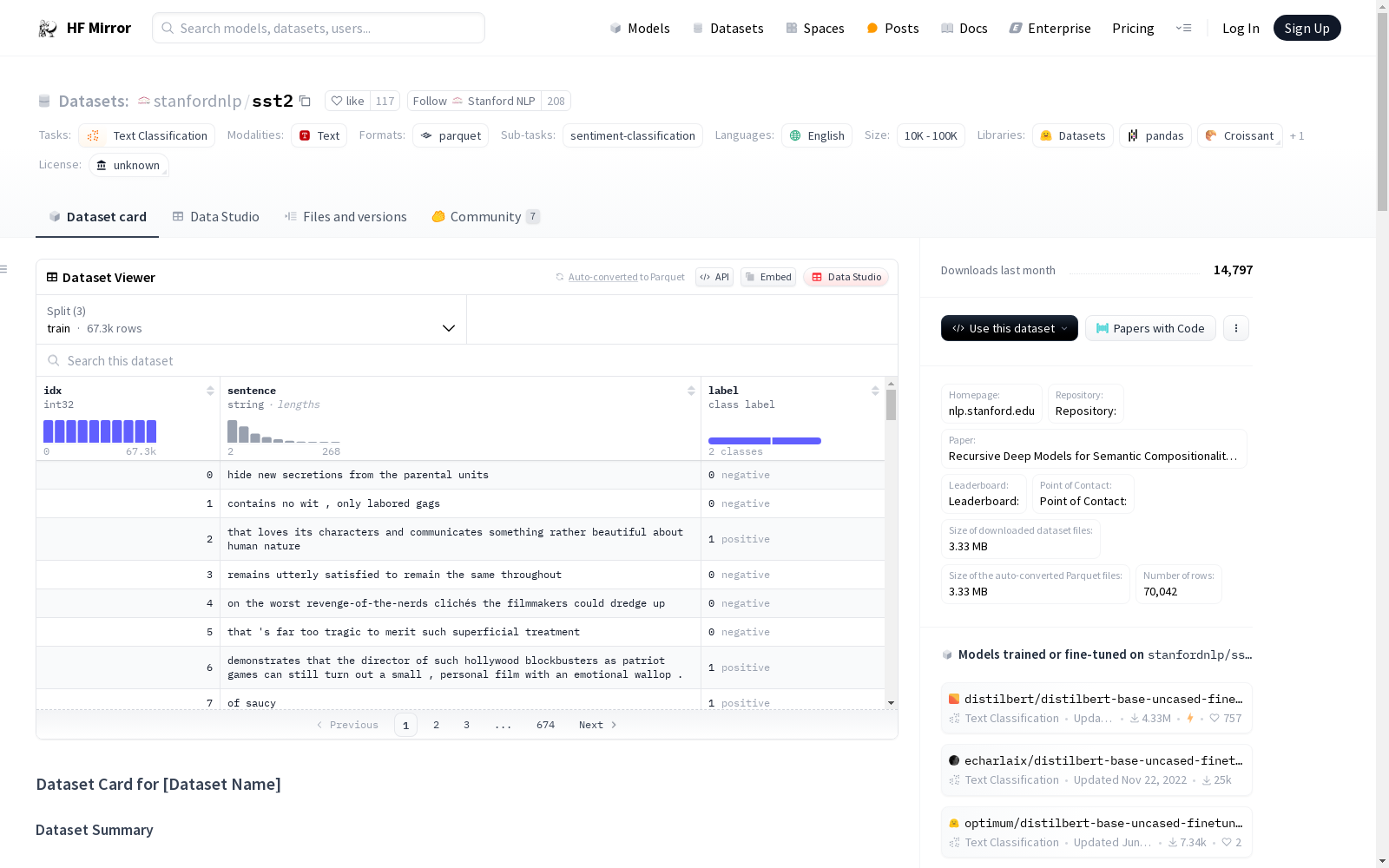
stanfordnlp/sst2
收藏Hugging Face2024-01-04 更新2024-04-19 收录
下载链接:
https://hf-mirror.com/datasets/stanfordnlp/sst2
下载链接
链接失效反馈资源简介:
---
annotations_creators:
- crowdsourced
language_creators:
- found
language:
- en
license:
- unknown
multilinguality:
- monolingual
size_categories:
- 10K<n<100K
source_datasets:
- original
task_categories:
- text-classification
task_ids:
- sentiment-classification
paperswithcode_id: sst
pretty_name: Stanford Sentiment Treebank v2
dataset_info:
features:
- name: idx
dtype: int32
- name: sentence
dtype: string
- name: label
dtype:
class_label:
names:
'0': negative
'1': positive
splits:
- name: train
num_bytes: 4681603
num_examples: 67349
- name: validation
num_bytes: 106252
num_examples: 872
- name: test
num_bytes: 216640
num_examples: 1821
download_size: 3331058
dataset_size: 5004495
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
---
# Dataset Card for [Dataset Name]
## Table of Contents
- [Table of Contents](#table-of-contents)
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** https://nlp.stanford.edu/sentiment/
- **Repository:**
- **Paper:** [Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank](https://www.aclweb.org/anthology/D13-1170/)
- **Leaderboard:**
- **Point of Contact:**
### Dataset Summary
The Stanford Sentiment Treebank is a corpus with fully labeled parse trees that allows for a complete analysis of the
compositional effects of sentiment in language. The corpus is based on the dataset introduced by Pang and Lee (2005)
and consists of 11,855 single sentences extracted from movie reviews. It was parsed with the Stanford parser and
includes a total of 215,154 unique phrases from those parse trees, each annotated by 3 human judges.
Binary classification experiments on full sentences (negative or somewhat negative vs somewhat positive or positive
with neutral sentences discarded) refer to the dataset as SST-2 or SST binary.
### Supported Tasks and Leaderboards
- `sentiment-classification`
### Languages
The text in the dataset is in English (`en`).
## Dataset Structure
### Data Instances
```
{'idx': 0,
'sentence': 'hide new secretions from the parental units ',
'label': 0}
```
### Data Fields
- `idx`: Monotonically increasing index ID.
- `sentence`: Complete sentence expressing an opinion about a film.
- `label`: Sentiment of the opinion, either "negative" (0) or positive (1). The test set labels are hidden (-1).
### Data Splits
| | train | validation | test |
|--------------------|---------:|-----------:|-----:|
| Number of examples | 67349 | 872 | 1821 |
## Dataset Creation
### Curation Rationale
[More Information Needed]
### Source Data
#### Initial Data Collection and Normalization
[More Information Needed]
#### Who are the source language producers?
Rotten Tomatoes reviewers.
### Annotations
#### Annotation process
[More Information Needed]
#### Who are the annotators?
[More Information Needed]
### Personal and Sensitive Information
[More Information Needed]
## Considerations for Using the Data
### Social Impact of Dataset
[More Information Needed]
### Discussion of Biases
[More Information Needed]
### Other Known Limitations
[More Information Needed]
## Additional Information
### Dataset Curators
[More Information Needed]
### Licensing Information
Unknown.
### Citation Information
```bibtex
@inproceedings{socher-etal-2013-recursive,
title = "Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank",
author = "Socher, Richard and
Perelygin, Alex and
Wu, Jean and
Chuang, Jason and
Manning, Christopher D. and
Ng, Andrew and
Potts, Christopher",
booktitle = "Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing",
month = oct,
year = "2013",
address = "Seattle, Washington, USA",
publisher = "Association for Computational Linguistics",
url = "https://www.aclweb.org/anthology/D13-1170",
pages = "1631--1642",
}
```
### Contributions
Thanks to [@albertvillanova](https://github.com/albertvillanova) for adding this dataset.
annotations_creators:
- 众包(crowdsourced)
language_creators:
- 公开采集(found)
language:
- 英语(en)
license:
- 未知
multilinguality:
- 单语言(monolingual)
size_categories:
- 10K<n<100K
source_datasets:
- 原创数据集(original)
task_categories:
- 文本分类(text-classification)
task_ids:
- 情感分类(sentiment-classification)
paperswithcode_id: sst
pretty_name: 斯坦福情感树库v2(Stanford Sentiment Treebank v2)
dataset_info:
features:
- name: idx
dtype: int32
- name: sentence
dtype: 字符串(string)
- name: label
dtype:
class_label:
names:
'0': 消极(negative)
'1': 积极(positive)
splits:
- name: train
num_bytes: 4681603
num_examples: 67349
- name: validation
num_bytes: 106252
num_examples: 872
- name: test
num_bytes: 216640
num_examples: 1821
download_size: 3331058
dataset_size: 5004495
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
- split: validation
path: data/validation-*
- split: test
path: data/test-*
# 数据集卡片 [数据集名称]
## 目录
- [目录](#目录)
- [数据集描述](#数据集描述)
- [数据集概述](#数据集概述)
- [支持任务与排行榜](#支持任务与排行榜)
- [语言](#语言)
- [数据集结构](#数据集结构)
- [数据实例](#数据实例)
- [数据字段](#数据字段)
- [数据划分](#数据划分)
- [数据集构建](#数据集构建)
- [构建初衷](#构建初衷)
- [源数据](#源数据)
- [注释](#注释)
- [个人与敏感信息](#个人与敏感信息)
- [数据使用注意事项](#数据使用注意事项)
- [数据集的社会影响](#数据集的社会影响)
- [偏差讨论](#偏差讨论)
- [其他已知局限性](#其他已知局限性)
- [附加信息](#附加信息)
- [数据集维护者](#数据集维护者)
- [授权信息](#授权信息)
- [引用信息](#引用信息)
- [贡献](#贡献)
## 数据集描述
- **主页**:https://nlp.stanford.edu/sentiment/
- **代码仓库**:
- **论文**:[面向情感树库语义组合性的递归深度模型](https://www.aclweb.org/anthology/D13-1170/)
- **排行榜**:
- **联系方式**:
### 数据集概述
斯坦福情感树库(Stanford Sentiment Treebank)是一套带有完整标注句法树的语料库,可用于全面分析语言中情感的组合效应。该语料库基于Pang与Lee(2005)提出的数据集构建,包含从电影评论中提取的11855条独立句子。语料使用斯坦福句法分析器进行句法分析,共包含来自这些句法树的215154个唯一短语,每个短语均由3名人类标注者进行注释。
针对完整句子的二分类实验(丢弃中性句子,将样本划分为"消极/偏消极"与"积极/偏积极"两类)将该数据集称为SST-2或SST二分类数据集。
### 支持任务与排行榜
- `情感分类(sentiment-classification)`
### 语言
数据集中的文本为英语(en)。
## 数据集结构
### 数据实例
{'idx': 0,
'sentence': 'hide new secretions from the parental units ',
'label': 0}
### 数据字段
- `idx`:单调递增的索引ID。
- `sentence`:表达对某部电影观点的完整句子。
- `label`:观点的情感倾向,分为"消极(0)"与"积极(1)"两类。测试集的标签被隐藏(值为-1)。
### 数据划分
| | 训练集 | 验证集 | 测试集 |
|--------------------|---------:|-----------:|-----:|
| 样本数量 | 67349 | 872 | 1821 |
## 数据集构建
### 构建初衷
[需更多信息]
### 源数据
#### 初始数据收集与标准化
[需更多信息]
#### 源语言生产者是谁?
烂番茄(Rotten Tomatoes)影评人。
### 注释
#### 注释流程
[需更多信息]
#### 标注者是谁?
[需更多信息]
### 个人与敏感信息
[需更多信息]
## 数据使用注意事项
### 数据集的社会影响
[需更多信息]
### 偏差讨论
[需更多信息]
### 其他已知局限性
[需更多信息]
## 附加信息
### 数据集维护者
[需更多信息]
### 授权信息
未知。
### 引用信息
bibtex
@inproceedings{socher-etal-2013-recursive,
title = "面向情感树库语义组合性的递归深度模型",
author = "Socher, Richard 与
Perelygin, Alex 与
Wu, Jean 与
Chuang, Jason 与
Manning, Christopher D. 与
Ng, Andrew 与
Potts, Christopher",
booktitle = "2013年自然语言处理经验方法会议论文集",
month = oct,
year = "2013",
address = "美国华盛顿州西雅图",
publisher = "国际计算语言学协会",
url = "https://www.aclweb.org/anthology/D13-1170",
pages = "1631--1642",
}
### 贡献
感谢 [@albertvillanova](https://github.com/albertvillanova) 添加本数据集。
提供机构:
stanfordnlp
原始信息汇总
数据集概述
数据集名称
- Pretty Name: Stanford Sentiment Treebank v2
- Paperswithcode ID: sst
数据集描述
- 语言: 英语 (
en) - 许可证: 未知
- 多语言性: 单语种
- 大小类别: 10K<n<100K
- 源数据集: 原始数据
- 任务类别: 文本分类
- 任务ID: 情感分类 (
sentiment-classification)
数据集结构
-
数据实例:
{idx: 0, sentence: hide new secretions from the parental units , label: 0}
-
数据字段:
idx: 单调递增的索引ID。sentence: 关于电影的完整意见表达句子。label: 意见的情感,分为“负面”(0) 或 “正面”(1)。
-
数据分割:
分割 训练 验证 测试 示例数 67349 872 1821
数据集创建
- 源语言生产者: Rotten Tomatoes 评论者
- 许可证信息: 未知
- 引用信息: bibtex @inproceedings{socher-etal-2013-recursive, title = "Recursive Deep Models for Semantic Compositionality Over a Sentiment Treebank", author = "Socher, Richard and Perelygin, Alex and Wu, Jean and Chuang, Jason and Manning, Christopher D. and Ng, Andrew and Potts, Christopher", booktitle = "Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing", month = oct, year = "2013", address = "Seattle, Washington, USA", publisher = "Association for Computational Linguistics", url = "https://www.aclweb.org/anthology/D13-1170", pages = "1631--1642", }
搜集汇总
数据集介绍
构建方式
斯坦福情感树库(Stanford Sentiment Treebank)的构建,基于电影评论中的单句提取,运用斯坦福解析器进行句法分析,并形成带有完整标注的解析树。该数据集包含11,855个单句,并从中提取出215,154个独特短语,这些短语由三位人类评判员进行情感标注,形成了一个深入分析情感在语言中组合效应的语料库。
特点
本数据集的主要特点是提供了一个二分类的情感标注,即将句子情感分为消极和积极两种,中性句子被排除在外。数据集采用单语种英文构建,且数据规模适中,便于在情感分类任务中进行有效的模型训练与评估。此外,其标注质量经过多轮人工审核,具有较高的准确性。
使用方法
使用该数据集时,用户可以根据提供的训练集、验证集和测试集进行模型训练与测试。数据集以JSON格式存储,其中包含索引ID、句子文本和情感标签。用户需注意,测试集的情感标签是隐藏的,仅用于最终模型性能的评估。在应用前,需确保对数据集结构有清晰的了解,并遵循相应的数据处理和模型训练流程。
背景与挑战
背景概述
斯坦福情感树库(Stanford Sentiment Treebank,简称SST)是由斯坦福大学研究人员创建的一个具有完整标注句法树的语料库,旨在对语言中情感组合效应进行彻底分析。该数据集基于Pang和Lee于2005年引入的数据集,包含从电影评论中提取的11,855个单句,经斯坦福句法分析器解析,并包含215,154个来自句法树的独特短语,每个短语均由三个人类评判员进行标注。SST-2或SST二分类实验针对完整句子进行二元分类(消极与积极),其中中性句子被排除。该数据集自发布以来,在情感分析领域产生了广泛的影响,为研究人员提供了一种评估情感分类模型性能的标准方法。
当前挑战
在构建SST数据集的过程中,研究人员面临了多方面的挑战。首先,确保标注的质量和一致性是一项重要任务,因为这涉及到多个评判员对短语情感的一致性标注。其次,数据集的构建过程中需要处理大量的文本数据,并进行有效的数据清洗和预处理。此外,数据集在应用中面临的挑战包括如何处理情感表达的复杂性,以及如何将模型泛化到更广泛的情感分析任务中。在领域问题上,SST数据集解决的挑战是如何准确地从文本中提取情感倾向,尤其是在面对细微情感差异和复杂语言结构时。
常用场景
经典使用场景
在自然语言处理领域,斯坦福情感树库v2(Stanford Sentiment Treebank v2)数据集被广泛用于情感分析的研究。其经典的使用场景在于,研究者利用该数据集对电影评论进行二分类任务,即将评论区分为负面或正面情感,进而深入探讨语言中情感组成的构造效应。
实际应用
在实际应用中,斯坦福情感树库v2数据集被用于训练机器学习模型,以自动识别文本中的情感倾向,广泛应用于在线口碑分析、市场情绪监测、客户服务等领域,对企业的决策提供了有力的数据支持。
衍生相关工作
基于该数据集,学术界衍生出了一系列相关工作,包括但不限于对情感树库的扩展、不同语言的情感分析模型构建、以及针对特定领域的情感分析研究,这些都极大地推动了情感分析领域的发展。
以上内容由遇见数据集搜集并总结生成


