,或利用修复前后代码进行补丁生成研究。数据集已在IEEE BigData 2025论文中经过全面评估,并提供了与CVEFixes、VUDENC等基准的对比结果,可作为后续工作的性能参考点。所有资源均通过GitHub与Kaggle开放获取,并附有详细文档与引用指引。
背景与挑战
背景概述
在软件安全领域,代码级漏洞检测一直是研究的热点与难点,尤其是随着Python在Web开发、DevOps自动化、机器学习运维等关键领域的广泛应用,针对该语言的高质量漏洞数据集显得尤为稀缺。PyCode-Vul正是在此背景下应运而生,由Tasmin Karim、Mst Shapna Akter和Alfredo Cuzzocrea等研究者于2025年在IEEE BigData会议上提出,旨在填补Python真实漏洞数据集的空白。该数据集从15个广泛使用的Python开源仓库中挖掘安全相关提交,通过精密的代码变更提取、AST验证与CWE映射流程构建而成,包含了7899个样本,覆盖了从Web框架到安全扫描工具的多个领域。其影响力在于不仅为代码预训练模型的实证评估提供了标准化基准,还推动了漏洞检测从理论走向工程实践的跨越。
当前挑战
PyCode-Vul所解决的领域问题核心在于代码级漏洞检测的精准性与泛化性,现有模型在跨仓库、跨类型的漏洞识别上常面临特征稀疏与误报率高的困境,而该数据集通过细粒度的修复前后函数配对与多维度标签,为模型提供了更真实的训练信号。在构建过程中,挑战尤为严峻:一是从海量提交中准确过滤出安全修复相关的变更,避免噪声干扰;二是通过AST解析确保提取的Python代码片段语法完整且功能可隔离;三是CWE映射的模糊性——同一漏洞可能对应多种分类,需人工校验以维持一致性;四是去除因代码重构或重复提交导致的冗余样本,防止数据偏差。此外,从15个不同用途的仓库中整合数据,还需处理编码风格与文档注释的多样性,保证标注的客观性。
常用场景
经典使用场景
PyCode-Vul作为首个面向真实世界Python仓库的代码级漏洞基准数据集,其经典使用场景聚焦于基于深度学习的漏洞检测模型训练与评估。研究者可借助该数据集对预训练代码模型(如CodeBERT、UniXcoder、CodeT5+)进行微调,以判别函数级代码片段的脆弱性。数据集涵盖从Sqlmap、Django、Airflow等15个广泛使用的Python项目中提取的7899个样本,每一实例均包含漏洞修复前后的函数代码、变化行标注及CWE映射,为上下文敏感的细粒度漏洞定位提供了坚实的数据基础。
衍生相关工作
PyCode-Vul的发布催生了一系列具有代表性的后续研究工作。在模型层面,研究者基于该数据集对CodeBERT、GraphCodeBERT、UniXcoder等十种代码预训练模型进行了系统性基准测试,揭示了代码结构感知(如UniXcoder的AST融合)对检测精度的增益。在方法层面,衍生出针对Python特性的漏洞定位算法,如利用代码变更历史增强的神经网络注意力机制,以及结合图神经网络与数据流分析的高阶依赖捕捉框架。这些工作不仅验证了数据集的扩展性,更推动了漏洞检测从二分类向细粒度修复定位的技术演进。
数据集最近研究
最新研究方向
随着软件安全威胁日益严峻,代码级漏洞检测成为网络安全领域的研究焦点。PyCode-Vul作为被IEEE BigData 2025收录的基准数据集,通过从15个广泛使用的Python真实仓库(涵盖web框架、安全工具、DevOps等关键领域)中挖掘安全相关提交,构建了包含7899个样本的高质量漏洞数据集。该数据集前沿方向聚焦于利用预训练代码模型(如UniXcoder、CodeBERT等)进行漏洞检测与分类,实验结果表明UniXcoder在准确率、F1分数等指标上表现最佳,实现了0.9810的准确率和0.9786的F1分数。这一研究推动了代码智能与软件安全的深度融合,为自动化漏洞检测提供了标准化评估平台,对提升开源软件生态安全具有重要实践意义。
以上内容由遇见数据集搜集并总结生成


