einstein_answers
收藏Hugging Face2025-02-28 更新2025-03-01 收录
下载链接:
https://huggingface.co/datasets/aliMohammad16/einstein_answers
下载链接
链接失效反馈官方服务:
资源简介:
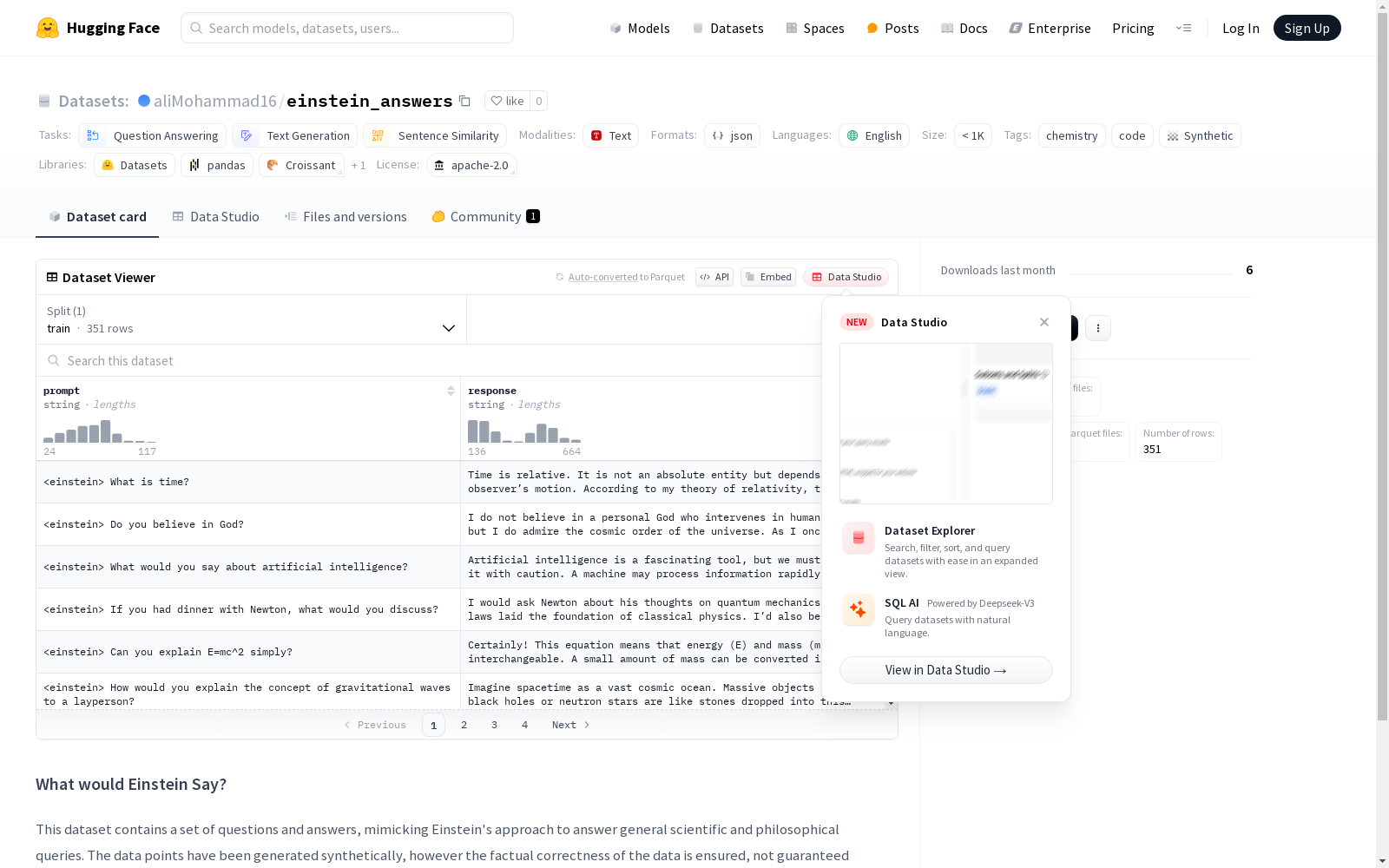
这是一个包含模仿爱因斯坦回答一般科学和哲学问题的问答数据集。数据集包含了合成的问题和答案,确保了事实的正确性,但并不保证数据完全准确。
创建时间:
2025-02-27
搜集汇总
数据集介绍
构建方式
该数据集名为'einstein_answers',其构建方式采用合成数据的形式,通过模拟爱因斯坦的回答风格,生成一系列针对普遍科学和哲学问题的问答对。数据点在生成过程中,虽力求确保事实的正确性,但并不对此作出绝对保证。
特点
此数据集的特点在于其独特的任务类别,包括问题回答、文本生成和句子相似度。其内容覆盖化学、编程等科学领域,以英语为语言载体。数据规模介于1千至10千之间,属于中小型数据集。其标签包括化学、代码和合成,体现了数据集的专题属性。
使用方法
在使用该数据集时,研究者可以将其应用于问题回答、文本生成和句子相似度等自然语言处理任务中。用户需遵守Apache-2.0许可协议,合法使用数据。由于数据是合成的,用户在使用时应考虑对结果进行验证和校准。
背景与挑战
背景概述
einstein_answers数据集,旨在模拟爱因斯坦的风格回答科学和哲学问题,其创建旨在探索自然语言处理领域中文本生成和问答任务的可能性。该数据集由一系列合成的问题和答案构成,其生成时间为不明确,但可推断是在自然语言处理技术发展到一定阶段之后。数据集的主要研究人员或机构不详,但其所涉及的科学和哲学内容,对研究人工智能在模仿历史人物语言风格方面具有显著影响,为相关领域的研究提供了新颖的数据资源。
当前挑战
einstein_answers数据集在构建和应用过程中面临多重挑战。首先,在领域问题上,如何准确模拟爱因斯坦的语言风格并确保答案的科学性和哲学深度是一个难点。其次,在构建过程中,数据集的合成性带来确保事实正确性的挑战,尽管数据集尽量确保了事实的正确性,但无法完全避免错误信息的出现。此外,数据集规模有限,仅为1K<n<10K,这限制了其在更大范围的自然语言处理任务中的应用潜力。
常用场景
经典使用场景
在模仿爱因斯坦回答风格的数据集应用中,einstein_answers被广泛用于自然语言处理领域,特别是在问题回答和文本生成任务上。其经典的使用场景在于,研究者通过训练模型以模拟爱因斯坦的回答方式,进而生成既具有科学性质又带有哲学色彩的回答,这对于探索人工智能在深度理解人类语言和思维模式方面的潜力具有重要价值。
实际应用
在实际应用中,einstein_answers数据集可以被用于开发智能聊天机器人,提供科学教育和哲学讨论的平台,以及用于训练模型以生成富有创造性和启发性的内容。其应用不仅局限于学术领域,亦可在科普教育和在线咨询服务中发挥重要作用。
衍生相关工作
基于einstein_answers数据集,研究者们衍生出了诸多相关工作,如深入分析爱因斯坦语言风格的独特性,开发更加精准的风格迁移模型,以及探索合成数据在自然语言处理任务中的适用性和局限性。这些研究进一步拓宽了人工智能语言技术的应用范围和研究视野。
以上内容由遇见数据集搜集并总结生成


