Duxiaoman-DI/FinCorpus
收藏Hugging Face2023-09-22 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/Duxiaoman-DI/FinCorpus
下载链接
链接失效反馈资源简介:
---
license: apache-2.0
language:
- zh
tags:
- finance
size_categories:
- 10M<n<100M
---
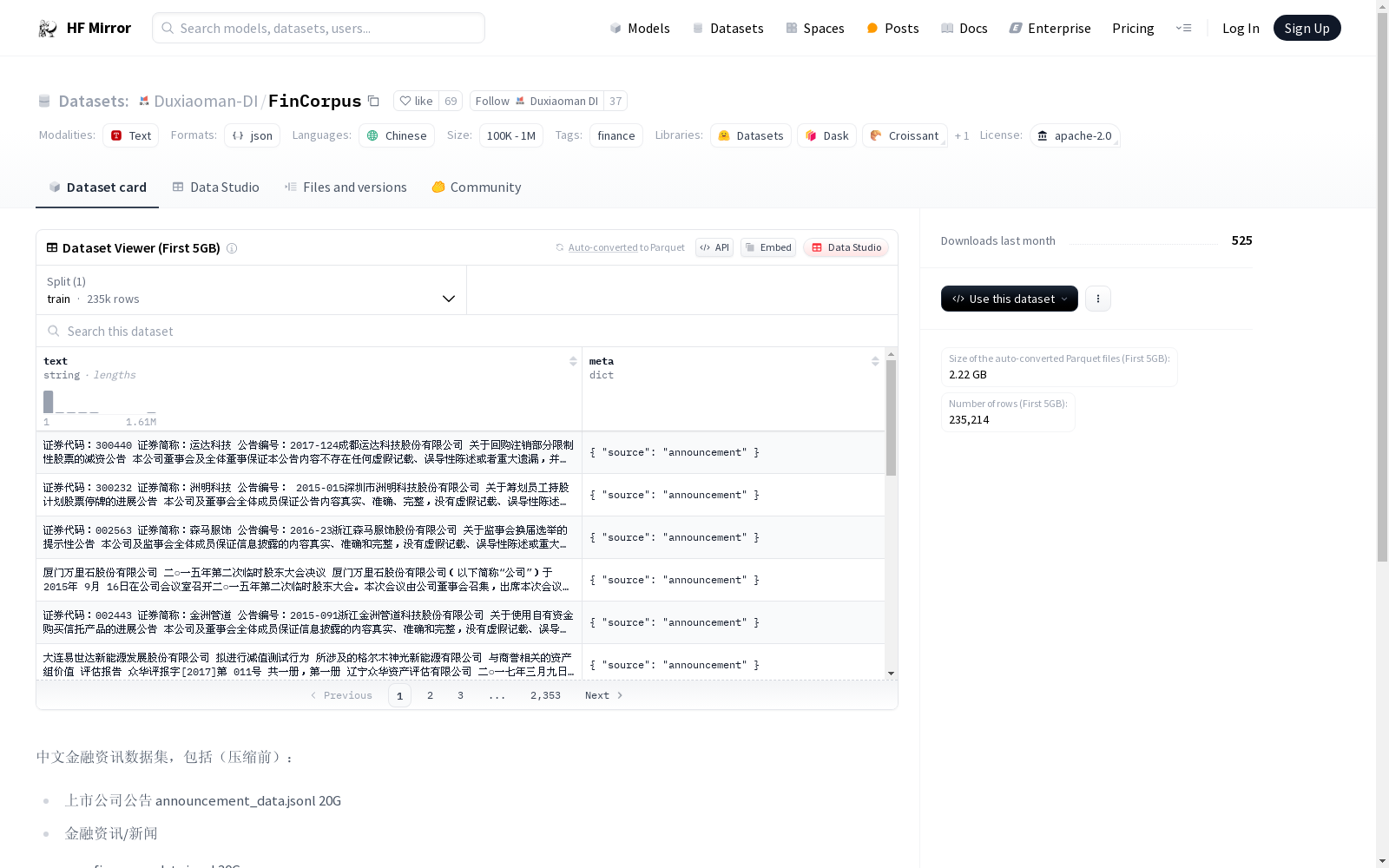
中文金融资讯数据集,包括(压缩前):
- 上市公司公告 announcement_data.jsonl 20G
- 金融资讯/新闻
- fin_news_data.jsonl 30G
- fin_articles_data.jsonl 10G
- 金融试题 fin_exam.jsonl 370M
数据格式:
```
{
"text": <文本内容>,
"meta": {
"source": <数据来源>
}
}
```
许可证:Apache-2.0
语言:
- 中文
标签:
- 金融
规模类别:
- 1000万 < 数据规模 < 1亿
本数据集为中文金融资讯数据集,未压缩状态下包含以下内容:
- 上市公司公告数据文件announcement_data.jsonl,容量20吉字节(GB)
- 金融资讯/新闻:
- fin_news_data.jsonl,容量30吉字节(GB)
- fin_articles_data.jsonl,容量10吉字节(GB)
- 金融试题数据文件fin_exam.jsonl,容量370兆字节(MB)
数据格式如下:
{
"text": <文本内容>,
"meta": {
"source": <数据来源>
}
}
提供机构:
Duxiaoman-DI
原始信息汇总
数据集概述
数据集名称
中文金融资讯数据集
数据集内容
- 上市公司公告:
announcement_data.jsonl,大小为20G。 - 金融资讯/新闻:
fin_news_data.jsonl,大小为30G。fin_articles_data.jsonl,大小为10G。
- 金融试题:
fin_exam.jsonl,大小为370M。
数据格式
json { "text": <文本内容>, "meta": { "source": <数据来源> } }
数据集属性
- 语言:中文
- 标签:金融
- 大小分类:10M<n<100M
- 许可证:Apache-2.0
搜集汇总
数据集介绍
构建方式
Duxiaoman-DI/FinCorpus数据集的构建,是在深入理解金融领域信息需求的基础上,通过收集整合了上市公司公告、金融新闻、金融文章以及金融试题等多种类型的中文金融资讯。该数据集以JSONL格式存储,每一行代表一个数据记录,其中包含了文本内容和元信息,如数据来源,这种结构便于数据的读取和处理。
特点
该数据集的特点在于其内容的多元化和信息的丰富性,覆盖了金融领域的多个方面,包括但不限于市场动态、公司运营、金融政策等。数据集规模适中,便于研究者在合理的时间内进行处理和分析。此外,其遵循Apache-2.0开源协议,为研究者提供了便捷的使用和分享途径。
使用方法
使用Duxiaoman-DI/FinCorpus数据集时,研究者可以根据需要选择相应的数据文件,如announcement_data.jsonl、fin_news_data.jsonl等。数据以{'text': <文本内容>, 'meta': {'source': <数据来源>}}的格式存储,研究者可以直接读取文本内容进行自然语言处理任务,同时可以参考元信息以进行数据源分析或数据清洗。
背景与挑战
背景概述
在金融领域的信息处理与分析研究中,Duxiaoman-DI/FinCorpus数据集的构建无疑是近年来的一项重要进展。该数据集由多家机构合作于21世纪初创建,汇集了丰富的中文金融资讯,旨在为自然语言处理、机器学习等领域提供真实、全面的金融文本资源。它包含了上市公司公告、金融新闻、金融文章以及金融试题等多种类型的数据,为研究人员深入探索金融文本的特性、构建高效的金融信息分析模型提供了坚实基础。该数据集的影响力在金融文本挖掘、情感分析、投资决策支持等领域逐渐显现,成为金融NLP领域不可或缺的资源之一。
当前挑战
尽管Duxiaoman-DI/FinCorpus数据集为金融领域的研究提供了宝贵的资源,但其在构建与应用过程中同样面临着诸多挑战。首先,数据集在构建时需要解决领域内信息多样性和异构性的问题,确保数据的全面性和准确性。其次,金融领域的数据更新迅速,如何保证数据集的时效性是一大挑战。此外,数据隐私和合规性问题在金融领域尤为重要,如何在确保数据安全的前提下进行开放共享,也是数据集构建过程中必须考虑的问题。在应用层面,如何从复杂多变的金融文本中提取出有价值的信息,以及如何提高模型的泛化能力,是当前研究面临的主要挑战。
常用场景
经典使用场景
在金融文本分析领域,Duxiaoman-DI/FinCorpus数据集的经典使用场景主要在于自然语言处理与文本挖掘。其丰富的金融领域文本资源,为构建金融文本分类、情感分析、实体识别等模型提供了坚实基础,使得研究者能够深入探索金融文本中的信息结构与语义特征。
衍生相关工作
基于该数据集,学术界和产业界衍生出了众多经典工作,包括构建金融领域的知识图谱、开发高效的金融文本生成模型、以及设计金融风险预警系统等,为金融科技的创新与发展贡献了重要力量。
数据集最近研究
最新研究方向
在金融科技迅猛发展的当下,Duxiaoman-DI/FinCorpus数据集以其丰富的金融资讯和专业知识,成为研究者探索自然语言处理在金融领域应用的宝贵资源。近期,该数据集在本领域的前沿研究方向主要集中在金融文本信息抽取、情感分析以及金融风险监控等方面。学者们通过深入挖掘该数据集,以实现对金融市场的动态监控和风险预警,这对于维护金融市场的稳定与健康发展具有重要的现实意义。
以上内容由遇见数据集搜集并总结生成


