Ficbook-Audio-Instruct-10K
收藏Hugging Face2025-12-16 更新2025-12-17 收录
下载链接:
https://huggingface.co/datasets/Vikhrmodels/Ficbook-Audio-Instruct-10K
下载链接
链接失效反馈官方服务:
资源简介:
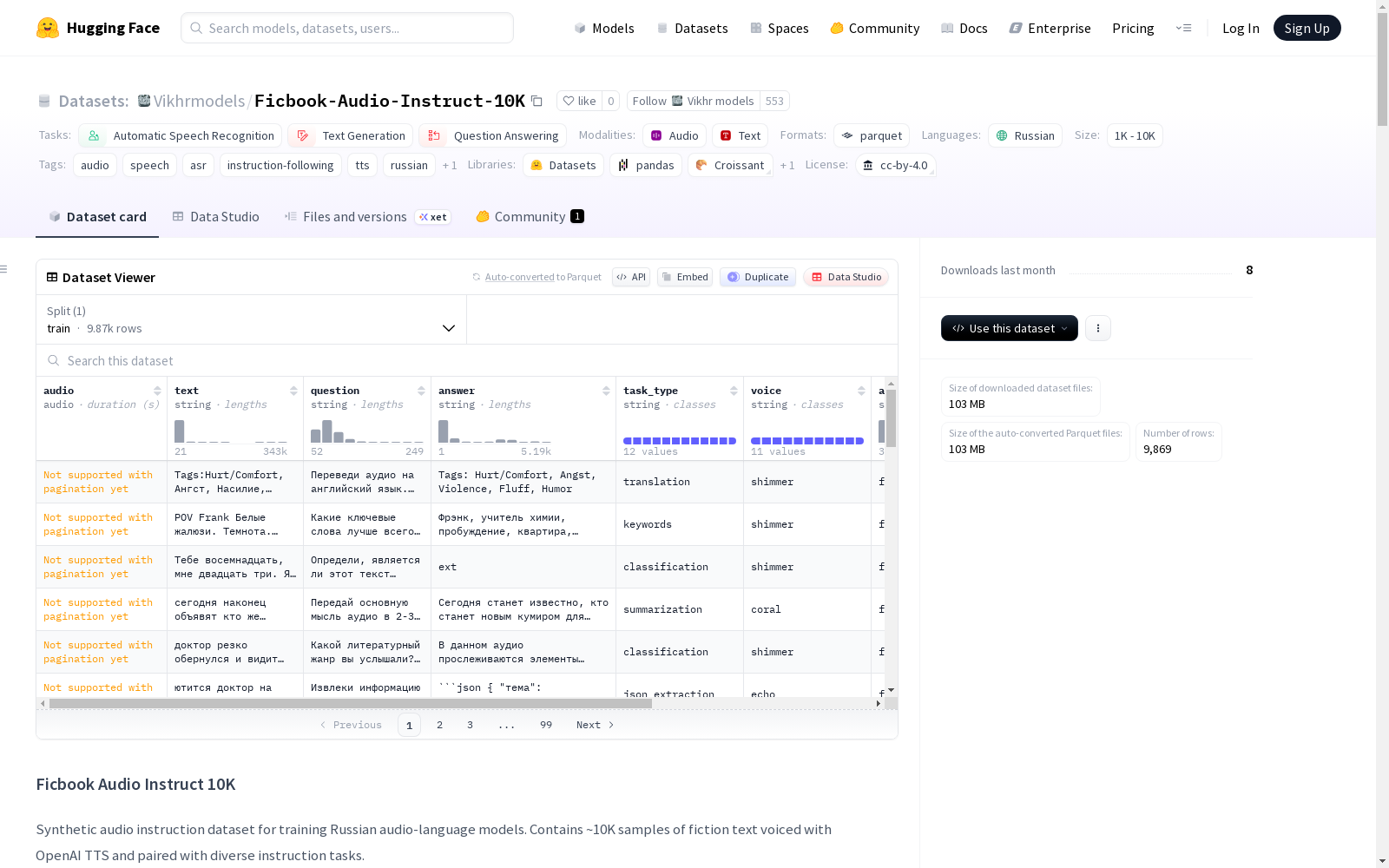
Ficbook Audio Instruct 10K是一个用于训练俄语音频语言模型的合成音频指令数据集。该数据集包含约10K个样本,每个样本包括使用OpenAI的`gpt-4o-mini-tts`模型配音的小说文本、原始文本、指令任务、预期响应(由Gemini 2.5 Flash生成)以及任务类型(共12个类别)。数据集旨在用于训练和评估俄语小说内容的音频语言模型。
创建时间:
2025-12-16
原始信息汇总
Ficbook Audio Instruct 10K 数据集概述
数据集基本信息
- 名称:Ficbook Audio Instruct 10K
- 地址:https://huggingface.co/datasets/Vikhrmodels/Ficbook-Audio-Instruct-10K
- 许可证:CC-BY-4.0
- 语言:俄语 (ru)
- 标签:音频、语音、自动语音识别、指令遵循、文本转语音、俄语、小说
- 规模类别:1K<n<10K
- 任务类别:自动语音识别、文本生成、问答
数据集描述
这是一个用于训练俄语音频-语言模型的合成音频指令数据集。数据集包含约10K个样本,内容为使用OpenAI TTS配音的小说文本,并配以多样化的指令任务。该数据集专为在俄语小说内容上训练和评估音频-语言模型而创建。
数据收集流程
- 从预处理后的Ficbook数据集中选取文本。
- 使用OpenAI的
gpt-4o-mini-tts模型通过TTS API将文本转换为音频。 - 随机选择任务类型,并使用Gemini 2.5 Flash模型(通过OpenRouter)生成对应的问题和答案。
- 组合音频、原始文本、问题、答案、任务类型和语音信息,形成最终的数据集样本。
数据集统计
- 总样本数:9,869
- 音频格式:MP3,单声道,可变采样率生成
- TTS模型:OpenAI gpt-4o-mini-tts
- TTS语音:11种不同语音 (alloy, ash, ballad, coral, echo, fable, nova, onyx, sage, shimmer, verse)
- 任务类型:12个类别
- 指令生成模型:Gemini 2.5 Flash (via OpenRouter)
任务类型分布
| 任务类型 | 数量 | 百分比 |
|---|---|---|
| json_structure | 848 | 8.6% |
| continuation | 843 | 8.5% |
| keywords | 837 | 8.5% |
| sentiment | 832 | 8.4% |
| json_extraction | 828 | 8.4% |
| translation | 827 | 8.4% |
| summarization | 827 | 8.4% |
| json_analysis | 819 | 8.3% |
| paraphrase | 818 | 8.3% |
| question_answering | 808 | 8.2% |
| ner | 803 | 8.1% |
| classification | 779 | 7.9% |
数据集结构
数据集包含以下特征字段:
audio:音频文件text:原始文本 (字符串)question:任务指令 (字符串)answer:预期回答 (字符串)task_type:任务类别 (字符串)voice:使用的TTS语音 (字符串)audio_path:音频路径 (字符串)idx:索引 (int64)
数据划分:
train:9,869个样本
任务提示示例
- classification:
Определи жанр текста из аудио,Классифицируй стиль повествования - summarization:
Кратко перескажи содержание аудио,Сделай краткое резюме услышанного - ner:
Извлеки именованные сущности из аудио в формате JSON - json_extraction:
Извлеки информацию из аудио в JSON: {"тема": "", "персонажи": [], "место": "", "время": ""} - json_structure:
Представь содержание аудио как JSON-схему событий: [{"event": "", "actor": "", "result": ""}] - json_analysis:
Проанализируй аудио и верни JSON: {"sentiment": "", "confidence": 0.0, "reasons": []} - translation:
Переведи содержание аудио на английский язык - question_answering:
Ответь на вопрос по содержанию аудио: кто главный герой? - sentiment:
Определи эмоциональную окраску аудио - keywords:
Выдели ключевые слова из аудио - paraphrase:
Перефразируй содержание аудио другими словами - continuation:
Продолжи историю из аудио
使用方式
python from datasets import load_dataset dataset = load_dataset("Vikhrmodels/Ficbook-Audio-Instruct-10K")
数据来源
- 文本来源:Vikhrmodels/ficbook_preprocessed
- 取自预处理后ficbook故事的前10,000个样本。
引用
bibtex @dataset{ficbook_audio_instruct_10k, title={Ficbook Audio Instruct 10K}, author={VikhrModels}, year={2024}, publisher={HuggingFace}, url={https://huggingface.co/datasets/Vikhrmodels/Ficbook-Audio-Instruct-10K} }
搜集汇总
数据集介绍
构建方式
在音频语言模型研究领域,合成数据集的构建对于推动俄语语音理解与生成任务的发展至关重要。Ficbook-Audio-Instruct-10K数据集的构建采用了一条精心设计的流水线,其核心流程始于从预处理后的Ficbook故事数据集中选取文本片段,随后通过OpenAI的gpt-4o-mini-tts模型,利用11种不同音色将俄语小说文本合成为音频。与此同时,系统会为每个文本片段随机分配12种任务类型中的一种,并借助Gemini 2.5 Flash模型通过OpenRouter接口生成相应的指令问题与标准答案。最终,音频文件、原始文本、指令、答案及元数据被整合为结构化的样本,共计生成9869个高质量数据点,为模型训练提供了丰富的多模态指令遵循语料。
使用方法
该数据集主要服务于音频语言模型的训练与评估。研究人员可通过Hugging Face的`datasets`库直接加载数据集,便捷地访问训练分割中的近万个样本。每个样本作为一个字典,包含音频对象、原始文本、指令问题、参考答案、任务类型和所用音色等关键字段。在实践中,开发者可以提取音频波形与采样率进行听觉回放或特征提取,同时结合指令与答案构建监督学习或指令微调任务。其多任务架构支持模型在单一数据集上进行分类、生成、信息抽取等多种能力的联合训练,为开发能够处理俄语语音指令的端到端系统提供了标准化的基准测试平台。
背景与挑战
背景概述
在音频-语言模型研究领域,针对特定语言和垂直内容的数据集构建是推动技术发展的关键。Ficbook-Audio-Instruct-10K数据集于2024年由VikhrModels团队发布,专注于俄语虚构文学内容的音频指令理解。该数据集旨在解决俄语多模态模型在遵循复杂指令、处理长文本音频以及理解文学叙事方面的核心研究问题。通过整合来自Ficbook平台的预处理小说文本,并利用先进的文本转语音技术与大语言模型生成多样化的指令-响应对,该数据集为俄语音频语言模型的训练与评估提供了宝贵的资源,对推动低资源语言的多模态人工智能研究具有显著影响力。
当前挑战
该数据集致力于应对俄语音频-语言模型在虚构文学领域进行复杂任务理解的挑战,具体包括对音频内容进行摘要、情感分析、实体识别、结构化信息提取、翻译及文本续写等十二类多样化指令的准确响应。在构建过程中,挑战主要源于高质量合成数据的生成与对齐:首先,需要确保由OpenAI TTS模型生成的俄语语音在韵律和清晰度上忠实反映原文的文学风格;其次,利用Gemini模型自动生成与音频内容紧密关联且符合任务类型的指令和答案,需克服指令多样性、答案准确性以及与音频-文本对之间语义一致性的维护难题。
常用场景
经典使用场景
在音频语言模型研究领域,Ficbook-Audio-Instruct-10K数据集为俄语虚构文学内容的处理提供了关键资源。其经典使用场景集中于训练和评估能够遵循复杂指令的音频语言模型,模型通过聆听合成语音朗读的小说片段,执行包括摘要生成、情感分析、实体识别在内的多样化任务。这种设置模拟了真实世界中模型需理解并响应语音指令的应用环境,尤其适用于探索模型在跨模态理解与生成任务上的性能边界。
解决学术问题
该数据集有效应对了音频指令遵循任务中高质量、多样化俄语数据稀缺的学术挑战。它通过合成语音与结构化指令对的组合,为研究社区提供了基准测试平台,用以探究模型在低资源语言环境下的泛化能力、跨模态对齐机制以及复杂指令的理解深度。其意义在于推动了多模态人工智能在非英语语境下的公平发展,并为评估模型在叙事性、创造性内容上的推理能力设立了新标准。
实际应用
在实际应用层面,基于该数据集训练的模型可部署于智能有声内容分析、交互式语言学习助手以及俄语无障碍信息访问服务中。例如,系统能够自动为有声小说生成内容摘要、提取关键信息或进行情感分类,辅助内容创作者和消费者高效处理海量音频资料。此外,在辅助技术领域,此类模型能帮助视障用户通过语音指令与文学音频内容进行深度交互,提升数字内容的可访问性。
数据集最近研究
最新研究方向
在俄语语音与语言模型交叉领域,Ficbook-Audio-Instruct-10K数据集正推动多模态指令跟随任务的前沿探索。该数据集通过合成俄语小说音频与多样化指令任务配对,为低资源语言环境下的语音理解与生成研究提供了关键资源。当前研究热点集中于利用此类数据训练端到端的音频-语言模型,以支持复杂任务如情感分析、实体识别和结构化信息提取,同时探索多任务学习框架在提升模型跨任务泛化能力方面的潜力。这一进展不仅促进了俄语语音技术的民主化,也为小说内容分析与创意生成应用开辟了新路径,具有显著的学术与产业价值。
以上内容由遇见数据集搜集并总结生成


