FlatSounds
收藏arXiv2026-05-29 更新2026-05-30 收录
下载链接:
https://research.nvidia.com/labs/cosmos-lab/flatsounds/
下载链接
链接失效反馈官方服务:
资源简介:
FlatSounds是由加州大学伯克利分校、英伟达和华盛顿大学联合创建的用于视频到音频生成物理基准测试的数据集,包含185条精心录制的室内视频片段,每条时长5至10秒,聚焦于日常物体交互产生的高能量声音事件。数据集通过智能手机采集,涵盖了材料、几何形状、环境等多种物理因素的受控变化,并提供了人工标注的事件时间戳和文本描述。该数据集旨在评估生成模型对物理过程的因果理解能力,而非表面合理性,为视频到音频模型的物理正确性和时间对齐性提供了系统化的测试框架。
FlatSounds is a physics benchmark dataset for video-to-audio generation, co-created by the University of California, Berkeley, NVIDIA, and the University of Washington. It contains 185 meticulously recorded indoor video clips, each with a duration of 5 to 10 seconds, focusing on high-energy acoustic events generated by interactions between everyday objects. The dataset is collected using smartphones, covering controlled variations of multiple physical factors including materials, geometries, and ambient environments, and provides manually annotated event timestamps and textual descriptions. This dataset is designed to evaluate the causal understanding of physical processes by generative models rather than superficial plausibility, offering a systematic test framework for assessing the physical correctness and temporal alignment of video-to-audio models.
提供机构:
加州大学伯克利分校; 英伟达; 华盛顿大学
创建时间:
2026-05-29
原始信息汇总
数据集概述:FlatSounds
FlatSounds 是一个用于评估视频到音频(V2A)生成模型物理推理能力的基准数据集。该研究发表于 CVPR 2026,由 NVIDIA Cosmos Lab 团队提出。
核心目标
揭示当前 V2A 模型是否真正理解声音产生的物理过程,而非仅生成“听起来合理”的音频。研究表明,现有模型更依赖文本描述而非视觉线索来推断物理属性与语义,并在此过程中牺牲了时间对齐精度。
数据集设计
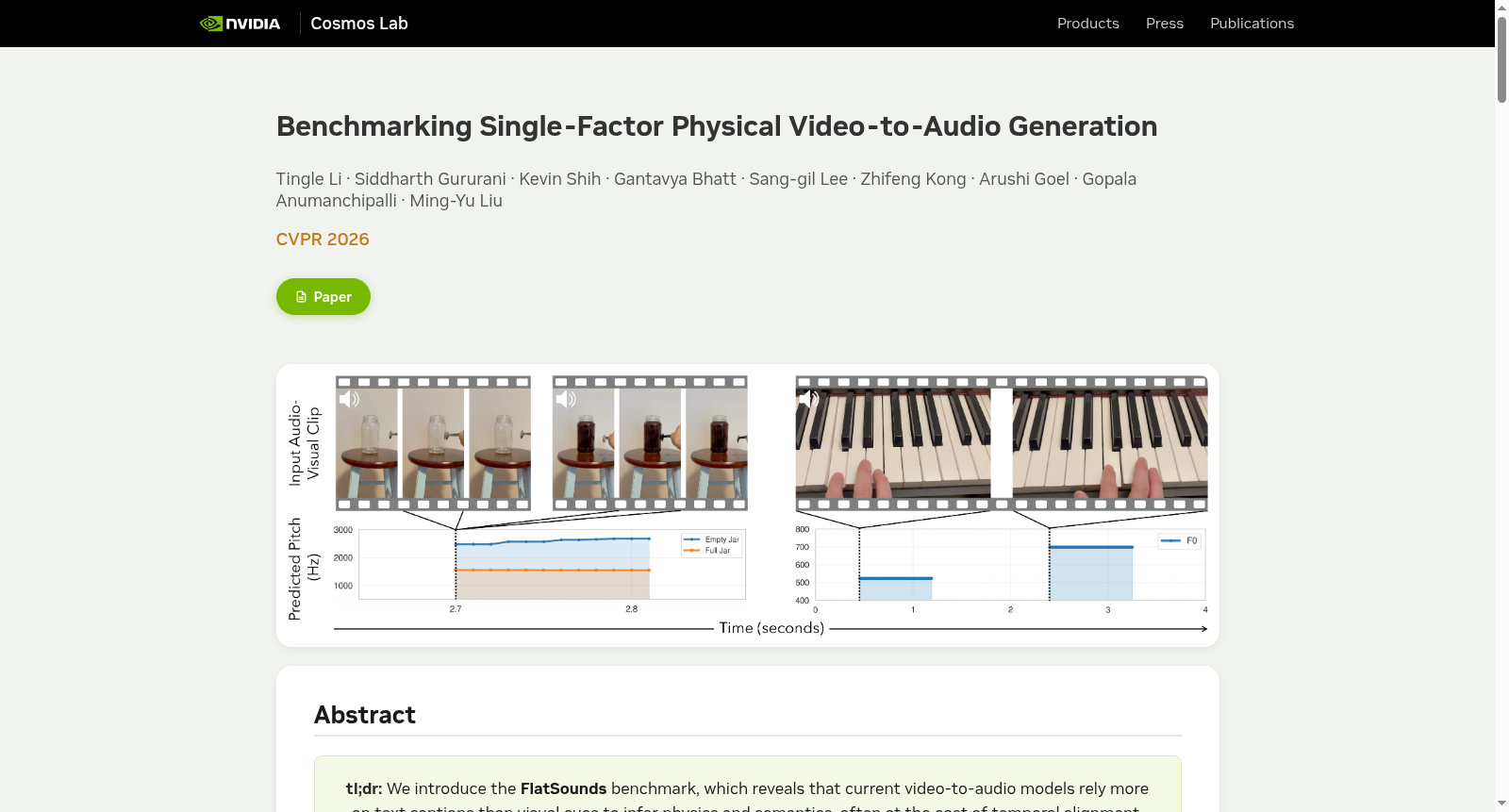
- 受控反事实对:由单一物理因素变化的时间对齐视频对组成,用于隔离特定因素的声学效应。
- 案例1(Jar Fullness):玻璃罐从空到满,物理上质量增加降低共振频率(音高 F0 降低)。
- 案例2(Damping):金属棍从自由悬挂变为表面约束,物理上阻尼增加导致衰减加快、音色变暗(频谱质心降低,衰减率升高)。
- 案例3(Environment):声学环境从走廊变为软垫房间,物理上混响时间(RT60)缩短、直达声与混响声比(DRR)升高。
- 单视频模式测试:用于探测模型内部一致性与方向性趋势。
- 案例4(Piano Key Position):手在键盘上向右移动时,音高(F0)必须严格单调递增。
数据集内容
- 额外反事实对示例:
- Scraping Surface:刮擦表面从纸板变为金属,预期金属产生更明亮刺耳的声音(频谱质心、通量、滚降升高)。
- Surface Texture:表面纹理从木地板变为地毯,预期地毯产生更柔和沉闷的声音(频谱质心、滚降降低,衰减率升高)。
- Striker Material:敲击物从金属勺变为木棍,预期木棍产生更柔和的起音与较暗音色(起音时间升高,频谱质心、滚降低)。
- 生成音频样本:提供来自多个SOTA V2A模型(FoleyCrafter、Hunyuan-V2A、MMAudio-Phys、MMAudio、ThinkSound)在有/无文本描述条件下的生成结果,供用户比较。
评估指标
- 物理音频属性:
- 起音时间(Attack Time)、衰减率(Decay Rate)、音高(F0)、频谱质心(Spectral Centroid)、频谱通量(Spectral Flux)、频谱滚降(Spectral Rolloff)、时域调制(Temporal Modulation)、混响时间(RT60)、直达声与混响声比(DRR)。
- 权衡分析:可视化“时间对齐”(Temporal Alignment)与“物理-语义保真度”(Physical-Semantic Fidelity)之间的权衡。发现添加文本描述虽提升物理与语义准确度,但普遍导致时间对齐退化。
关键发现
- 模型在推理物理过程时,对文本描述的依赖性超过对视觉流的利用。
- 基于物理的评估指标与人类偏好测试具有很强的相关性。
引用
bibtex @inproceedings{li2026flatsounds, title={Benchmarking Single-Factor Physical Video-to-Audio Generation}, author={Li, Tingle and Gururani, Siddharth and Shih, Kevin and Bhatt, Gantavya and Lee, Sang-gil and Kong, Zhifeng and Goel, Arushi and Anumanchipalli, Gopala and Liu, Ming-Yu}, booktitle={IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year={2026} }
数据集链接
- 主页:https://research.nvidia.com/labs/cosmos-lab/flatsounds/
搜集汇总
数据集介绍
构建方式
FlatSounds数据集通过精心设计的室内录制流程构建,采集了185段时长5至10秒的短视频片段,聚焦于日常物品(如罐子、餐具、乐器)间以撞击和摩擦为主的物理交互。录制过程中,每个片段均配备人工撰写的文字描述和精确到毫秒级的声音事件时间戳。为支持因果干预分析,研究者利用时间扭曲技术,将多个视频片段配组成反事实对,确保在仅改变单一物理因素(如材质、容器满度、环境声学特性)的同时,保持撞击时序的一致性。此外,数据集还包含了用于单视频模式测试的片段,例如重复敲击或音阶升降序列,从而为评估模型对物理规律的内在理解提供了结构化的测试框架。
使用方法
使用FlatSounds时,研究者需将待评估的视频到音频模型,分别在带文字描述和无文字描述的条件下,对数据集中的反事实对和单视频测试片段进行推理。生成的音频将通过两套指标进行评估:时序对齐指标(如命中覆盖率、时序误差)衡量声音事件与视觉动作的同步精度;物理正确性指标则通过计算每个测试种子在预期物理变化方向上的加权投票置信度来量化。特别地,对于反事实对,需确保生成音频在时序上对齐后,比较其物理度量的变化方向是否与标注一致。该流程支持统计显著性检验,并允许使用软门控机制滤除低质量生成样本的影响,从而提供对模型物理推理能力的稳健且解释性强的评估。
背景与挑战
背景概述
FlatSounds 数据集由加州大学伯克利分校、英伟达及华盛顿大学的研究人员于2026年共同创建,旨在系统审计视频到音频生成模型对物理世界的理解程度。现有评估体系过度依赖感知真实性与语义相关性指标,忽视了模型是否真正捕捉了声音产生的物理因果机制。该数据集聚焦室内日常物体碰撞场景,通过精心设计的185段视频及178组反事实对,构建了首个将物理正确性作为核心评估维度的基准。其影响力在于揭示了当前顶尖模型在缺乏文本提示时物理推理能力的显著不足,为领域指明了从表面逼真度迈向深层物理建模的关键方向。
当前挑战
该数据集面临的核心挑战包含两方面:其一,现有视频到音频生成模型普遍依赖文本提示来推断物理属性,视觉编码器未能从像素中习得诸如材料、填充度等物理因子变化对应的声学差异,导致无文本条件下的物理正确性置信度普遍低于0.31。其二,数据构建过程中需精心制作时间对齐的反事实对,通过时间扭曲技术精准对齐撞击时刻以隔离单一物理变量,这对视频帧率与音频采样率的同步精度提出了极高要求。此外,高混响环境下的声学参数估计、金属延音导致的误峰检测等信号处理难题,均需开发鲁棒的半自动标注流程与统计验证方法来克服。
常用场景
经典使用场景
FlatSounds视频到音频(V2A)生成基准数据集,其最经典的使用场景是评估生成模型在面对单一物理因素变化时的因果响应能力。该数据集精心设计了时间对齐的反事实视频对,其中仅改变一个物理变量(如材质、容器充盈度或环境混响),同时确保撞击时间精确对齐。通过这种方式,FlatSounds能够系统性地测试模型是否真正捕捉到了物理过程,即当视频中从金属变为木头时,生成的音频是否表现出预期的音高或频谱质心变化,从而审计模型对物理世界的隐式理解。
解决学术问题
该数据集解决了当前视频到音频生成领域评估标准缺失的关键问题。现有方法主要依赖感知真实性和语义相关性指标(如FAD和CLAP),这些指标捕捉的是表面层面的合理性,而非深层的物理因果理解。FlatSounds通过引入受控的反事实干预和单视频内部一致性测试,填补了评估模型因果响应能力的空白。其研究揭示了当前顶尖模型普遍存在的一个根本性权衡:文本描述虽能提升语义准确性,却意外地损害了时间对齐精度,暴露出视频编码器在从像素中学习物理过程方面的核心缺陷。这一发现重塑了领域内的挑战认知——重心应从提升音频合成质量转向构建能内化物理信息的视觉表征。
实际应用
在实际应用层面,FlatSounds为构建真正具身化的智能系统提供了关键评估工具。例如,机器人操作任务中,智能体需要根据视觉输入生成与物理交互一致的触觉反馈声,如判断容器是否装满、材料是软还是硬;在影视后期制作与虚拟现实领域,该系统能够辅助自动为无声视频生成物理上可信的音效,如根据画面中物体材质和动作力度自动调整敲击声的音高与衰减特性。此外,在教育与游戏领域,该数据集驱动的模型可实时生成符合物理规律的声音反馈,提升沉浸感的真实性与教学的有效性。
数据集最近研究
最新研究方向
FlatSounds数据集的引入标志着视频到音频生成领域从表面合理性评估向物理因果推理评估的重要范式转变。该基准通过精心设计的反事实视频对与单视频模式测试,系统性地审视了当前前沿模型对碰撞材料、容器充盈度、环境混响等单一物理变量的因果响应能力。实验揭示了一个核心悖论:现代V2A模型尽管在文本描述辅助下能生成语义准确的音频,但其物理正确性(置信度普遍低于0.31)严重依赖文本捷径,而非从像素中真正习得物理规律;更关键的是,这种对文本的依赖反而以牺牲时间对齐精度为代价。这一发现深刻指出当前视频编码器的根本性缺陷——它们无法内化视觉物理过程,从而推动研究重心从提升音频合成质量转向构建能够直接从像素中学习物理原理的视觉表征,为构建真正的具身世界模型开辟了关键路径。
相关研究论文
- 1Benchmarking Single-Factor Physical Video-to-Audio Generation加州大学伯克利分校; 英伟达; 华盛顿大学 · 2026年
以上内容由遇见数据集搜集并总结生成


