TOMATO
收藏Hugging Face2024-11-01 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/yale-nlp/TOMATO
下载链接
链接失效反馈官方服务:
资源简介:
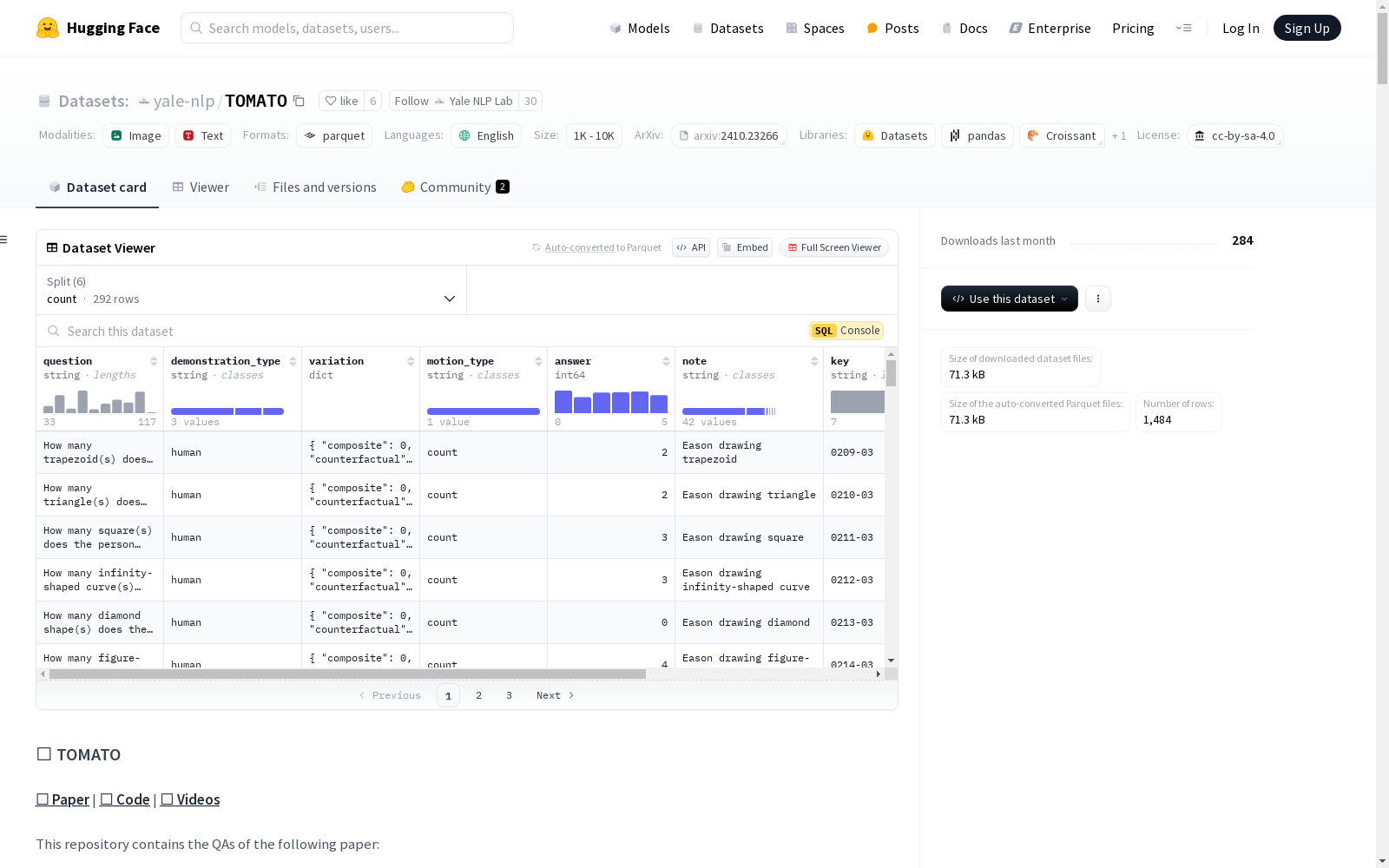
该数据集包含多个分割,每个分割对应不同的数据文件,如'count'、'direction'、'rotation'等。数据集的特征包括问题、演示类型、变化、运动类型、答案、注释、键、选项和视频源URL。数据集的总下载大小为71255字节,数据集大小为413638字节。
提供机构:
Yale NLP Lab
创建时间:
2024-11-01
原始信息汇总
TOMATO 数据集概述
数据集信息
- 许可证: CC BY-SA 4.0
- 配置:
- 默认配置
- 数据文件:
count:data/count-*direction:data/direction-*rotation:data/rotation-*shape_trend:data/shape_trend-*velocity_frequency:data/velocity_frequency-*visual_cues:data/visual_cues-*
数据集特征
- question: 字符串
- demonstration_type: 字符串
- variation: 结构体
- composite: 整数64位
- counterfactual: 整数64位
- first_person: 整数64位
- zoom: 整数64位
- motion_type: 字符串
- answer: 整数64位
- note: 字符串
- key: 字符串
- options: 字符串序列
- video_source_url: 字符串
数据集分割
- count:
- 字节数: 60102
- 样本数: 292
- direction:
- 字节数: 124629
- 样本数: 403
- rotation:
- 字节数: 92655
- 样本数: 286
- shape_trend:
- 字节数: 61447
- 样本数: 223
- velocity_frequency:
- 字节数: 57868
- 样本数: 210
- visual_cues:
- 字节数: 16937
- 样本数: 70
数据集大小
- 下载大小: 71255 字节
- 数据集大小: 413638 字节
搜集汇总
数据集介绍
构建方式
TOMATO数据集的构建基于对多模态基础模型(MFMs)视觉时序推理能力的系统性评估。研究者提出了三项原则及其对应指标:多帧增益、帧顺序敏感性和帧信息差异。基于这些原则,数据集包含了1,484个经过人工标注的问题,涵盖了6个任务类别,如动作计数、方向、旋转等。这些问题应用于1,417个视频,其中包括805个自录和生成的视频,涵盖了人类中心、现实世界和模拟三种场景。通过编辑视频,研究者引入了反事实场景、复合运动和放大视图,以探究这些特征对模型性能的影响。
使用方法
TOMATO数据集的使用方法包括下载视频文件、安装必要的依赖包以及运行评估脚本。用户可以通过克隆GitHub仓库并下载视频文件来获取数据集。评估脚本支持多种模型,包括开源模型和专有模型。用户可以通过命令行参数指定模型名称、推理类型和演示类型,并运行评估脚本以获取模型的性能结果。此外,数据集还提供了结果解析和分类评分功能,帮助用户更详细地分析模型的性能表现。
背景与挑战
背景概述
TOMATO数据集由耶鲁大学与艾伦人工智能研究所的研究团队于2024年推出,旨在评估多模态基础模型(MFMs)在视频理解中的视觉时序推理能力。该数据集由Ziyao Shangguan、Chuhan Li等研究人员主导开发,包含1,484个经过精心设计的人工标注问题,涵盖6个任务类别,如动作计数、方向识别、旋转检测等。这些问题基于1,417个视频,其中包括805个自录和生成的视频,涉及人类中心、现实世界和模拟场景。TOMATO的创建填补了现有基准在评估时序推理能力方面的不足,为多模态模型的研究提供了新的评估标准。
当前挑战
TOMATO数据集在构建过程中面临多重挑战。首先,视频数据的多样性和复杂性要求研究人员设计出能够全面评估模型时序推理能力的任务,这涉及到对视频帧的精细编辑,如反事实场景、复合运动和放大视图的引入。其次,数据标注的准确性至关重要,尤其是在处理复杂的时序推理问题时,确保每个问题的答案与视频内容的一致性需要大量的人工审核。此外,评估多模态模型在时序推理任务中的表现时,如何设计合理的评估指标以准确反映模型的真实能力,也是一个亟待解决的问题。这些挑战不仅体现在数据集的构建过程中,也影响了后续模型评估的准确性和可靠性。
常用场景
经典使用场景
TOMATO数据集主要用于评估多模态基础模型(MFMs)在视频理解中的视觉时序推理能力。通过精心设计的任务,如动作计数、方向判断、旋转识别、形状趋势分析、速度频率测量和视觉线索提取,TOMATO能够全面测试模型在处理复杂视频数据时的表现。这些任务涵盖了人类中心、真实世界和模拟场景,确保了对模型能力的广泛覆盖。
解决学术问题
TOMATO数据集解决了多模态基础模型在视觉时序推理任务中的评估难题。通过引入多帧增益、帧顺序敏感性和帧信息差异三个原则,TOMATO能够系统性地评估模型在处理连续帧数据时的能力。这不仅揭示了现有模型在时序推理上的局限性,还为未来的模型改进提供了明确的方向。
实际应用
在实际应用中,TOMATO数据集可以用于开发和优化智能视频分析系统,如自动驾驶、监控系统和人机交互界面。通过评估模型在复杂视频任务中的表现,TOMATO帮助提升这些系统在真实场景中的准确性和可靠性,从而推动相关技术的实际应用和商业化进程。
数据集最近研究
最新研究方向
在视觉时序推理领域,TOMATO数据集的引入为多模态基础模型(MFMs)的能力评估提供了新的基准。该数据集通过精心设计的任务和视频场景,系统地考察了模型在处理多帧信息、帧序敏感性和帧信息分布等方面的表现。近年来,随着视频理解技术的快速发展,TOMATO数据集的研究方向主要集中在如何提升模型对连续帧序列的理解能力,特别是在处理复杂运动、反事实场景和缩放视图等挑战性任务时的表现。这一研究不仅揭示了现有模型在时序推理上的局限性,也为未来模型的设计和优化提供了重要的参考依据。
以上内容由遇见数据集搜集并总结生成


