minecraft-vla-stage1
收藏Hugging Face2025-12-05 更新2025-12-06 收录
下载链接:
https://huggingface.co/datasets/TESS-Computer/minecraft-vla-stage1
下载链接
链接失效反馈官方服务:
资源简介:
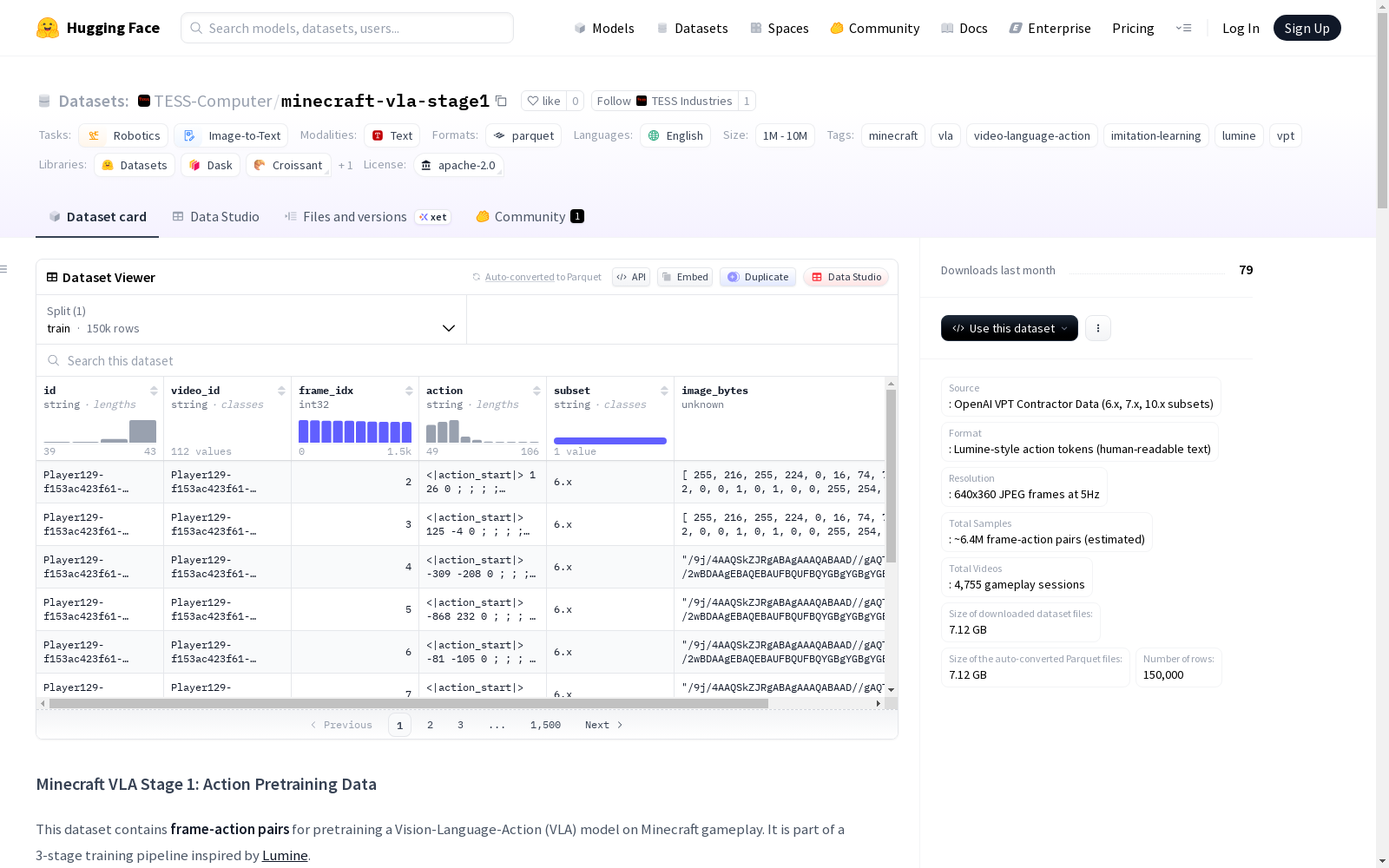
该数据集名为'Minecraft VLA Stage 1: Action Pretraining Data',用于预训练视觉-语言-动作(VLA)模型在Minecraft游戏中的表现。数据集包含帧-动作对,来源于OpenAI VPT 6.x承包商数据,格式为Lumine风格的动作令牌。分辨率是640x360 JPEG帧,采样率为5Hz,总样本约为6.4M帧-动作对,来自4,755个游戏会话。动作格式包括鼠标移动、滚动和按键组合,详细描述了按键映射和动作格式。数据集还提供了数据管道的详细步骤,包括数据下载、帧提取、动作转换、过滤和保存。此外,README还描述了数据集的三个阶段训练流程,以及如何使用该数据集和引用信息。
This dataset is named "Minecraft VLA Stage 1: Action Pretraining Data", which is designed to pretrain Vision-Language-Action (VLA) models for their gameplay performance in Minecraft. The dataset comprises frame-action pairs sourced from OpenAI VPT 6.x contractor data, formatted as Lumine-style action tokens. The frames are 640x360 JPEG images with a sampling rate of 5 Hz, and there are approximately 6.4 million total frame-action pairs across 4,755 distinct game sessions. The supported action formats include mouse movement, scrolling, and key combinations, with detailed explanations of key mappings and action specifications. The dataset also provides detailed procedures for its data pipeline, including data download, frame extraction, action transformation, filtering, and storage. Furthermore, the accompanying README outlines the three-stage training workflow of the dataset, as well as guidelines for using the dataset and citation information.
创建时间:
2025-12-05
原始信息汇总
Minecraft VLA Stage 1: Action Pretraining Data 数据集概述
数据集基本信息
- 许可证:Apache 2.0
- 任务类别:机器人学、图像到文本
- 语言:英语
- 标签:Minecraft、VLA、Video-Language-Action、模仿学习、Lumine、VPT
- 规模类别:1M<n<10M
数据集描述
- 来源:OpenAI VPT 6.x 承包商数据
- 格式:Lumine风格的动作标记(人类可读文本)
- 分辨率:640x360 JPEG帧,采样率5Hz
- 总样本数:约640万帧-动作对(估计值)
- 总视频数:4,755个游戏会话
动作格式
动作采用Lumine文本格式,每200ms帧包含4个时间块:
<|action_start|> mouse_x mouse_y scroll ; K1 ; K2 ; K3 ; K4 <|action_end|>
组成部分:
mouse_x mouse_y:相机增量(-1000至1000)scroll:鼠标滚轮(在Minecraft中始终为0)K1-K4:每个50ms块的按键组合
示例:
<|action_start|> 45 -12 0 ; W ; W Space ; W ; W <|action_end|>
含义:相机向右移动45,向上移动12,在所有块中按住W,在块2按下Space。
按键映射
| 按键 | 动作 |
|---|---|
| W/A/S/D | 移动 |
| Space | 跳跃 |
| Shift | 潜行 |
| Ctrl | 冲刺 |
| LMB | 攻击/挖掘 |
| RMB | 使用/放置 |
| E | 物品栏 |
| Q | 丢弃 |
| 1-9 | 快捷栏槽位 |
数据模式
| 列名 | 类型 | 描述 |
|---|---|---|
id |
字符串 | 唯一样本ID(视频_帧) |
video_id |
字符串 | 源视频标识符 |
frame_idx |
int32 | 视频内的帧索引 |
action |
字符串 | Lumine格式的动作字符串 |
image_bytes |
二进制 | JPEG编码的帧(640x360) |
数据处理流程
- 从OpenAI Blob存储下载VPT 6.x视频
- 使用ffmpeg以5Hz提取帧
- 将20Hz VPT动作转换为4块Lumine格式
- 过滤黑暗/加载帧(<5KB)
- 使用Snappy压缩保存为Parquet分片
训练阶段
这是3阶段VLA训练流程的第1阶段:
| 阶段 | 数据 | 目的 |
|---|---|---|
| 1. 动作预训练 | 本数据集 | 学习基本的视觉运动控制 |
| 2. 任务SFT | JARVIS-VLA + 指令 | 学习任务条件行为 |
| 3. 智能体训练 | 推理轨迹 | 学习规划与分解 |
使用方式
python from datasets import load_dataset
流式加载(大型数据集推荐)
ds = load_dataset("TESS-Computer/minecraft-vla-stage1", split="train", streaming=True)
for sample in ds: image = sample["image_bytes"] # JPEG字节 action = sample["action"] # Lumine格式字符串 # ... 处理样本
引用
如果使用本数据集,请引用: bibtex @misc{tess-minecraft-vla-2025, title={Minecraft VLA: Vision-Language-Action Model for Minecraft}, author={TESS Industries}, year={2025}, url={https://huggingface.co/datasets/TESS-Computer/minecraft-vla-stage1} }
致谢
- OpenAI VPT团队:发布承包商游戏数据
- Lumine团队:提供动作标记化格式
- JARVIS-VLA团队:提供任务条件SFT方法
许可证
Apache 2.0 - 底层VPT数据由OpenAI为研究目的发布。
搜集汇总
数据集介绍
构建方式
在机器人学与视觉语言动作模型交叉领域,Minecraft VLA Stage 1数据集的构建体现了对大规模游戏行为数据的系统化处理。该数据集源自OpenAI VPT 6.x承包商游戏录像,通过ffmpeg工具以5Hz频率提取640x360分辨率的JPEG帧,并将原始20Hz的VPT动作序列转换为Lumine风格的四时间块文本格式。构建过程中,通过过滤低质量帧(如小于5KB的暗帧或加载帧),最终生成了约640万帧动作对,涵盖4755个独立游戏会话,数据以Parquet分片形式存储并采用Snappy压缩,确保了高效存储与访问。
特点
该数据集的核心特征在于其高度结构化的动作表示与视觉帧的精确对齐。动作采用人类可读的文本格式,每个200毫秒帧对应四个50毫秒时间块,详细编码了鼠标移动、滚轮及按键组合信息,如“W Space”表示同时按住移动键与跳跃键。这种设计不仅保留了动作的时序粒度,还通过标准化键位映射(如W/A/S/D对应移动、Space对应跳跃)实现了跨模型的一致性。此外,数据集以流式加载优化支持大规模处理,兼顾了高分辨率视觉输入与细粒度动作指令的耦合,为视觉语言动作模型的预训练提供了密集且可解释的监督信号。
使用方法
在模型训练实践中,该数据集主要用于视觉语言动作模型的基础动作预训练阶段。研究人员可通过Hugging Face datasets库以流式模式加载数据,逐样本获取JPEG编码的图像字节与Lumine格式动作字符串。典型流程包括解析动作文本中的相机增量与按键序列,并将其与对应帧联合输入模型,以学习从视觉观察到动作输出的映射关系。该数据集作为三阶段训练流程的初始环节,旨在建立基本的视觉运动控制能力,为后续任务微调与智能体规划阶段奠定基础,使用者需遵循Apache 2.0许可并引用相关研究以符合学术规范。
背景与挑战
背景概述
在具身智能与机器人学习领域,如何让智能体通过视觉观察与语言指令来理解和执行复杂的物理世界任务,一直是核心研究难题。Minecraft VLA Stage 1数据集应运而生,由TESS Industries于2025年构建,其核心研究问题聚焦于为视觉-语言-动作模型提供大规模、高质量的预训练数据。该数据集源自OpenAI的VPT 6.x承包商游戏录像,通过提取帧-动作对,旨在让模型从人类演示中学习基础的视觉运动控制能力。作为三阶段训练流程的初始环节,它为后续的任务特定微调与智能体规划学习奠定了数据基础,对推进开放世界环境中的模仿学习与具身智能研究具有显著影响力。
当前挑战
该数据集致力于解决视觉-语言-动作模型在开放世界环境(如《我的世界》)中学习基础视觉运动控制的挑战,其核心难题在于如何将高维、连续的视觉输入与离散、结构化的动作输出进行精确对齐与映射。在构建过程中,研究者面临多重技术挑战:首先,需要将原始的高频动作数据(20Hz)转化为适合模型处理的、包含时间分块的文本化表示格式;其次,必须有效过滤无效帧(如黑暗或加载画面),以确保数据质量;此外,处理大规模视频流(总计约640万帧)并保持帧-动作对的时序一致性,对数据管道的设计与计算资源提出了较高要求。
常用场景
经典使用场景
在具身智能与机器人学习领域,Minecraft-VLA-Stage1数据集为视觉-语言-动作模型的预训练提供了关键支撑。该数据集通过约640万帧动作对,模拟了人类在《我的世界》游戏环境中的操作序列,使模型能够学习从视觉输入到动作输出的映射关系。其经典应用场景在于模仿学习,模型通过观察高维图像帧并预测对应的动作标记,从而掌握基础的运动控制和环境交互能力,为后续复杂任务奠定基础。
解决学术问题
该数据集有效应对了视觉-语言-动作模型中数据稀缺与对齐的挑战。它通过大规模、高质量的帧动作配对,解决了从多模态输入到连续动作空间的转换问题,促进了端到端控制策略的学习。在学术意义上,它为研究具身智能的感知-行动闭环提供了标准化基准,推动了模仿学习、强化学习与多模态融合等领域的发展,并为开放世界环境中的自主决策研究提供了实验基础。
衍生相关工作
围绕该数据集,已衍生出一系列经典研究工作。例如,基于Lumine动作标记格式的视觉-语言-动作模型架构得到了进一步优化;结合JARVIS-VLA的任务微调方法,实现了从基础控制到指令跟随的进阶;同时,该数据集也为后续的规划与推理阶段训练提供了数据基础,推动了如多阶段训练管道等创新框架的发展,持续拓展着具身智能的研究边界。
以上内容由遇见数据集搜集并总结生成


