cultural_paper
收藏Hugging Face2025-11-27 更新2025-11-28 收录
下载链接:
https://huggingface.co/datasets/Josefine245/cultural_paper
下载链接
链接失效反馈官方服务:
资源简介:
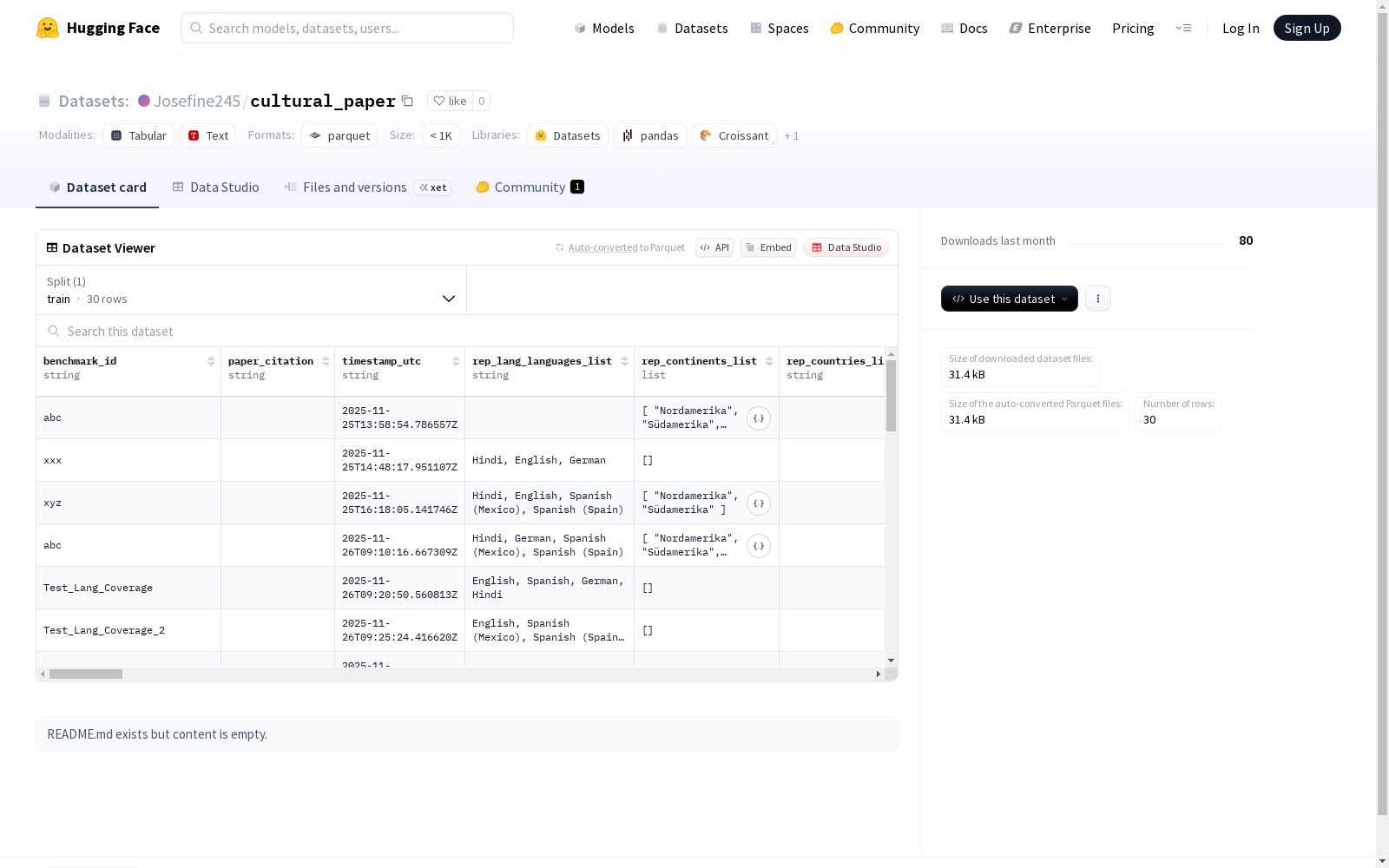
该数据集包含多个特征,如benchmark_id、paper_citation等,涵盖语言、地区、群体、理论来源、文化元素等方面。数据集分为训练集,包含24个示例,总大小为7024字节。数据集还包含了关于文化定义、文化概念基础、偏见意识等方面的信息,以及一些数据质量和注释质量的相关字段。
创建时间:
2025-11-24
原始信息汇总
数据集概述
基本信息
- 数据集名称: cultural_paper
- 存储位置: https://huggingface.co/datasets/Josefine245/cultural_paper
- 数据量: 24个样本
- 数据集大小: 7,024字节
- 下载大小: 30,632字节
- 数据格式: 结构化表格
数据结构
数据集包含以下主要特征字段:
标识信息
- benchmark_id: 基准标识符
- paper_citation: 论文引用信息
- timestamp_utc: 时间戳
文化代表性信息
- rep_lang_languages_list: 代表语言列表
- rep_continents_list: 代表大洲列表
- rep_countries_list: 代表国家列表
- rep_dialects: 代表方言
- rep_scripts: 代表文字
- rep_underserved_groups_flag: 弱势群体标识
- rep_underserved_groups_list: 弱势群体列表
- rep_theory_based: 理论基础
- rep_theory_sources: 理论来源
- rep_country_vs_culture: 国家与文化对比
文化主题分类
- cult_overall_topics: 总体主题
- cult_values: 价值观
- cult_religion: 宗教
- cult_social_norms: 社会规范
- cult_narratives: 叙事
- cult_popculture: 流行文化
- cult_symbols: 符号
- cult_rituals: 仪式
- cult_clothing: 服饰
- cult_food_routines: 饮食惯例
- cult_holidays: 节日
- cult_topics_num: 主题数量
- cult_topics_list: 主题列表
- cult_topics_balance_reflected: 主题平衡反映
- cult_topics_justified: 主题合理性
- cult_topics_sources: 主题来源
数据收集与处理
- data_question_types: 问题类型
- data_doc_process_documented: 文档处理记录
- data_creation_mode: 数据创建模式
- data_creation_methods: 数据创建方法
- data_selection_sources_documented: 数据选择来源记录
- data_selection_external_refs: 数据选择外部参考
- data_selection_external_refs_list: 数据选择外部参考列表
- data_filtering_cleaned: 数据过滤清理
- data_quality_checked: 数据质量检查
- answers_checked: 答案检查
标注信息
- ann_annotators_involved: 标注者参与情况
- ann_annotators_selection_documented: 标注者选择记录
- ann_requirements_defined: 标注要求定义
- ann_cultural_relevance: 文化相关性
- ann_diversity_balance: 多样性平衡
- ann_recruitment_described: 招募描述
- ann_recruitment_channels: 招募渠道
- ann_fair_compensation: 公平补偿
- ann_guidelines_exist: 标注指南存在性
- ann_quality_control: 质量控制
- ann_quality_control_methods: 质量控制方法
文化定义与理论基础
- cult_def_defined: 文化定义
- cult_def_depth: 文化定义深度
- cult_def_literature: 文化定义文献
- cult_def_literature_sources: 文化定义文献来源
- cult_conceptual_foundation: 概念基础
偏见与透明度
- bias_awareness: 偏见意识
- bias_mitigation_measures: 偏见缓解措施
- bias_fairness_inclusivity: 偏见公平包容性
- transparency_dataset_available: 数据集透明度
- transparency_limitations_reflected: 局限性反映
评分信息
- raw_score: 原始分数
- max_score: 最高分数
- normalized_score: 标准化分数
数据配置
- 配置名称: default
- 数据分割: train(训练集)
- 文件路径: data/train-*
搜集汇总
数据集介绍
构建方式
在文化计算研究领域,cultural_paper数据集通过系统化收集学术文献元数据构建而成。该数据集整合了来自多篇论文的文化特征标注,涵盖语言、地域、社会群体等维度,并采用标准化字段记录每篇文献的文化主题分类、理论依据及数据来源。构建过程中注重文献筛选的透明度,通过引用外部参考文献和理论框架来确保数据来源的可靠性,同时保留了原始文献的时间戳和引用信息以维持时序一致性。
特点
cultural_paper数据集展现出多维文化表征的独特结构,其核心特征体现在对文化要素的细粒度编码。数据集通过数值化字段量化了宗教、社会规范、节日习俗等十余类文化主题的覆盖程度,并采用列表结构记录语言变体、地域分布等多元文化属性。特别值得注意的是,该数据集包含对边缘文化群体的标识字段,以及文化理论来源的文本描述,为分析文化研究的理论根基提供了直接依据。
使用方法
该数据集适用于文化计算与跨文化研究的实证分析,研究者可通过标准化字段进行多维检索与对比研究。典型应用场景包括:基于文化主题数值字段进行聚类分析,探索不同地域文化研究的侧重点;利用语言列表和地域字段开展跨文化比较研究;结合时间戳字段分析文化研究热点的历时演变。数据集的归一化评分字段还可用于量化评估文化研究的深度与广度,为文献计量学研究提供结构化数据支撑。
背景与挑战
背景概述
在跨文化计算语言学蓬勃发展的背景下,cultural_paper数据集应运而生。该数据集由国际研究团队构建,聚焦于文化表征与自然语言处理的交叉领域,核心在于量化评估学术文献中的文化多样性表征质量。通过系统化标注论文中涉及的语言、地域、文化符号等维度,该资源为衡量人工智能模型的文化包容性提供了基准框架,显著推动了算法公平性研究的实证化进程。
当前挑战
该数据集致力于解决文化维度建模中的表征偏差难题,其核心挑战在于如何定义可量化的文化评估指标。构建过程中面临多重障碍:文化概念的高度抽象性导致标注标准难以统一,不同文明语境下的符号系统需要专家参与解析,而数据稀疏性则限制了模型的泛化能力。此外,确保弱势群体文化特征的平衡表征,需克服语料收集的地理分布不均问题。
常用场景
经典使用场景
在跨文化计算语言学领域,cultural_paper数据集为评估文化表征的完整性提供了标准化框架。该数据集通过系统化标注文化维度(如价值观、宗教、社会规范等),支持研究者量化分析学术文献中的文化覆盖度,常用于训练文化感知的自然语言处理模型,以提升模型对多元文化背景的理解能力。
解决学术问题
该数据集有效解决了文化计算研究中表征不平衡的核心问题。通过结构化记录语言、地域、文化主题等维度,为量化文化偏见提供了实证基础,推动建立更具包容性的算法评估标准。其标准化指标体系显著促进了跨文化NLP领域的理论构建与方法论创新。
衍生相关工作
基于该数据集衍生的经典研究包括文化偏见检测框架CULTURALBias、跨语言模型适配技术CULTURE-Adapter等。这些工作通过扩展数据集的标注体系,发展了文化维度量化方法,并催生了国际文化计算研讨会等学术交流机制。
以上内容由遇见数据集搜集并总结生成


