Annotated IOB-corpus for Analyzing Material Research Trends
收藏github2021-09-13 更新2024-05-31 收录
下载链接:
https://github.com/BananaTonic/Material_Synthesis_Corpus
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含301个合成过程的标记信息,用于分析无机材料文献中的研究趋势。数据集分为训练集、开发集和测试集,每个文件包含等长的标记和标签数组。
This dataset comprises 301 annotated synthetic processes, designed for analyzing research trends in inorganic materials literature. The dataset is partitioned into training, development, and test sets, with each file containing arrays of tokens and labels of equal length.
创建时间:
2021-06-07
原始信息汇总
数据集概述
数据集名称
Annotated IOB-corpus for Analyzing Material Research Trends
数据集内容
corpus/*.tsv:包含301个合成过程的标记信息,分为"train.tsv"、"devel.tsv"和"test.tsv"。这些文档包含等长的令牌数组及其相应的标签。ann:包含以BRAT注释格式存储的原始注释文件,可用于加载到BRAT实例中并修改注释。
数据集用途
该数据集适用于非商业目的,如学术研究、教学、科学出版或个人实验。
许可证
数据集遵循Creative Commons Attribution-NonCommercial 4.0 International License。
引用信息
若使用此数据集进行研究,请引用以下文献:
- Kuniyoshi, F., Ozawa, J., & Miwa, M. (2021). Analyzing Research Trends in Inorganic Materials Literature Using NLP. ArXiv, abs/2106.14157.
- Kuniyoshi, F., Makino, K., Ozawa, J., & Miwa, M. (2020). Annotating and Extracting Synthesis Process of All-Solid-State Batteries from Scientific Literature. LREC.
搜集汇总
数据集介绍
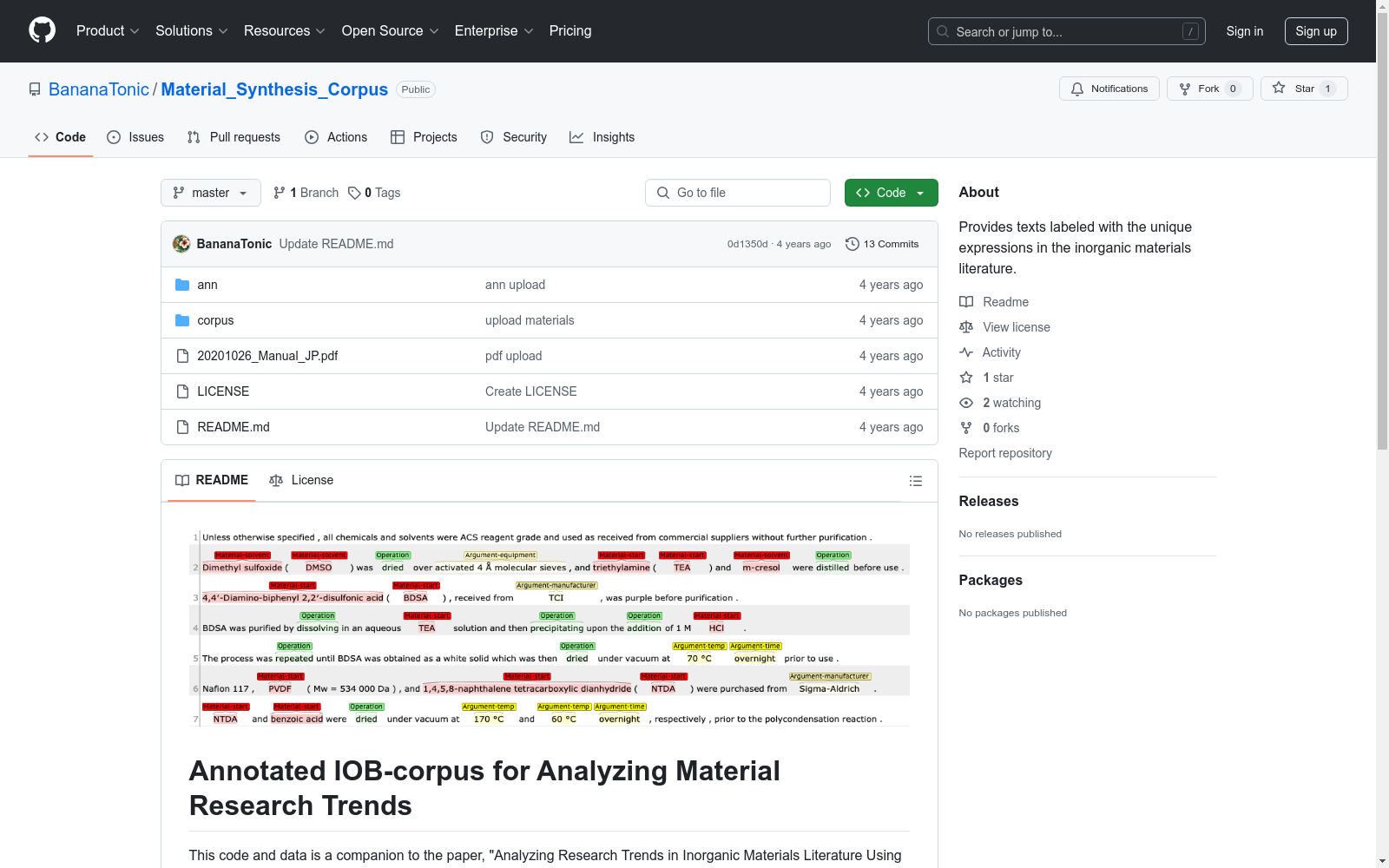
构建方式
该数据集的构建基于无机材料研究文献的自然语言处理分析,旨在捕捉材料合成过程中的关键信息。数据集通过人工标注的方式,将301个材料合成过程分解为训练集、开发集和测试集,每个过程均以IOB格式进行标记,确保数据的结构化和可解析性。标注过程中使用了BRAT工具,允许用户根据需要调整和扩展标注内容。
使用方法
该数据集的使用方法包括加载和解析TSV文件中的标记和标签数据,适用于训练和评估自然语言处理模型。用户可以通过BRAT工具加载原始标注文件,进行标注的修改或扩展。数据集特别适用于材料科学领域的文本挖掘和趋势分析,支持学术研究和教学用途。使用时需遵循CC BY-NC 4.0许可协议,确保非商业用途。
背景与挑战
背景概述
Annotated IOB-corpus for Analyzing Material Research Trends数据集由Fusataka Kuniyoshi等人于2021年创建,旨在通过自然语言处理(NLP)技术分析无机材料科学文献中的研究趋势。该数据集包含301个合成过程的标注信息,涵盖了训练、开发和测试三个子集,每个子集均包含等长的标记及其对应的标签。该数据集的发布为材料科学领域的研究者提供了一个强有力的工具,能够从大量文献中提取和分析合成过程的关键信息,从而推动材料科学的研究进展。
当前挑战
该数据集在构建过程中面临的主要挑战包括如何准确标注复杂的材料合成过程,以及如何处理文献中多样化的表达方式。由于材料科学文献通常包含高度专业化的术语和复杂的实验描述,标注工作需要具备深厚的领域知识。此外,数据集的构建还需要解决如何平衡标注的准确性与标注效率的问题。在应用层面,该数据集的主要挑战在于如何利用NLP技术从标注数据中提取出有用的信息,并进一步应用于材料研究趋势的分析与预测。
常用场景
经典使用场景
在材料科学研究领域,Annotated IOB-corpus数据集为研究人员提供了一个标准化的工具,用于分析和理解无机材料文献中的研究趋势。通过自然语言处理技术,该数据集能够帮助研究者从大量科学文献中提取出关键的材料合成过程信息,进而揭示材料科学领域的研究热点和发展方向。
解决学术问题
该数据集解决了材料科学领域中文献信息提取和趋势分析的难题。通过提供详细的标注数据,研究者可以利用机器学习模型自动识别和分类材料合成过程中的关键步骤,从而减少人工分析的工作量,并提高研究的准确性和效率。这一数据集为材料科学领域的文献挖掘提供了重要的数据支持,推动了该领域的智能化发展。
实际应用
在实际应用中,Annotated IOB-corpus数据集被广泛用于材料科学研究的自动化工具开发。例如,科研机构可以利用该数据集训练模型,自动从文献中提取材料合成方法,并生成材料数据库。这不仅加速了新材料的发现过程,还为材料设计提供了数据驱动的决策支持。此外,该数据集还可用于教育领域,帮助学生和研究人员更好地理解材料合成过程。
数据集最近研究
最新研究方向
近年来,随着材料科学领域的快速发展,无机材料的研究趋势分析成为了学术界的热点。Annotated IOB-corpus数据集通过自然语言处理技术,为无机材料文献中的合成过程提供了详细的标注信息。该数据集不仅包含了301个合成过程的标记数据,还支持BRAT格式的原始标注文件,使得研究者能够灵活地进行数据修改和扩展。这一数据集的应用,极大地推动了材料科学领域的研究趋势分析,尤其是在全固态电池等先进材料的合成过程研究中,展现了其独特的价值。通过该数据集,研究者能够更精准地提取和分析文献中的关键信息,从而加速新材料的设计与开发。
以上内容由遇见数据集搜集并总结生成


