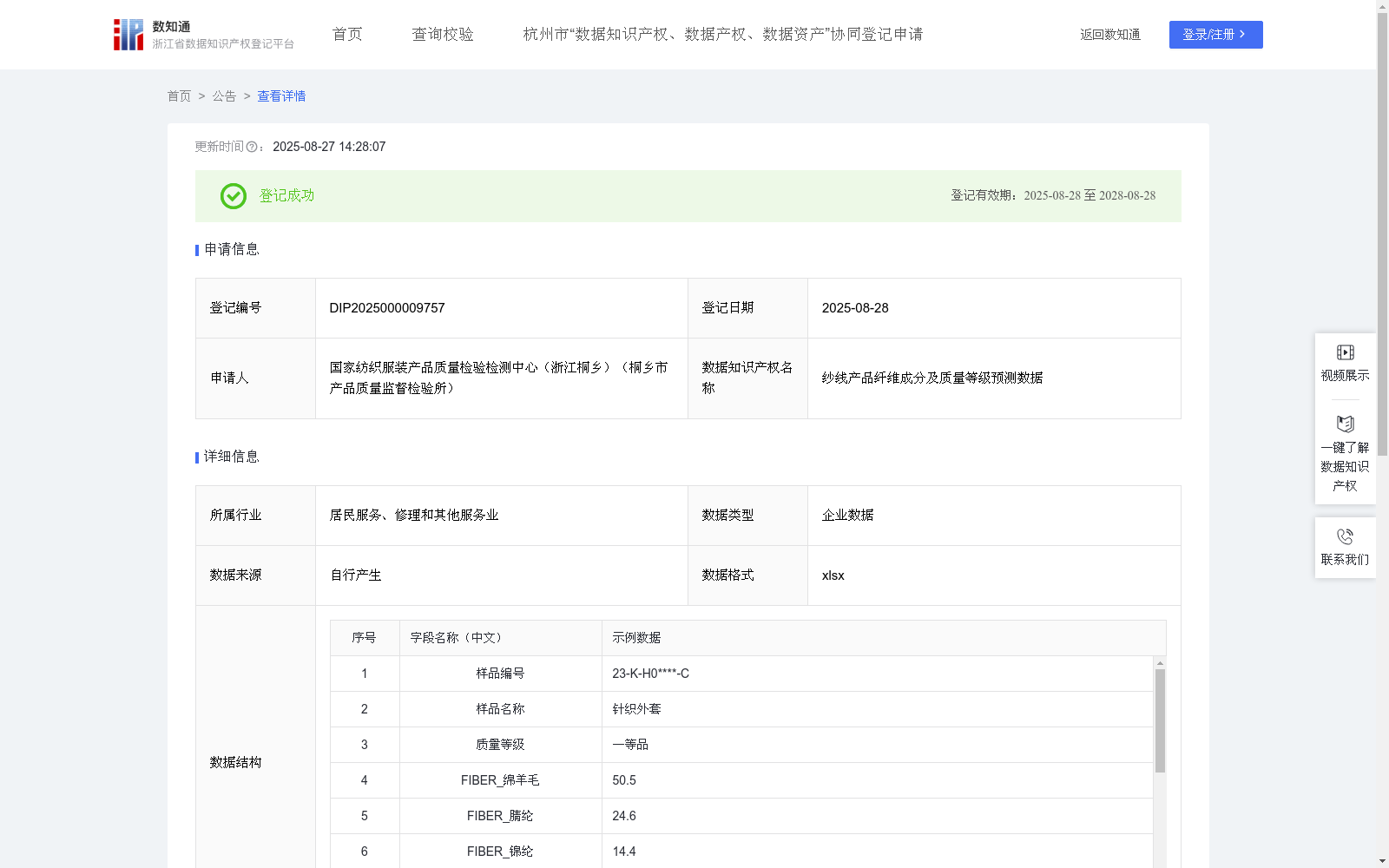
纱线产品纤维成分及质量等级预测数据
收藏浙江省数据知识产权登记平台2025-08-27 更新2025-09-06 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/171624
下载链接
链接失效反馈官方服务:
资源简介:
本数据主要应用于针织服装制造业及第三方质量检测机构的智能质检环节,通过对送检的纱线品类的纤维成分含量数据进行分析,运用数据模型实现对其质量等级的自动化、高效率预测。此应用旨在优化传统的质量评估流程,通过数据驱动的方式减少人工干预,缩短检测周期,降低成本,并为产品的生产工艺优化、快速通关和市场定价策略提供精确的数据依据,从而提升企业在针织服装领域的生产效率与市场竞争力。"数据收集来源于生产线上或送检批次中的纱线品类样本,通过专业的纺织品物理和化学检测手段,精确测定每个样本的纤维组分及含量。在收集过程中,为每一个独立的样本分配一个唯一的“样品编号”以确保数据的可追溯性,同时记录其“样品名称”和由专业质检员评定的实际质量等级。
数据处理阶段着重于对原始检测数据进行系统化的整理与校验。该过程包括将多样化的数据记录统一为标准化的结构化格式,核对并修正各纤维成分(如FIBER_绵羊毛、FIBER_腈纶等)的数据准确性,处理可能存在的异常值或缺失值,最终形成以“样品编号”为主键,包含产品纤维成分特征和质量等级标签的清洁数据集,为后续的算法建模提供高质量的输入。
数据加工阶段通过构建一个智能分类算法模型来揭示产品纤维成分与质量等级之间的内在关联。该模型利用处理后的数据集进行监督学习训练,其核心算法可表述为公式:预测质量等级 = 等级预测分类器(FIBER_绵羊毛, FIBER_腈纶, FIBER_锦纶, FIBER_山羊绒, ...)。在此公式中,“预测质量等级”是模型对具有唯一“样品编号”的特定“样品名称”产品所输出的判定结果;“等级预测分类器”使用了随机森林分类器,其中决策树数量为180,最大深度为13;而“FIBER_绵羊毛”、“FIBER_腈纶”、“FIBER_锦纶”、“FIBER_山羊绒”等一系列纤维含量数据则是输入模型的关键判断依据。"
This dataset is primarily applied to the intelligent quality inspection processes of knitted garment manufacturing enterprises and third-party quality inspection institutions. It analyzes the fiber composition and content data of submitted yarn samples, and uses data models to achieve automated and highly efficient prediction of their quality grades. This application aims to optimize traditional quality assessment workflows, reduce manual intervention via data-driven approaches, shorten inspection cycles, and cut costs. It also provides accurate data support for production process optimization, rapid customs clearance, and market pricing strategies of products, thereby enhancing enterprises' production efficiency and market competitiveness in the knitted garment sector.
The data is collected from yarn samples taken from production lines or submitted batches. Professional physical and chemical testing methods for textiles are employed to accurately measure the fiber composition and content of each sample. During the collection process, each independent sample is assigned a unique "sample ID" to ensure data traceability, while its "sample name" and the actual quality grade evaluated by professional quality inspectors are also recorded.
The data processing phase focuses on systematic organization and verification of the original test data. This process includes unifying diverse data records into a standardized structured format, verifying and correcting the accuracy of data for various fiber components (such as FIBER_Wool, FIBER_Acrylic, FIBER_Nylon, FIBER_Cashmere, etc.), handling potential outliers or missing values, and finally forming a clean dataset with "sample ID" as the primary key, which contains product fiber composition features and quality grade labels, providing high-quality input for subsequent algorithm modeling.
The model development phase constructs an intelligent classification algorithm model to reveal the internal correlation between product fiber composition and quality grades. This model is trained via supervised learning using the processed dataset, and its core algorithm can be expressed by the formula: Predicted Quality Grade = Grade Prediction Classifier(FIBER_Wool, FIBER_Acrylic, FIBER_Nylon, FIBER_Cashmere, ...). In this formula, "Predicted Quality Grade" is the judgment result output by the model for a specific product with a unique "sample ID" and "sample name"; the "Grade Prediction Classifier" adopts a Random Forest classifier with 180 decision trees and a maximum depth of 13; and a series of fiber content data such as FIBER_Wool, FIBER_Acrylic, FIBER_Nylon, FIBER_Cashmere serve as the key judgment basis for inputting into the model.
提供机构:
国家纺织服装产品质量检验检测中心(浙江桐乡)(桐乡市产品质量监督检验所)
创建时间:
2025-06-30
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集包含6734条纱线产品的纤维成分和质量等级数据,用于通过随机森林分类器预测产品质量等级,主要应用于针织服装制造业和质检机构的智能质检环节,以提升效率和降低成本。
以上内容由遇见数据集搜集并总结生成


