alodokter-qna
收藏数据集概述
数据集简介
Question Answer Health Indonesian 数据集包含来自 Alodokter 网站的约 250,000 个健康相关问答对。数据集的收集时间为 2023 年 7 月至 2023 年 9 月,旨在支持自然语言处理(NLP)、特别是印尼语语言模型、健康信息检索和问答系统的研究与开发。
数据特征
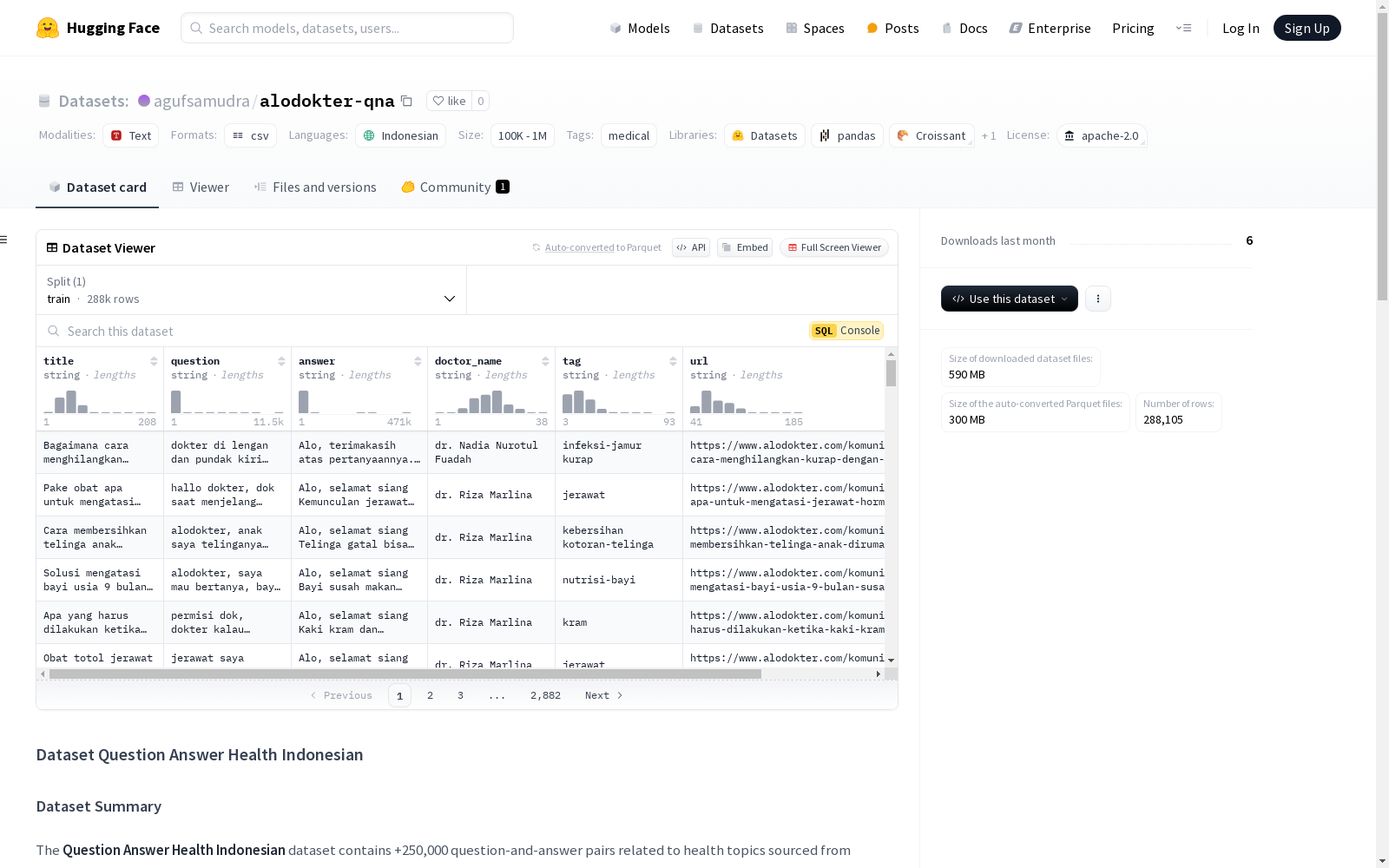
- title: 健康讨论的标题或头条。
- question: 用户提出的详细问题。
- answer: 医生提供的回答。
- doctor_name: 提供回答的医生姓名。
- tag: 与健康话题相关的标签或分类。
- url: 讨论在 Alodokter 网站上的源 URL。
数据结构
示例数据
以下是数据结构的示例:
json { "title": "Cara Mengatasi Demam Tinggi", "question": "Dok, anak saya demam tinggi sejak semalam, apa yang harus dilakukan?", "answer": "Pastikan anak cukup minum untuk mencegah dehidrasi, kompres dengan air hangat, dan berikan obat penurun demam sesuai dosis. Jika demam tidak turun dalam 3 hari, segera konsultasi ke dokter.", "doctor_name": "Dr.xxxxxx", "tag": ["demam", "anak", "pertolongan pertama"], "url": "https://www.alodokter.com/..." }
数据收集
- 来源: 数据通过抓取 Alodokter 网站上的公开讨论收集。
- 时间段: 数据收集时间为 2023 年 7 月至 2023 年 9 月。
- 数据量: 数据集包含约 250,000 条记录。
使用场景
该数据集适用于:
- 训练和评估印尼语问答模型。
- 开发健康相关的 NLP 应用。
- 分析印尼人的健康趋势和关注点。
引用
如果使用此数据集,请按以下格式引用:
@dataset{alodokter-qna, title={Dataset q&a for Health}, author={Gufranaka Samudra}, year={2024}, note={Scraped from Alodokter (July 2023 - September 2023)} }
联系方式
如有问题或反馈,请联系:
- 姓名: Gufranaka Samudra
- 邮箱: gufranakasamudra2003@gmail.com