DNASpeech
收藏github2024-06-08 更新2024-07-03 收录
下载链接:
https://github.com/DNASpeech/DNASpeech
下载链接
链接失效反馈官方服务:
资源简介:
DNASpeech是一个新颖的文本到语音数据集,包含高质量的演讲和DNA提示注释(对话上下文、叙事和动作状态)。该数据集包含2,395个不同角色、4,4529个场景和22,975个对话话语,以及超过18小时的高质量语音录音,为文本到语音任务提供了更详细的描述。
DNASpeech is a novel text-to-speech dataset containing high-quality speech content and DNA prompt annotations (dialogue context, narration and action states). This dataset includes 2,395 distinct characters, 44,529 scenarios, 22,975 conversational utterances, and over 18 hours of high-quality speech recordings, providing more detailed contextual descriptions for text-to-speech tasks.
创建时间:
2024-06-06
原始信息汇总
DNASpeech 数据集概述
DNASpeech 是一个新颖的文本到语音数据集,包含高质量的语音,带有 DNA 提示注释(D对话上下文、N叙述和A动作状态)。该数据集包含 2,395 个不同的角色、4,4529 个场景和 22,975 个对话话语,以及超过 18 小时的高质量语音录音。
数据集文件
数据集可通过以下链接下载,包含三个文件:
- DNASpeech_meta.json:584MB,包含语音的元数据。
- DNASpeech_wav.zip:2.9GB,去噪后的语音数据。
- DNASpeech_raw.zip:6.9GB,原始语音数据。
元数据文件
DNASpeech_meta.json 是 JSON 行格式,包含 22,975 行。每行代表一个样本,包含以下字段:
- index:样本的唯一键,格式为 SpeakerID-MovieID-LineID,也作为相应语音片段的文件名。
- scene:包含场景标题和完整内容。
- character:说话者名称。
- timestamp:语音片段在电影中的开始和结束时间戳。
- narrative:语音的环境描述。
- dialogue:语音的对话上下文。
- action_state:说话者的动作、表情或额外信息。
- text:语音的内容文本。
- ASR_text:使用 ASR 技术转录的文本。
- score:数据质量的手动评估,从 1 到 3。
音频文件
DNASpeech_wav 包含去噪后的音频文件,对应每个样本,共有 22,975 个文件,每个文件包含一个语音片段。所有文件为 wav 格式,采样率为 16K HZ。文件名格式为 SpeakerID-MovieID-LineID,对应元数据中的 index 字段。
许可证
所有数据根据 CC BY-NC-SA 4.0 许可证 分发。
搜集汇总
数据集介绍
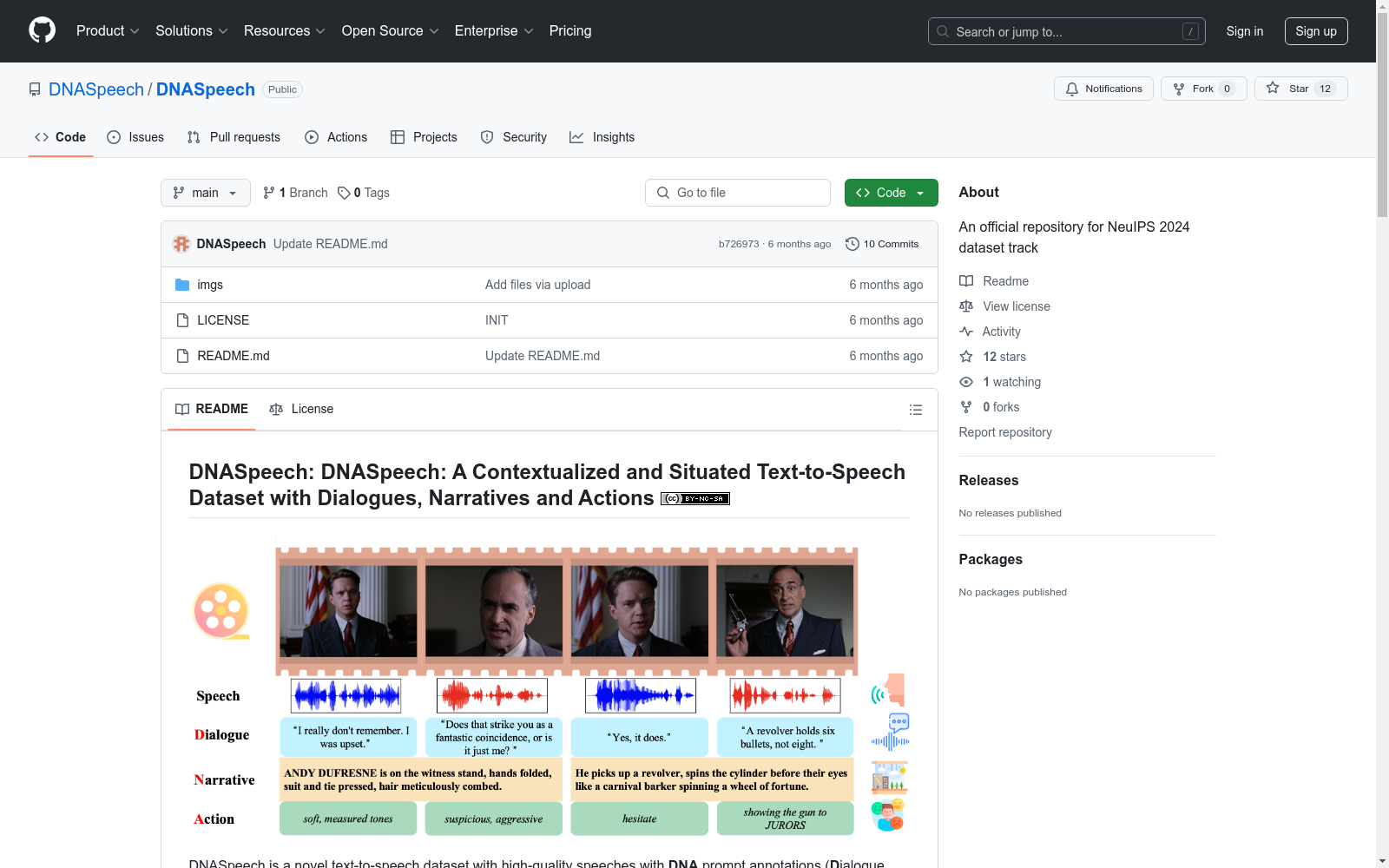
构建方式
DNASpeech数据集的构建基于丰富的对话、叙事和动作状态的上下文信息,通过精心挑选和标注,形成了包含2,395个独特角色、4,4529个场景和22,975个对话片段的高质量语音数据集。该数据集不仅收录了超过18小时的语音录音,还通过详细的元数据文件(DNASpeech_meta.json)对每个语音片段进行了细致的描述,包括场景、角色、时间戳、叙事、对话和动作状态等多维度信息。这种多层次的标注方式,使得DNASpeech成为文本到语音任务中一个极具价值的资源。
使用方法
使用DNASpeech数据集时,用户首先需通过提供的链接下载数据集文件,其中包括DNASpeech_meta.json、DNASpeech_wav.zip和DNASpeech_raw.zip。DNASpeech_meta.json文件包含了所有语音样本的元数据,用户可以通过解析该文件获取详细的上下文信息。DNASpeech_wav.zip和DNASpeech_raw.zip分别包含去噪和原始的语音文件,用户可根据研究需求选择合适的版本。数据集的使用需遵循CC BY-NC-SA 4.0许可协议,并需提前联系数据集维护者以获取授权。
背景与挑战
背景概述
DNASpeech数据集是由一组研究人员和机构在近期创建的,专注于文本到语音转换领域。该数据集包含了2,395个独特的角色、4,4529个场景和22,975个对话片段,以及超过18小时的高质量语音录音。DNASpeech通过提供详细的对话上下文、叙事和动作状态注释,显著提升了文本到语音任务的复杂性和真实性。这一数据集的推出,不仅丰富了现有的语音合成资源,还为研究者提供了一个更为细致和多维度的数据平台,从而推动了语音合成技术的发展。
当前挑战
DNASpeech数据集在构建过程中面临了多重挑战。首先,数据集的规模和复杂性要求高精度的语音识别和文本转录技术,以确保数据的准确性和一致性。其次,由于涉及大量的对话和场景,如何有效地标注和分类这些数据成为了一个技术难题。此外,保护个人隐私和防止数据滥用也是该数据集必须面对的重要问题。为了应对这些挑战,数据集的创建者采取了严格的数据匿名化和访问控制措施,确保数据的安全性和合法使用。
常用场景
经典使用场景
DNASpeech数据集在文本到语音(TTS)任务中展现了其独特的应用价值。通过整合对话上下文、叙事背景和动作状态的详细标注,该数据集为研究人员提供了丰富的语境信息,从而显著提升了语音合成的自然度和准确性。例如,在多轮对话系统中,DNASpeech能够帮助模型更好地理解对话的动态变化,生成更加连贯和符合语境的语音输出。
解决学术问题
DNASpeech数据集解决了传统TTS系统中语境信息缺失的问题,为学术界提供了一个全新的研究平台。通过引入对话上下文、叙事背景和动作状态的标注,该数据集使得研究人员能够探索如何在语音合成中更好地融入语境信息,从而提升语音的自然度和情感表达。这一创新不仅推动了TTS技术的发展,也为相关领域的研究提供了宝贵的数据资源。
实际应用
在实际应用中,DNASpeech数据集被广泛应用于智能语音助手、虚拟人物和教育培训等领域。例如,在智能语音助手中,该数据集帮助系统更好地理解用户的指令和对话上下文,提供更加个性化和自然的语音反馈。在虚拟人物的开发中,DNASpeech使得虚拟角色的语音输出更加符合其角色设定和情感状态,增强了用户体验。
数据集最近研究
最新研究方向
在自然语言处理与语音合成领域,DNASpeech数据集的最新研究方向主要集中在利用其丰富的上下文信息和情境标注来提升文本到语音(TTS)系统的性能。研究者们致力于通过整合对话上下文、叙事背景和动作状态等多维度信息,增强TTS系统对复杂语境的理解和表达能力。此外,该数据集的高质量语音记录和详细的元数据为研究个性化语音合成、情感识别和多模态交互提供了宝贵的资源。这些研究不仅推动了TTS技术的进步,也为虚拟助手、教育工具和娱乐应用等领域带来了新的可能性。
以上内容由遇见数据集搜集并总结生成


