lastfm-360k
收藏Hugging Face2025-03-21 更新2025-03-22 收录
下载链接:
https://huggingface.co/datasets/matthewfranglen/lastfm-360k
下载链接
链接失效反馈官方服务:
资源简介:
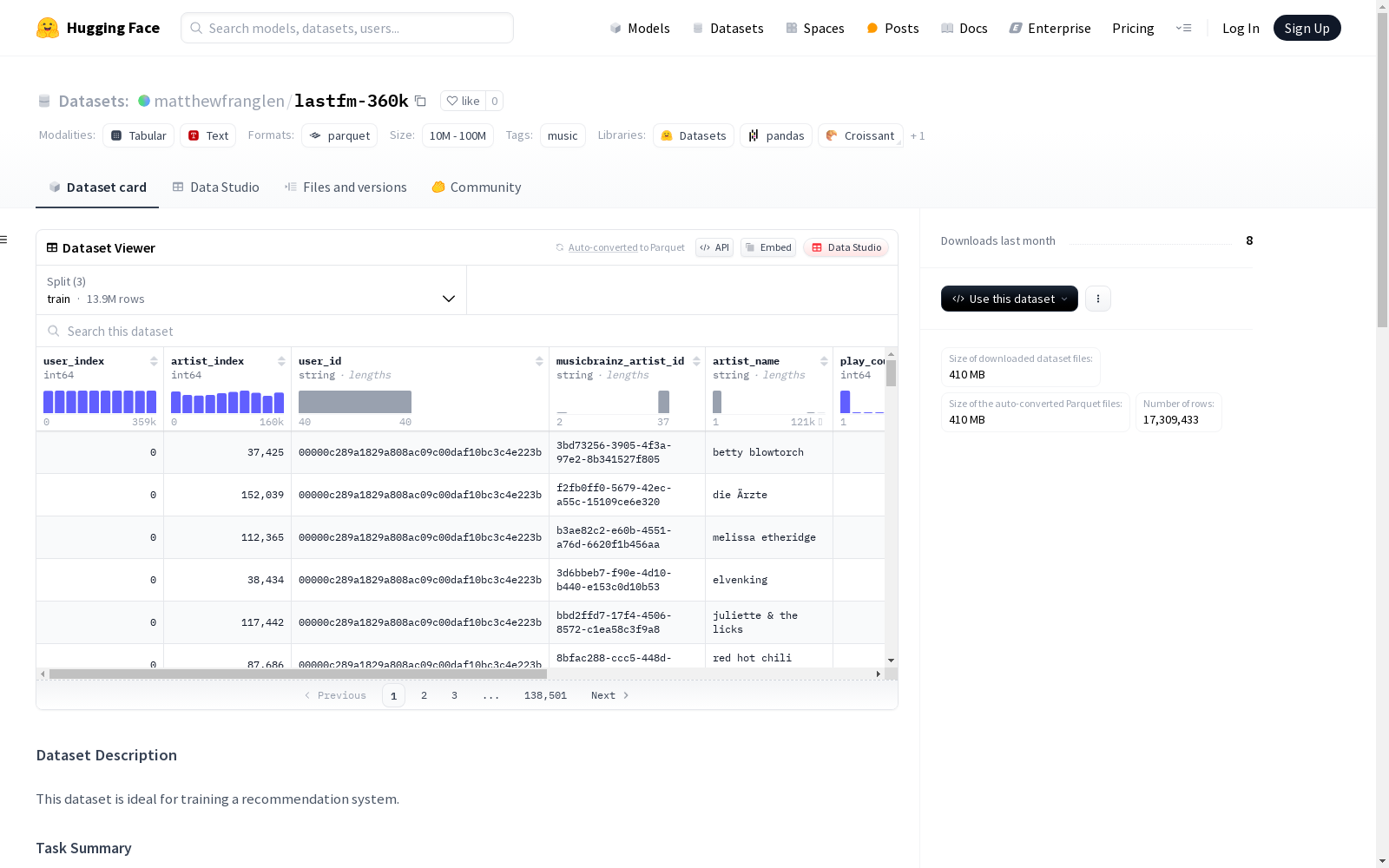
Last.fm用户艺术家数据集是一个包含用户、艺术家和播放计数记录的数据集,适用于训练推荐系统。数据可能还包含用户的性别、年龄和位置等信息,但这些信息是可选且未经验证的。数据集已经去除了缺少musicbrainz标识符的行,并增加了用户和艺术家的索引列以方便训练。
The Last.fm User-Artist Dataset is a dataset containing user, artist, and play count records, which is suitable for training recommendation systems. The data may also include optional and unverified user information such as gender, age, and location. Rows lacking MusicBrainz identifiers have been removed from the dataset, and index columns for users and artists have been added to facilitate training.
创建时间:
2025-03-21
搜集汇总
数据集介绍
构建方式
Last.fm-360k数据集构建于Last.fm平台的用户音乐播放记录,涵盖了用户、艺术家及播放次数的详细信息。数据集通过剔除缺失MusicBrainz标识符的记录,确保了数据的完整性和一致性。为了便于模型训练,数据集进一步引入了用户索引和艺术家索引,这些索引以整数的形式唯一标识每个用户和艺术家。数据集的训练、验证和测试集均采用独立用户划分,避免了用户重叠,确保了模型评估的准确性。
特点
Last.fm-360k数据集以其丰富的用户-艺术家交互记录而著称,这些记录不仅包括播放次数,还可能包含用户的性别、年龄和地理位置等附加信息,尽管这些信息未经验证且为可选。数据集特别适用于音乐推荐系统的研究,因为它提供了大量的隐式反馈数据,这些数据虽然缺乏明确的负面样本,但通过用户的实际播放行为,能够有效反映用户的音乐偏好。
使用方法
Last.fm-360k数据集主要用于训练和评估音乐推荐系统。研究人员可以利用该数据集中的用户-艺术家交互记录来构建和优化推荐算法。数据集已预先划分为训练集、验证集和测试集,便于直接用于模型的训练和性能评估。通过利用用户索引和艺术家索引,研究者可以更高效地处理和分析数据,从而提升推荐系统的准确性和用户满意度。
背景与挑战
背景概述
Last.fm-360k数据集由Òscar Celma及其团队于2010年创建,旨在为音乐推荐系统提供高质量的实验数据。该数据集源自Last.fm平台的用户行为记录,包含了用户、艺术家及播放次数的详细信息,部分用户还提供了性别、年龄和地理位置等可选信息。该数据集的核心研究问题在于如何通过用户的历史行为数据,构建高效的个性化音乐推荐系统。Last.fm-360k在音乐信息检索和推荐系统领域具有重要影响力,为研究者提供了丰富的实验数据,推动了基于隐式反馈的推荐算法研究。
当前挑战
Last.fm-360k数据集在构建和应用过程中面临多重挑战。首先,推荐系统领域的核心问题在于如何从海量用户行为数据中提取有效信息,生成高质量的个性化推荐。由于用户通常不会明确表达对音乐作品的喜好,数据集主要依赖隐式反馈(如播放次数),这导致缺乏明确的负样本,增加了模型训练的难度。其次,数据集的构建过程中,由于部分用户提交的音乐记录缺少MusicBrainz标识符,数据清洗和去重成为一项重要挑战。此外,如何确保训练集、验证集和测试集之间的用户无重叠,也是数据划分时需要解决的关键问题。
常用场景
经典使用场景
Last.fm-360k数据集在音乐推荐系统的研究中占据重要地位,尤其适用于基于用户行为的推荐算法开发。该数据集通过记录用户对艺术家的播放次数,为研究者提供了丰富的隐式反馈数据,能够有效支持协同过滤、矩阵分解等经典推荐算法的训练与评估。
解决学术问题
该数据集解决了推荐系统领域中的关键挑战,即如何在缺乏显式用户评分的情况下,利用隐式反馈数据进行精准推荐。通过提供大规模的用户-艺术家交互数据,研究者能够深入探索用户偏好建模、冷启动问题以及长尾推荐等核心学术问题,推动了推荐算法在稀疏数据环境下的性能提升。
衍生相关工作
基于Last.fm-360k数据集,衍生了一系列经典研究工作。例如,Celma等人利用该数据集提出了基于长尾理论的音乐推荐算法,为个性化推荐提供了新的视角。此外,许多研究通过结合深度学习技术,进一步提升了推荐系统的性能,如基于神经网络的协同过滤方法和图神经网络在推荐系统中的应用,这些工作均以该数据集为基础展开实验与验证。
以上内容由遇见数据集搜集并总结生成


