medalpaca/medical_meadow_medqa
收藏Hugging Face2023-04-06 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/medalpaca/medical_meadow_medqa
下载链接
链接失效反馈官方服务:
资源简介:
---
task_categories:
- question-answering
language:
- en
- zh
tags:
- medical
---
# Dataset Card for MedQA
## Dataset Description
- **Paper:**
### Dataset Summary
This is the data and baseline source code for the paper: Jin, Di, et al. "What Disease does this Patient Have? A Large-scale Open Domain Question Answering Dataset from Medical Exams."
From https://github.com/jind11/MedQA:
>The data that contains both the QAs and textbooks can be downloaded from [this google drive folder](https://drive.google.com/file/d/1ImYUSLk9JbgHXOemfvyiDiirluZHPeQw/view?usp=sharing). A bit of details of data are explained as below:
>
> For QAs, we have three sources: US, Mainland of China, and Taiwan District, which are put in folders, respectively. All files for QAs are in jsonl file format, where each line is a data sample as a dict. The "XX_qbank.jsonl" files contain all data samples while we also provide an official random split into train, dev, and test sets. Those files in the "metamap" folders are extracted medical related phrases using the Metamap tool.
>
> For QAs, we also include the "4_options" version in for US and Mainland of China since we reported results for 4 options in the paper.
>
> For textbooks, we have two languages: English and simplified Chinese. For simplified Chinese, we provide two kinds of sentence spliting: one is split by sentences, and the other is split by paragraphs.
### Citation Information
```
@article{jin2020disease,
title={What Disease does this Patient Have? A Large-scale Open Domain Question Answering Dataset from Medical Exams},
author={Jin, Di and Pan, Eileen and Oufattole, Nassim and Weng, Wei-Hung and Fang, Hanyi and Szolovits, Peter},
journal={arXiv preprint arXiv:2009.13081},
year={2020}
}
```
任务类别:
- 问答任务
语言:
- 英语
- 汉语
标签:
- 医学
# MedQA 数据集卡片
## 数据集说明
- **论文:**
### 数据集概览
本数据集与基线源代码对应论文为:Jin Di等人发表的《该患者罹患何种疾病?源自医学考试的大规模开放域问答数据集》。
数据仓库地址:https://github.com/jind11/MedQA:
> 包含问答数据与教科书文本的数据集可通过[此谷歌云端硬盘文件夹](https://drive.google.com/file/d/1ImYUSLk9JbgHXOemfvyiDiirluZHPeQw/view?usp=sharing)下载。数据集细节说明如下:
> 针对问答数据,我们设有三个来源:美国、中国大陆以及中国台湾地区,分别置于对应文件夹中。所有问答数据文件均采用jsonl格式,每行均为一个以字典形式存储的样本。"XX_qbank.jsonl" 文件包含全部问答样本,同时我们还提供了官方随机划分的训练集、开发集与测试集。"metamap" 文件夹内的文件为使用Metamap工具提取的医学相关短语。
> 针对美国与中国大陆的问答数据,我们额外提供了「四选项」版本,与论文中报告的四选一实验设置保持一致。
> 针对教科书文本,我们提供了英文与简体中文两种语言版本。其中简体中文文本提供两种分句方式:一种按句子拆分,另一种按段落拆分。
### 引用信息
@article{jin2020disease,
title={What Disease does this Patient Have? A Large-scale Open Domain Question Answering Dataset from Medical Exams},
author={Jin, Di and Pan, Eileen and Oufattole, Nassim and Weng, Wei-Hung and Fang, Hanyi and Szolovits, Peter},
journal={arXiv preprint arXiv:2009.13081},
year={2020}
}
提供机构:
medalpaca
原始信息汇总
MedQA数据集概述
数据集描述
- 任务类别: 问答(question-answering)
- 语言: 英语(en)、中文(zh)
- 标签: 医疗(medical)
数据集总结
- 来源论文: Jin, Di, et al. "What Disease does this Patient Have? A Large-scale Open Domain Question Answering Dataset from Medical Exams."
- 数据下载: 数据包含问答和教科书内容,可从此Google Drive文件夹下载。
数据详情
-
问答数据:
- 来源:美国、中国大陆、台湾地区,分别存放于不同文件夹。
- 格式:jsonl文件格式,每行代表一个数据样本。
- 版本:提供“4_options”版本,适用于美国和中国大陆。
-
教科书数据:
- 语言:英语和简体中文。
- 分割方式:简体中文提供按句子和按段落两种分割方式。
引用信息
@article{jin2020disease, title={What Disease does this Patient Have? A Large-scale Open Domain Question Answering Dataset from Medical Exams}, author={Jin, Di and Pan, Eileen and Oufattole, Nassim and Weng, Wei-Hung and Fang, Hanyi and Szolovits, Peter}, journal={arXiv preprint arXiv:2009.13081}, year={2020} }
搜集汇总
数据集介绍
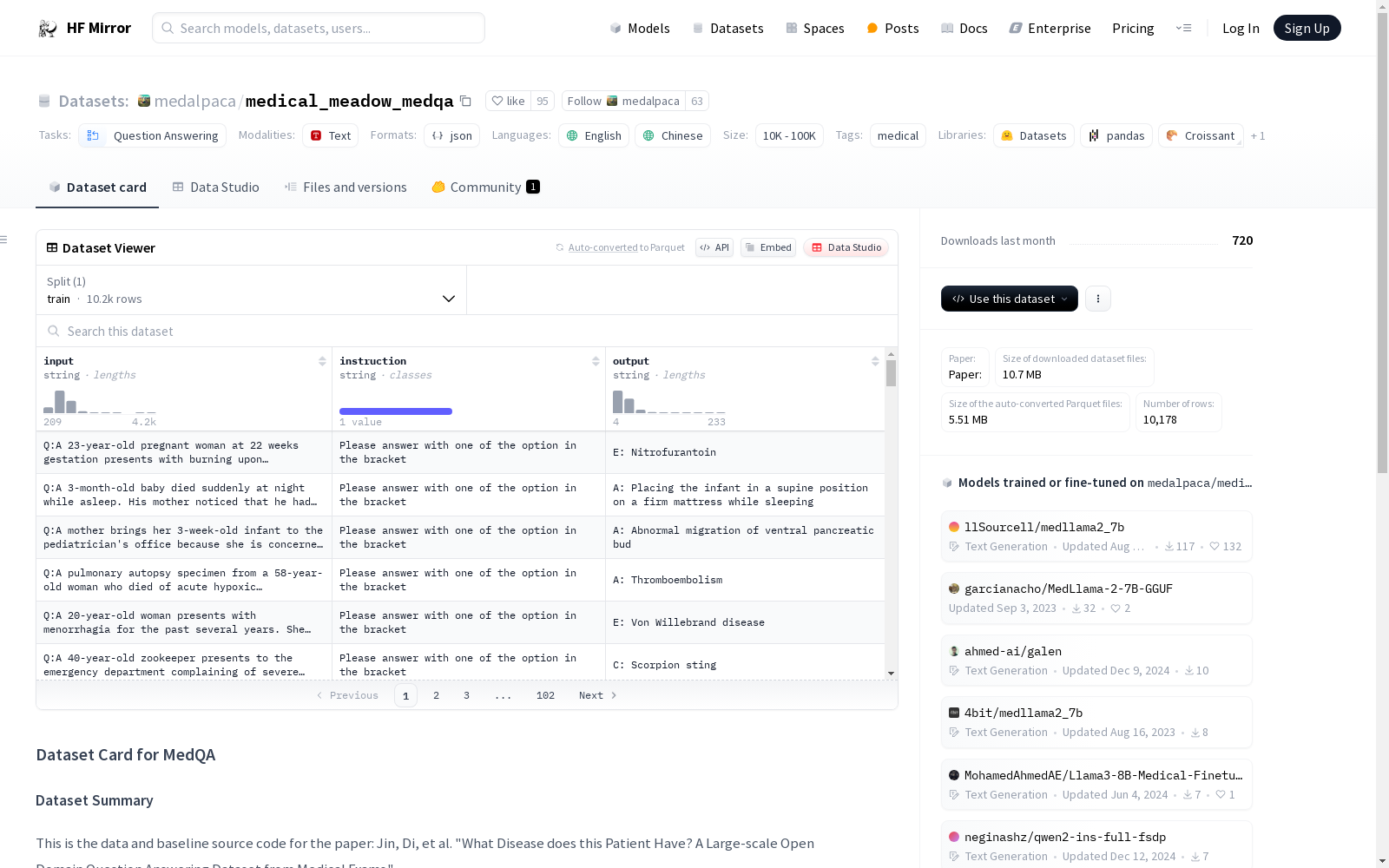
构建方式
medalpaca/medical_meadow_medqa数据集的构建汇集了来自美国、中国大陆及台湾地区的大规模医疗问答数据。数据集包含问答对以及医学教材文本,问答对以jsonl文件格式存储,每行代表一个数据样本字典。数据集构建者利用Metamap工具提取了与医学相关的短语,并提供了包含四个选项的问答版本以满足不同研究需求。
特点
该数据集的特点在于其开放域的医疗问题问答,覆盖了广泛的医学领域。数据集不仅提供了英文版本,还提供了简体中文版本,并针对中文版本实现了两种句子切分方式:按句子切分和按段落切分。此外,官方还提供了训练集、验证集和测试集的随机划分,以方便研究者和开发者使用。
使用方法
使用medalpaca/medical_meadow_medqa数据集时,研究者可以依据官方提供的随机数据划分,直接进行模型训练、验证和测试。数据集的多样性和详尽的医学相关短语,使得该数据集适用于构建和评估医疗问答系统。用户可以从数据集的Google Drive链接下载所需数据,并按照数据集的文件格式说明进行加载和使用。
背景与挑战
背景概述
MedQA数据集,由Jin Di等研究人员于2020年提出,旨在解决医学领域的问题回答任务。该数据集整合了来自美国、中国大陆和台湾地区的大规模开放域医学问题及答案,并辅以医学教材文本,为医学自然语言处理研究提供了丰富的资源。数据集的构建得到了广泛的关注,对医学信息检索、知识图谱构建等医疗健康相关领域产生了显著影响。
当前挑战
MedQA数据集在构建过程中面临了诸多挑战,其中包括跨地区医疗术语的统一性、医学知识的准确提取与表示,以及大规模数据标注的准确性和一致性。此外,数据集在解决医学问题回答任务时,还需应对如何提高答案的准确度、降低误诊率以及处理医学文本的模糊性和复杂性等挑战。
常用场景
经典使用场景
在医学领域的信息检索任务中,medalpaca/medical_meadow_medqa数据集提供了一个大规模的开放域问题回答的数据基础,其经典的使用场景是构建医学问答系统。该数据集通过模拟医患之间的对话,提供了疾病诊断相关的问答对,使得研究者可以训练模型以理解和回答患者关于疾病诊断的问题。
衍生相关工作
基于该数据集,学术界已经衍生出一系列相关工作,包括但不限于医学知识图谱的构建、跨语言医学问答系统的开发,以及针对特定疾病的诊断模型的建立。这些研究进一步推动了医学信息学领域的发展,拓宽了数据集的应用范围。
数据集最近研究
最新研究方向
在医学领域,MedQA数据集的构建与利用已经成为自然语言处理任务中的一大突破。该数据集聚焦于大规模开放域的医学问答,旨在提升医疗诊断与信息检索的自动化水平。近期研究集中于深度学习模型的开发与优化,以处理MedQA中的复杂问答对,进而推动医学信息学的进步。通过该数据集,研究者能够训练模型以识别患者可能患有的疾病,为临床决策提供辅助支持。其影响与意义在于,能够加快医学知识的获取速度,提升医疗服务的效率和准确性,对于构建智慧医疗体系具有重要作用。
以上内容由遇见数据集搜集并总结生成


