cfilt/IITB-IndicMonoDoc
收藏Hugging Face2025-02-18 更新2024-06-11 收录
下载链接:
https://hf-mirror.com/datasets/cfilt/IITB-IndicMonoDoc
下载链接
链接失效反馈资源简介:
这是一个包含22种印度计划语言和英语的单语种文档级语料库,总共有39518.51百万个标记。语料库包括的语言有:阿萨姆语、孟加拉语、古吉拉特语、印地语、卡纳达语、克什米尔语、贡根语、马拉雅拉姆语、曼尼普尔语、马拉地语、尼泊尔语、奥里亚语、旁遮普语、梵语、信德语、泰米尔语、泰卢固语、乌尔都语、博多语、桑塔利语、迈蒂利语和 Dogri 语。
This is a monolingual document-level corpus for 22 scheduled languages of India plus English, totaling 39518.51 million tokens. The corpus includes the following languages: Assamese, Bengali, Gujarati, Hindi, Kannada, Kashmiri, Konkani, Malayalam, Manipuri, Marathi, Nepali, Oriya, Punjabi, Sanskrit, Sindhi, Tamil, Telugu, Urdu, Bodo, Santhali, Maithili, and Dogri.
提供机构:
cfilt
原始信息汇总
数据集概述
数据集名称
IITB Document level Monolingual Corpora for Indian languages
包含语言
- 主要语言:Assamese, Bengali, Gujarati, Hindi, Kannada, Kashmiri, Konkani, Malayalam, Manipuri, Marathi, Nepali, Oriya, Punjabi, Sanskrit, Sindhi, Tamil, Telugu, Urdu, Bodo, Santhali, Maithili, Dogri
- 其他语言:English
数据集规模
- 总规模:39,518.51 million tokens
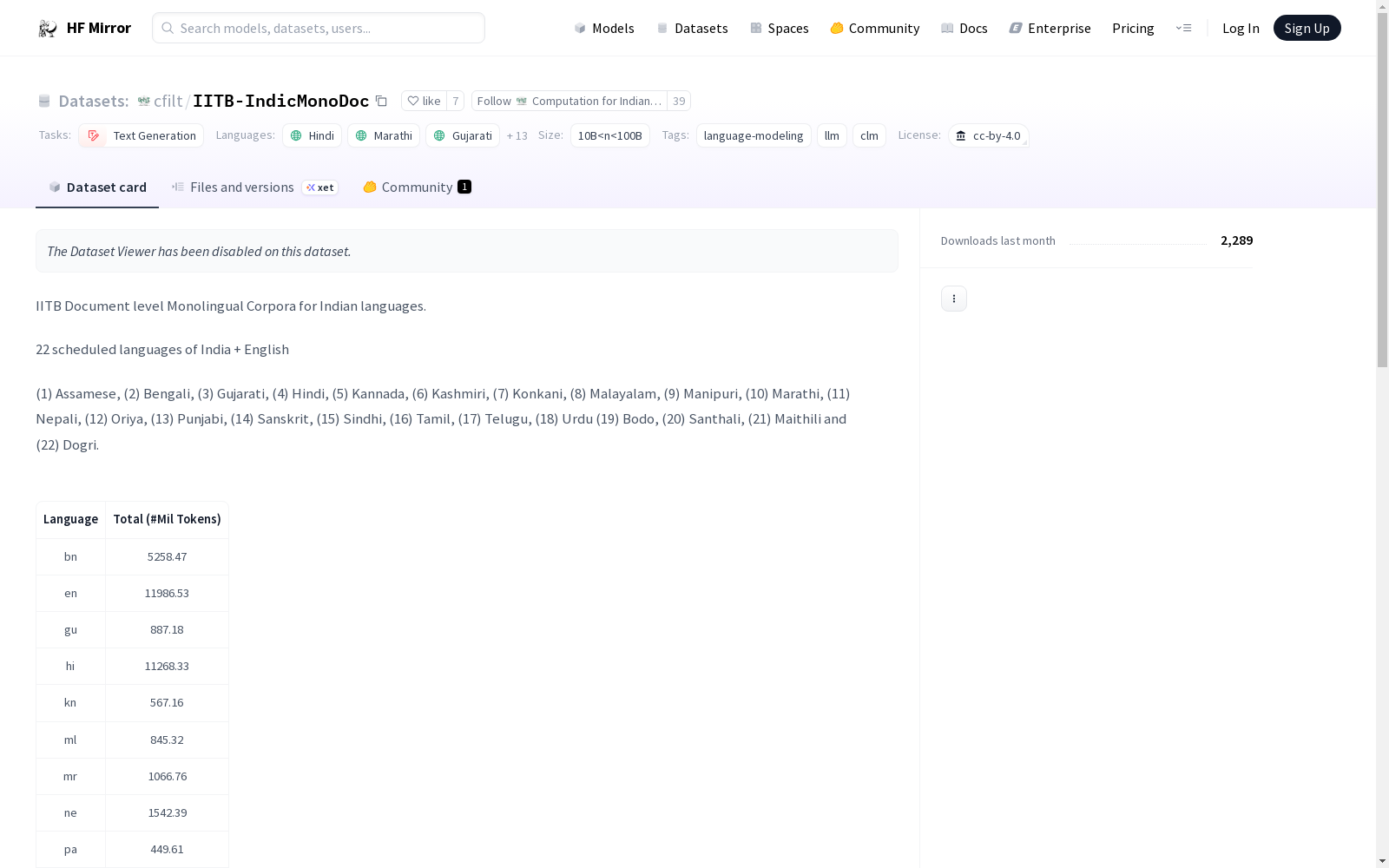
- 各语言规模(部分示例):
- Bengali: 5,258.47 million tokens
- English: 11,986.53 million tokens
- Gujarati: 887.18 million tokens
- Hindi: 11,268.33 million tokens
- Kannada: 567.16 million tokens
- Malayalam: 845.32 million tokens
- Marathi: 1,066.76 million tokens
- Nepali: 1,542.39 million tokens
- Punjabi: 449.61 million tokens
- Tamil: 2,171.92 million tokens
- Telugu: 767.18 million tokens
- Urdu: 2,391.79 million tokens
许可证
CC-BY-4.0
任务类别
- text-generation
标签
- language-modeling
- llm
- clm
引用信息
@misc{doshi2024worry, title={Do Not Worry if You Do Not Have Data: Building Pretrained Language Models Using Translationese}, author={Meet Doshi and Raj Dabre and Pushpak Bhattacharyya}, year={2024}, eprint={2403.13638}, archivePrefix={arXiv}, primaryClass={cs.CL} }
AI搜集汇总
数据集介绍
构建方式
该数据集名为cfilt/IITB-IndicMonoDoc,是由印度理工学院孟买分校构建的单语种文档级别语料库。它涵盖了22种印度的预定语言以及英语,通过广泛搜集各语言的自然文本,形成了规模庞大的语言资源库。数据集的构建基于对多种语言文本的整合,旨在为语言模型训练提供丰富的文本数据。
特点
cfilt/IITB-IndicMonoDoc数据集的特点在于其多样性及广泛性,不仅包含了印地语、孟加拉语、古吉拉特语等主要语言,也覆盖了诸如迈蒂利语、贡根语等较少使用的语言。每种语言的语料库大小不同,总计提供了超过395亿的语言标记,为研究和开发提供了坚实的基础。此外,该数据集遵循Creative Commons BY 4.0许可,保证了数据的开放性与共享性。
使用方法
使用cfilt/IITB-IndicMonoDoc数据集时,用户需遵守相应的版权和使用许可。数据集可用于语言模型的预训练、自然语言处理任务以及语言模型的性能评估。用户可以直接从数据集中提取文本,用于构建和训练语言模型,或是进行文本分析和处理。引用此数据集时,应参照提供的文献信息,以承认数据集创建者的贡献。
背景与挑战
背景概述
cfilt/IITB-IndicMonoDoc数据集是由印度理工学院孟买分校的研究团队创建的,旨在为印度22种官方语言及英语提供文档级别的单语语料库。该数据集的构建起始于对印度语言资源的稀缺性及其在自然语言处理领域应用的重视。它不仅涵盖了印度的主要语言,如印地语、孟加拉语、古吉拉特语等,而且包含了大量的语言数据,总计超过39亿词汇。该数据集的研究背景在于促进印度语言的语言模型预训练和自然语言处理技术的发展,对于印度语言的信息技术标准化和语言学研究具有重要的影响力。
当前挑战
在构建cfilt/IITB-IndicMonoDoc数据集的过程中,研究团队面临着多项挑战。首先,由于印度语言的多样性,收集和整理高质量的文本数据是一项艰巨的任务。其次,语料库的构建需要考虑语言数据的平衡性和代表性,以避免偏见。此外,印度语言的自然语言处理技术相较于主流语言还不够成熟,因此在数据集的应用和评估方面也存在着挑战。所解决的领域问题主要是缺乏足够的印度语言数据集,这对于发展印度语言的语言模型和自然语言处理应用构成了障碍。
常用场景
经典使用场景
在自然语言处理领域,cfilt/IITB-IndicMonoDoc数据集的典型应用场景在于为印度22种官方语言提供单语文档级别的语料库,以支持语言模型的预训练和文本生成任务。该数据集为语言模型提供了丰富的语言资源,使其能够学习并生成各种印度语言的自然文本。
衍生相关工作
基于cfilt/IITB-IndicMonoDoc数据集,已衍生出多项相关研究工作,包括对印度语言的语言模型进行预训练、构建特定领域的文本生成模型等。这些研究不仅扩展了数据集的应用范围,也为印度语言的自然语言处理领域贡献了新的方法和模型。
数据集最近研究
最新研究方向
在自然语言处理领域,印度语言的文本生成任务正逐渐受到重视。cfilt/IITB-IndicMonoDoc数据集为此提供了22种印度语言的文档级别单语料库,为语言模型预训练提供了丰富的资源。近期研究聚焦于利用翻译体进行语言模型的预训练,以提升模型在不同印度语言间的适应性和生成能力。此研究不仅推动了印度语言处理技术的发展,也为跨语言信息检索、机器翻译等领域带来了新的视角和方法。
以上内容由AI搜集并总结生成


