DigiFakeAV
收藏arXiv2025-05-22 更新2025-05-24 收录
下载链接:
https://hubeiwuhanliu.github.io/DigiFakeAV.github.io/
下载链接
链接失效反馈官方服务:
资源简介:
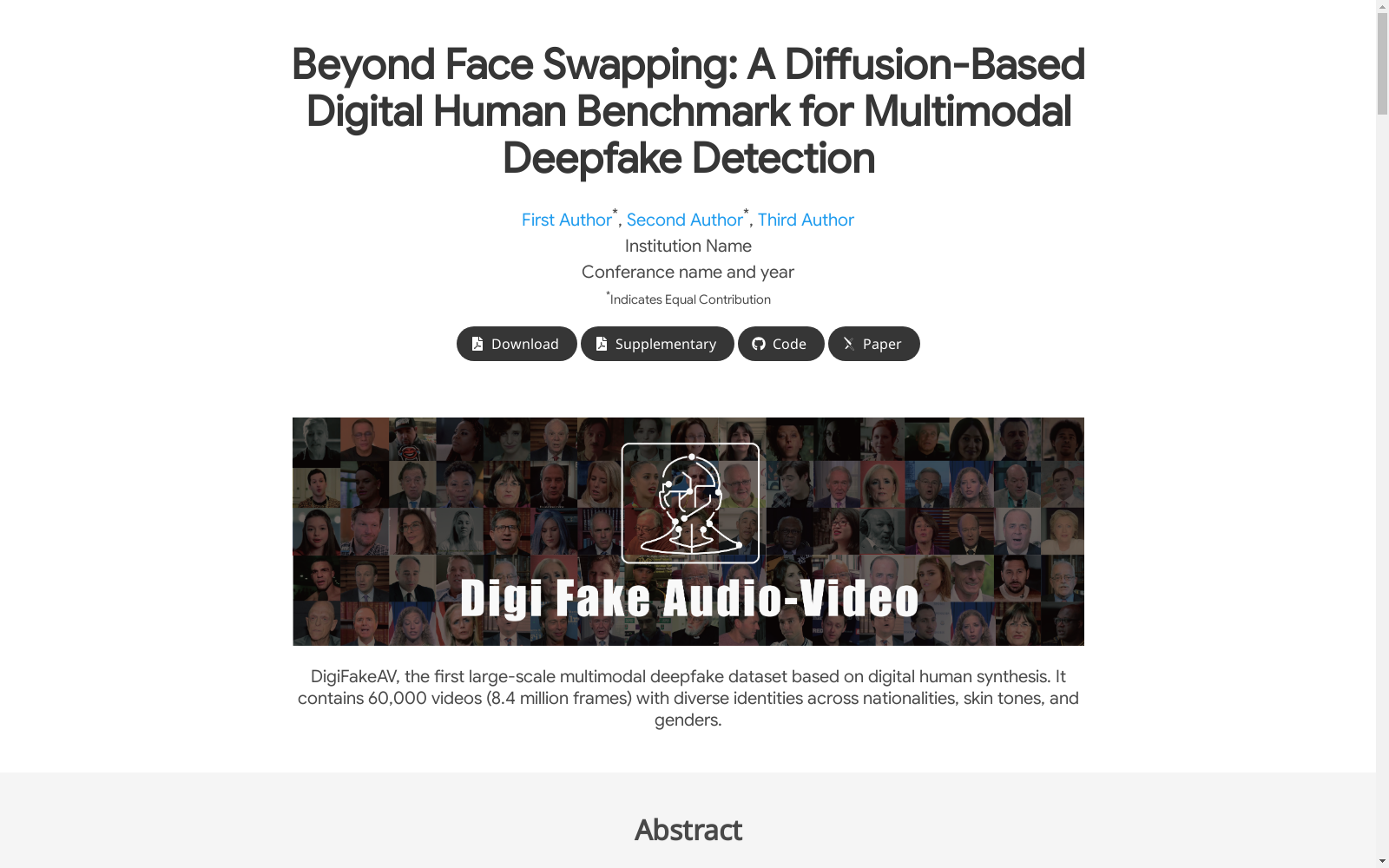
DigiFakeAV是一个基于扩散模型的大规模多模态数字人类伪造数据集,包含由五种最新数字人类生成方法和语音克隆方法产生的60,000个视频(840万帧)。该数据集涵盖了多个民族、肤色、性别和现实世界场景,显著提高了数据的多样性和真实性。DigiFakeAV旨在解决下一代深度伪造技术带来的挑战,并推动相关检测技术的发展。
DigiFakeAV is a large-scale multimodal digital human deepfake dataset based on diffusion models. It contains 60,000 videos (8.4 million frames) generated by five state-of-the-art digital human generation methods and voice cloning techniques. This dataset covers diverse ethnic groups, skin tones, genders and real-world scenarios, significantly enhancing the diversity and authenticity of the data. DigiFakeAV aims to address the challenges posed by next-generation deepfake technologies and advance the development of relevant detection techniques.
提供机构:
北京邮电大学
创建时间:
2025-05-22
原始信息汇总
DigiFakeAV 数据集概述
数据集基本信息
- 名称: DigiFakeAV
- 类型: 多模态深度伪造数据集
- 规模: 60,000个视频(840万帧)
- 特点: 基于数字人生成技术,包含多样化的国籍、肤色和性别身份
数据集生成方法
- 视频生成技术:
- V-Express: 通过渐进式信号丢弃实现多模态协调控制
- Sonic: 利用时间感知融合和长程音频上下文
- EchoMimic: 结合音频和面部关键点混合调节
- Hallo: 分层音频驱动视觉合成与多级交叉注意力
- Hallo2: 针对长时间高分辨率视频优化的VQ编码
- 音频生成技术:
- CosyVoice 2: 多阶段语义解码和条件流匹配技术
数据集分类
-
假视频-真音频 (FV-RA)
- 数量: 25,000个伪造视频
- 生成方法: 使用Sonic/Hallo1/Hallo2/Echomimic/V-Express五种技术
- 特点: 基于真实音频合成的视觉内容
-
假视频-假音频 (FV-FA)
- 数量: 25,000个伪造视频
- 生成方法: CosyVoice 2语音克隆结合四种视频生成技术
- 特点: 同时包含操纵的音频和视频内容
基准测试方法
- 分类方法:
- 基础类: Meso4, MesoInception4
- 空间类: Xception-c23
- 时间类: Capsule
- 频率类: F3-Net
- 混合域: SFIConv
- 多模态: SSVF
- 视觉Transformer: Cross Efficient ViT
- 姿态估计: HeadPose
研究意义
- 首个针对扩散式数字人伪造的系统性数据集
- 现有检测模型性能下降超过30%
- 用户研究证实伪造视频与真实视频几乎无法区分
- 提出了AVTSF音频-视觉融合检测模型
未来计划
- 持续更新数据集以包含新兴伪造技术
- 增加多样化现实场景
- 提升数据集的全面性和代表性
搜集汇总
数据集介绍
构建方式
DigiFakeAV数据集的构建采用了前沿的数字人生成技术,通过五种最新的扩散模型(如Sonic、Hallo等)和语音克隆方法,系统生成了包含60,000个视频(840万帧)的大规模多模态数据集。数据合成过程分为三个阶段:生成条件设定、扩散采样和质量控制。生成条件阶段利用真实音频或合成音频驱动视频生成模型,扩散采样阶段通过迭代去噪生成高分辨率视频帧,质量控制阶段则使用感知指标(如FID、Sync-C)过滤存在瑕疵的样本。此外,数据集还通过添加真实噪声和压缩来模拟真实世界的数据分布偏移,显著提升了数据的多样性和真实性。
使用方法
DigiFakeAV数据集为研究者提供了丰富的多模态伪造样本,支持开发鲁棒性强的视听深度伪造检测系统。数据集包含三种样本组合:真实视频-真实音频(RV-RA)、伪造视频-真实音频(FV-RA)和伪造视频-伪造音频(FV-FA),每种组合均针对不同的研究场景设计。研究者可利用该数据集训练和评估检测模型,特别关注时空特征和跨模态不一致性分析。例如,通过3D卷积网络建模视频的时空特征,结合音频的语义-声学特征进行联合分析,以识别合成视频中的隐蔽伪影。数据集的标准评估协议采用8:1:1的训练-验证-测试划分,确保无身份重叠,并应用数据增强和启发式上采样技术以解决类别不平衡问题。
背景与挑战
背景概述
DigiFakeAV数据集由北京邮电大学和北京师范大学的研究团队于2025年推出,旨在应对扩散模型生成的多模态数字人伪造内容带来的新型安全威胁。该数据集基于五种前沿数字人生成技术(如Sonic、Hallo等)和语音克隆方法,构建了包含6万视频(840万帧)的大规模基准,覆盖多民族、肤色、性别及真实场景,显著提升了数据的多样性和真实性。作为首个专注于扩散模型合成内容的检测基准,其用户研究表明伪造视频的误判率高达68%,揭示了现有检测技术在应对新一代伪造内容时的严重不足。
当前挑战
该数据集主要解决数字人伪造检测领域的核心挑战:1)扩散模型生成内容具有跨模态一致性和亚像素级真实感,传统基于GAN的检测方法难以捕捉其细微时序异常;2)构建过程中需克服多模态对齐难题,包括语音驱动下的唇部同步精度提升(较Wav2Lip基准显著改进)以及肤色、性别等人口统计学特征的平衡分布控制。实验表明,现有最优检测模型在DigiFakeAV上的AUC值平均下降43.5%,突显了数字人伪造在时空连贯性和跨模态一致性方面带来的全新检测维度挑战。
常用场景
经典使用场景
DigiFakeAV数据集在深度伪造检测领域具有广泛的应用场景,特别是在多模态深度伪造检测方面。该数据集通过结合扩散模型和数字人类生成技术,生成了高度逼真的视频和音频内容,为研究人员提供了一个全面的基准测试平台。其经典使用场景包括评估和开发新型深度伪造检测算法,特别是在面对扩散模型生成的高质量伪造内容时,检测算法的鲁棒性和准确性。
解决学术问题
DigiFakeAV数据集解决了当前深度伪造检测领域中的多个关键学术问题。首先,它填补了现有数据集在扩散模型生成内容检测方面的空白,提供了大规模、高质量的多模态伪造数据。其次,通过引入多种数字人类生成方法和语音克隆技术,该数据集增强了数据的多样性和真实性,有助于研究人员开发更具泛化能力的检测模型。此外,DigiFakeAV还揭示了现有检测算法在面对新型伪造技术时的性能瓶颈,推动了检测技术的进一步发展。
实际应用
在实际应用中,DigiFakeAV数据集为多个领域提供了重要的技术支持。在信息安全领域,该数据集可用于训练和评估深度伪造检测系统,帮助识别和防范恶意伪造内容。在社交媒体和新闻传播领域,DigiFakeAV可用于开发自动化工具,检测和过滤虚假信息。此外,该数据集还可用于法律取证和数字身份验证,为打击网络犯罪提供有力支持。
数据集最近研究
最新研究方向
随着生成式人工智能技术的迅猛发展,基于扩散模型的数字人伪造技术已成为深度伪造领域的前沿研究方向。DigiFakeAV数据集作为首个大规模多模态数字人伪造基准,通过整合五种先进的扩散模型生成方法,构建了涵盖多种族、多场景的高真实性伪造视频库。该数据集显著提升了数据多样性和真实感,用户研究表明其伪造视频的混淆率高达68%,对现有检测模型构成严峻挑战。当前研究热点聚焦于多模态时空特征融合检测技术,通过联合建模视频的3D时空特征与音频的语义-声学特征,以识别扩散模型生成的隐蔽伪影。这一方向不仅推动了深度伪造检测技术的革新,也为应对数字身份安全、社会信任危机等现实问题提供了重要研究基础。
相关研究论文
- 1Beyond Face Swapping: A Diffusion-Based Digital Human Benchmark for Multimodal Deepfake Detection北京邮电大学 · 2025年
以上内容由遇见数据集搜集并总结生成


