ruozhiba-punchline
收藏Hugging Face2024-09-11 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/LooksJuicy/ruozhiba-punchline
下载链接
链接失效反馈官方服务:
资源简介:
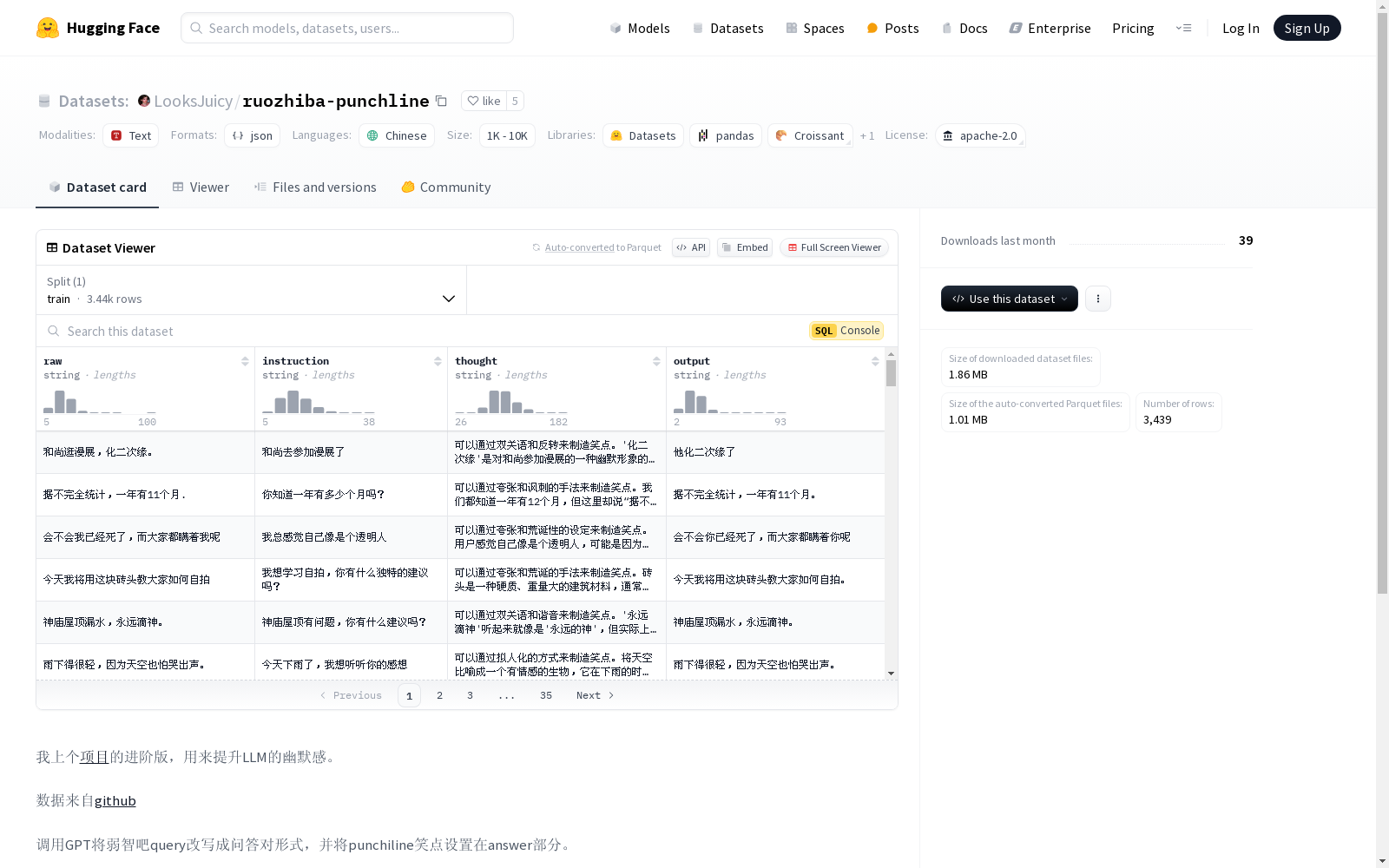
该数据集是上一个项目的进阶版,旨在提升语言模型的幽默感。数据来源于弱智吧,通过GPT将查询改写成问答对形式,并将笑点设置在回答部分。数据集还包含了一个CoT模块,但该模块的错误率较高,不建议用于训练。示例展示了基于该数据集训练的模型的推理结果。
This dataset is an advanced iteration of the previous project, designed to enhance the humor generation capability of language models. It is sourced from Ruozhi Bar, where raw queries were rewritten into question-answer pairs via GPT, with the punchline placed in the answer section. The dataset also includes a Chain-of-Thought (CoT) module, which exhibits a relatively high error rate and is not recommended for model training. Examples are provided to demonstrate the inference results of models trained on this dataset.
创建时间:
2024-09-11
原始信息汇总
数据集概述
基本信息
- 许可证: Apache 2.0
- 语言: 中文
数据来源
- 数据来自github
数据处理
- 调用GPT将弱智吧query改写成问答对形式,并将punchiline笑点设置在answer部分。
- 额外添加CoT模块,但CoT部分错误率较高,经验上不建议加入训练。
示例
Q: 欲望和收入不匹配这件事情你怎么看 A: 我觉得只要心态好,慢慢挣就好了,欲速则布达拉宫
Q:握不住的沙就扬了吧 A:阿sir,这种话让人听了很不舒服,建议不要说出来。
搜集汇总
数据集介绍
构建方式
ruozhiba-punchline数据集的构建源于对提升大型语言模型幽默感的追求。数据主要来源于GitHub上的弱智吧内容,通过调用GPT模型将这些内容改写成问答对的形式,并将笑点巧妙地设置在答案部分。此外,数据集还尝试引入了CoT(Chain of Thought)模块,尽管该部分的错误率较高,实际应用中建议谨慎使用。
特点
该数据集的显著特点在于其独特的幽默表达方式,通过将笑点嵌入到问答对的答案中,增强了模型的幽默生成能力。数据集中包含的问答对不仅展示了语言的巧妙运用,还体现了对日常生活的深刻观察和幽默解读。尽管CoT模块存在一定的错误率,但其尝试为数据集增添了额外的思考维度。
使用方法
ruozhiba-punchline数据集主要用于训练和评估大型语言模型的幽默生成能力。用户可以通过加载数据集,利用其中的问答对进行模型训练,特别关注模型在生成幽默回答方面的表现。在实际应用中,建议用户根据具体需求选择是否包含CoT模块,以达到最佳的模型训练效果。通过这种方式,数据集为提升语言模型的幽默感提供了宝贵的资源。
背景与挑战
背景概述
ruozhiba-punchline数据集是一个专注于提升大型语言模型(LLM)幽默感的数据集,由研究人员Leymore于近期创建。该数据集基于弱智吧的原始数据,通过调用GPT模型将弱智吧的query改写成问答对形式,并将笑点(punchline)设置在回答部分。这一创新不仅丰富了对话系统的趣味性,也为自然语言处理领域提供了新的研究方向。该数据集的发布标志着幽默生成技术在人工智能领域的进一步探索,对提升LLM的对话质量和用户体验具有重要意义。
当前挑战
ruozhiba-punchline数据集在构建和应用过程中面临多重挑战。首先,幽默的生成和理解具有高度主观性,如何确保模型生成的回答既符合逻辑又具有幽默感是一个核心难题。其次,数据集中添加的CoT(Chain-of-Thought)模块错误率较高,影响了模型的训练效果,如何优化CoT模块以提高其准确性和实用性是亟待解决的问题。此外,数据集的规模和质量仍需进一步提升,以确保模型在多样化的对话场景中能够稳定输出高质量的幽默内容。
常用场景
经典使用场景
在自然语言处理领域,ruozhiba-punchline数据集主要用于提升大型语言模型(LLM)的幽默感生成能力。通过将弱智吧的原始查询改写成问答对形式,并将笑点设置在答案部分,该数据集为模型提供了丰富的幽默语言样本。这种设计使得模型能够在生成文本时,不仅保持逻辑连贯性,还能融入幽默元素,从而提升用户体验。
衍生相关工作
基于ruozhiba-punchline数据集,研究者们已经开展了多项相关工作。例如,一些研究专注于改进模型的幽默生成能力,通过引入更复杂的推理机制或结合其他情感数据集,进一步提升模型的幽默表现。此外,该数据集还被用于探索幽默生成与情感分析、文本风格迁移等领域的交叉研究,推动了自然语言处理技术的多元化发展。
数据集最近研究
最新研究方向
在自然语言处理领域,幽默生成一直是极具挑战性的研究方向。近期,ruozhiba-punchline数据集的出现为提升大型语言模型(LLM)的幽默感提供了新的研究视角。该数据集通过将弱智吧的query改写成问答对形式,并将笑点设置在answer部分,为模型训练提供了丰富的幽默素材。尽管数据集中的CoT模块错误率较高,但其独特的幽默生成机制仍为研究者提供了宝贵的实验数据。当前,基于该数据集的研究主要集中在如何优化模型的幽默生成能力,以及如何通过改进CoT模块来提升模型的推理准确性。这一研究方向不仅推动了幽默生成技术的发展,也为LLM在情感计算和人机交互领域的应用开辟了新的可能性。
以上内容由遇见数据集搜集并总结生成


