turkana-speech-dataset
收藏Hugging Face2026-04-15 更新2026-04-16 收录
下载链接:
https://huggingface.co/datasets/speedykom-group/turkana-speech-dataset
下载链接
链接失效反馈官方服务:
资源简介:
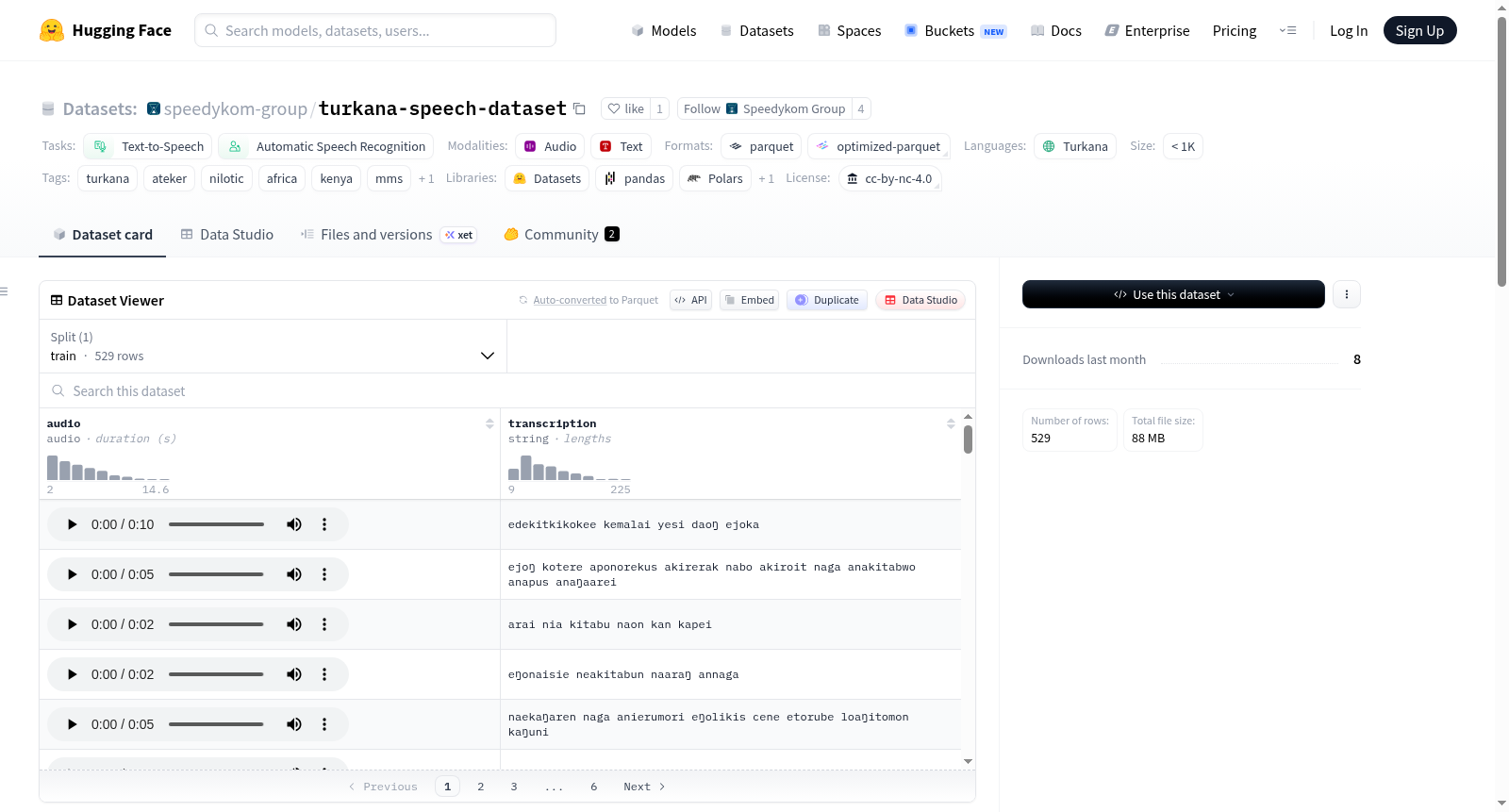
Turkana语音数据集是一个专注于Turkana语言(tuv)的语音数据集,Turkana是一种东尼罗特语系的语言,在肯尼亚西北部约有100万使用者。该数据集由Speedykom创建,旨在推动非洲欠发达语言的语音技术发展。数据集包含529个音频片段,总时长约46分钟,平均每个片段5.2秒,音频格式为WAV(16 kHz,单声道),并配有UTF-8编码的文本转录。数据来源于Global Recordings Network(GRN)的圣经叙述录音,通过静音检测进行分段。转录文本使用`facebook/mms-1b-all`模型的Teso(teo)适配器自动生成,建议进行人工审核和修正。数据集适用于文本到语音(TTS)和自动语音识别(ASR)任务,遵循cc-by-nc-4.0许可协议。
创建时间:
2026-04-14
原始信息汇总
SpeedyKom Turkana Speech Dataset 数据集概述
基本属性
- 语言: Turkana (语言代码: tuv)
- 许可证: CC BY-NC 4.0
- 任务类别: 文本转语音, 自动语音识别
- 标签: turkana, ateker, nilotic, africa, kenya, mms, vits
- 数据集名称: SpeedyKom Turkana Speech Dataset
- 规模类别: 少于1K样本
数据详情
- 数据格式: WAV音频 (16 kHz, 单声道) / UTF-8编码的文本转录
- 数据量: 529个音频片段,总时长约46分钟
- 平均时长: 每个片段约5.2秒
- 来源数据集: https://globalrecordings.net/en/program/74933
数据来源与处理
- 音频来源: 来自全球录音网络(Global Recordings Network)的圣经叙事录音,通过静音检测进行分割。
- 转录生成: 使用
facebook/mms-1b-all模型的Teso (teo)适配器自动生成。由于这是最接近Turkana语言的可用模型,建议进行人工审查和校正。
背景与用途
- 背景: 该数据集由Speedykom创建,旨在推动服务不足的非洲语言的语音技术发展。Turkana语属于东尼罗语系的Ateker (Teso-Turkana)语群,在肯尼亚西北部约有100万人使用。
- 用途: 可用于文本转语音和自动语音识别任务。
使用方式
可通过Hugging Face datasets库加载数据集:
python
from datasets import load_dataset
ds = load_dataset("meddhiaka/turkana-speech-dataset")
重要说明
- 转录为自动生成,建议人工审查和校正。
- 音频源自公开可用的GRN录音,使用时请遵守原始许可条款。
引用信息
Speedykom - turkana-speech-dataset https://huggingface.co/datasets/meddhiaka/turkana-speech-dataset Created by Speedykom (https://speedykom.de)
搜集汇总
数据集介绍
构建方式
在非洲语言资源相对匮乏的背景下,Turkana语音数据集的构建体现了对少数语言技术支持的积极探索。该数据集源自全球录音网络公开的圣经叙事录音,通过静音检测技术将连续音频切分为529个独立片段,总时长约46分钟。转录文本则借助Facebook的MMS-1b-all多语言语音识别模型,使用与Turkana最接近的Teso语言适配器自动生成,为后续人工校对提供了基础。
特点
本数据集聚焦于肯尼亚西北部约百万人使用的Turkana语,属于东尼罗语系的Ateker语支。其音频采用16kHz单声道WAV格式,平均片段时长5.2秒,兼具语音合成与自动语音识别双重任务标签。作为规模小于千样本的精选语料,它填补了该语言在开源语音数据领域的空白,尤其适用于低资源场景下的模型适配研究。
使用方法
研究者可通过Hugging Face数据集库直接加载该资源,使用标准接口访问音频波形与对应转录。鉴于转录文本由相近语言模型自动生成,建议在语音识别或合成任务前进行必要的人工校验。数据集遵循CC-BY-NC-4.0许可,使用者需尊重原始录音的授权条款,并可在引用中注明Speedykom的创建贡献。
背景与挑战
背景概述
在语音技术领域,资源稀缺语言的研究长期面临数据匮乏的困境,这阻碍了自动语音识别与文本转语音系统在全球范围内的公平发展。Turkana语音数据集由Speedykom机构于近期创建,旨在应对这一挑战,专注于服务肯尼亚西北部约一百万使用者、属于东尼罗语系Ateker语族的Turkana语。该数据集基于全球录音网络的圣经叙事公开录音,通过静音检测分割为529个音频片段,总时长约46分钟,为这一代表性不足的非洲语言提供了宝贵的语音资源,推动了多语言语音技术的包容性进步。
当前挑战
该数据集致力于解决Turkana语自动语音识别与文本转语音任务中的核心挑战,即低资源环境下模型训练的数据稀缺性问题。构建过程中面临多重困难:原始录音材料单一,主要来源于宗教叙事内容,缺乏日常口语多样性;转录文本通过相近语言Teso的适配器自动生成,可能存在语言差异导致的准确性偏差,需依赖人工校对以确保质量;音频片段经静音检测分割,可能引入切割不精确或背景噪声干扰,影响后续模型训练的鲁棒性。
常用场景
经典使用场景
在低资源语言技术领域,Turkana语音数据集为语音合成与识别研究提供了关键素材。该数据集收录了约46分钟的Turkana语语音片段,源自全球录音网络的圣经叙事材料,经过静音检测分割处理,适用于训练文本到语音和自动语音识别模型。研究者可借此探索东尼罗语系语言的声学特性,推动语言技术向服务不足的非洲语言扩展。
实际应用
在实际应用中,Turkana语音数据集可赋能本地化语音技术开发,例如构建Turkana语语音助手或教育工具,服务于肯尼亚西北部约百万使用者。它亦可用于创建语音驱动的文化存档系统,帮助记录和传播口头传统,同时为全球录音网络等组织的多语言内容制作提供技术支持,增强语言在数字时代的可持续性。
衍生相关工作
围绕该数据集,相关经典工作包括基于MMS(大规模多语言语音)模型的跨语言适配研究,探索如何将高资源语言技术迁移至Turkana等低资源语言。此外,它激励了针对东尼罗语系的语言技术项目,如开发更精确的自动转录工具或语音合成系统,并促进了非洲语言数据集的协作创建与共享生态的发展。
以上内容由遇见数据集搜集并总结生成


