PLM-VideoBench
收藏Hugging Face2025-04-18 更新2025-04-19 收录
下载链接:
https://huggingface.co/datasets/facebook/PLM-VideoBench
下载链接
链接失效反馈官方服务:
资源简介:
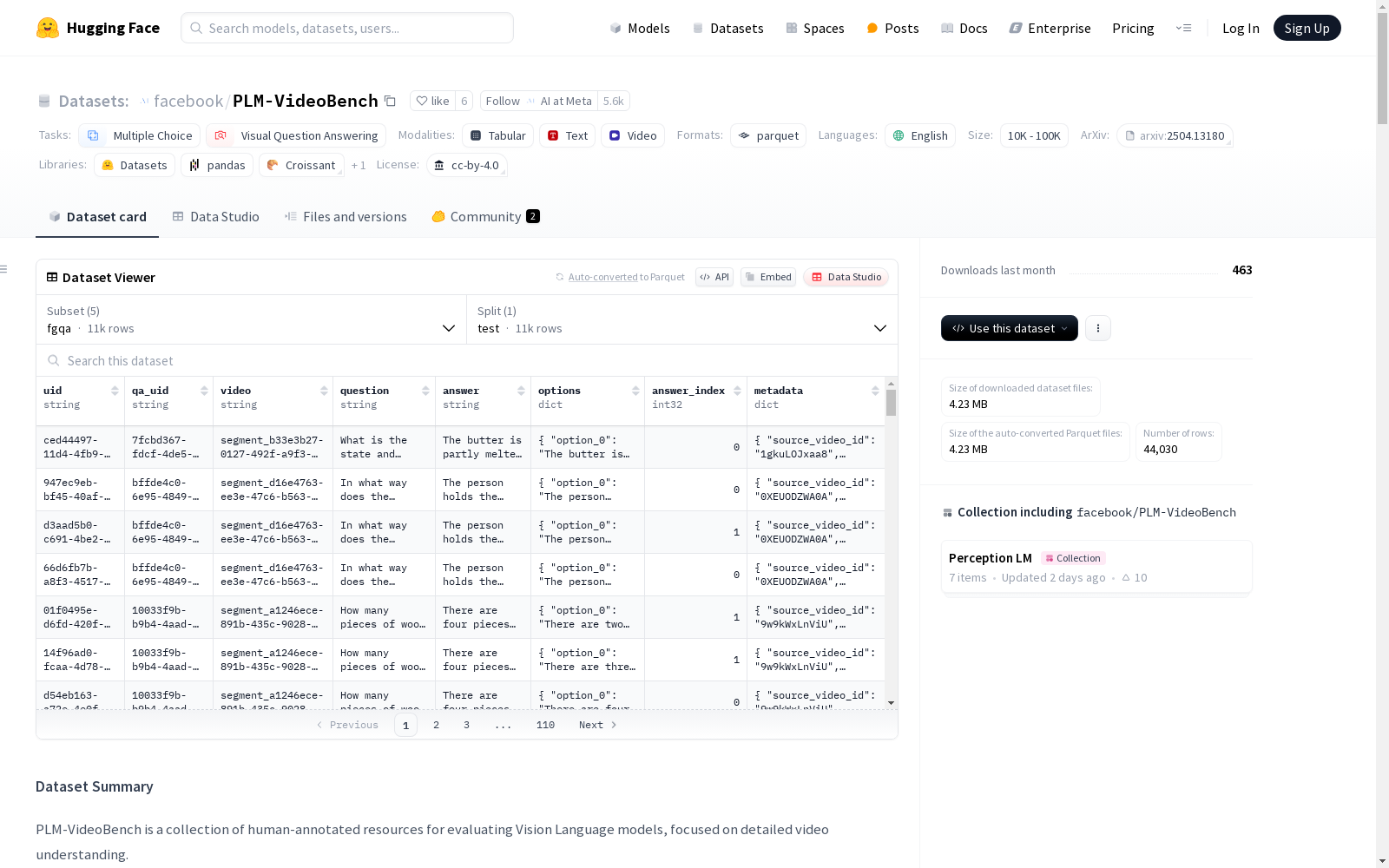
PLM-VideoBench是一个用于评估视觉语言模型的人类注释资源集合,专注于详细视频理解。数据集包括以下子任务:FGQA(细粒度活动理解的多项选择题)、SGQA(关于第一视角视频流中的活动和对象的开放性问题)、RCap(给定视频片段和区域遮罩,生成事件描述)、RTLoc(识别视频中特定事件发生的时间间隔)、RDCap(为视频中的特定主体生成详细描述)。每个子任务都有相应的数据字段和评估指标。
提供机构:
AI at Meta
创建时间:
2025-04-08
搜集汇总
数据集介绍
构建方式
PLM-VideoBench数据集通过多模态数据整合与人工标注相结合的方式构建,涵盖FGQA、SGQA、RCap、RTLoc和RDCap五个子任务。数据源包括COIN、Ego4d等公开视频数据集及独立采集的智能眼镜视频,通过专业标注团队对视频片段进行细粒度活动标注,并采用LLM-judge机制确保答案质量。每个样本均包含视频标识符、时间戳、问题选项及元数据,构建过程注重消除数据偏差并保持任务多样性。
特点
该数据集以视频理解为核心,突出细粒度活动分析和时空定位能力评估。FGQA任务采用多二元精度评估机制,有效降低选项偏差;SGQA模拟真实场景的智能眼镜交互问题;R系列任务则通过区域掩码与时间戳的联合标注,支持复杂事件描述与定位。所有任务均配备详尽的元数据标注,包括视频来源、领域类型和问题类别,为模型可解释性研究提供支持。数据格式采用标准化结构体设计,确保多任务数据的一致性与易用性。
使用方法
使用PLM-VideoBench需根据具体任务类型加载对应配置文件,通过HuggingFace数据集接口或原始Parquet文件读取数据。评估时可采用官方提供的独立脚本或lmms-evals集成工具,需按照任务要求格式化预测结果。FGQA任务需转换为二元对比格式提交,R系列任务则需生成时间区间或密集描述。调用Llama-3.3-70B-Instruct作为LLM-judge时,需配置vllm环境并指定评估指标输出路径。典型使用流程包括数据加载、模型预测、结果格式转换和指标计算四个阶段。
背景与挑战
背景概述
PLM-VideoBench是由Facebook Research团队于2025年推出的多模态视频理解评估基准,旨在推动视觉语言模型在细粒度视频理解领域的发展。该数据集整合了来自COIN、Ego4D等主流视频数据源的标注片段,包含精细活动问答(FGQA)、智能眼镜场景问答(SGQA)等五项核心任务,通过人类专家标注构建了覆盖物体状态、时空定位等维度的评估体系。其技术框架PerceptionLM通过融合时空注意力机制与语言建模,为视频内容解析设立了新的评估标准,相关成果已发表于计算机视觉顶级会议并引发广泛关注。
当前挑战
该数据集面临双重技术挑战:在领域问题层面,细粒度活动理解要求模型捕捉视频中微妙的状态差异(如黄油部分融化与完全融化),这对时空特征联合建模提出极高要求;而智能眼镜场景下的开放式问答需解决穿戴设备拍摄视角受限、环境干扰等现实难题。在构建过程中,标注一致性保障尤为困难,例如RCap任务要求标注者精确描述掩膜区域主体的动作细节,不同标注者间的一致性控制消耗了大量质量控制成本。此外,跨数据集视频片段的时空对齐(如HT100M自动生成片段与人工标注片段的帧级匹配)也面临显著的工程技术挑战。
常用场景
经典使用场景
PLM-VideoBench数据集在视觉语言模型评估领域具有重要地位,其经典使用场景包括对视频内容进行细粒度理解和多模态推理。该数据集通过多项选择题和视觉问答任务,要求模型在给定视频片段的基础上,准确回答涉及活动细节、物体状态等复杂问题。这种设计能够全面评估模型对视频时序信息、空间关系和语义理解的综合能力,尤其适用于测试模型在真实场景下的表现。
衍生相关工作
围绕该数据集已产生多项重要研究工作,包括基于LLM的自动评估方法、多模态融合架构创新以及跨任务迁移学习技术。数据集作者团队开发的PerceptionLM模型系列充分利用了PLM-VideoBench的评估能力,在细粒度视频理解任务上取得了突破性进展。同时,该数据集也启发了后续研究者在视频问答、时序定位等方向提出新的评估协议和模型优化策略,持续推动着多模态学习领域的发展。
数据集最近研究
最新研究方向
随着多模态大模型技术的快速发展,PLM-VideoBench作为视频理解领域的基准数据集,正推动着细粒度视觉语言理解研究的前沿探索。该数据集通过FGQA任务中的多选问答机制,促进了模型对视频中细微动作差异的辨识能力研究,这一方向与当前智能穿戴设备场景理解的需求高度契合。在SGQA任务设计上,研究者正探索如何通过第一视角视频问答来提升AR眼镜等设备的实时交互能力。RCap和RTLoc的镜像任务结构为时空定位与描述生成的联合建模提供了新的研究范式,而RDCap任务则推动着长视频密集事件描述生成技术的发展,这些研究热点均与视频内容生成、智能监控等实际应用紧密相连。数据集采用的LLM-judge评估机制也反映了当前大模型时代下评估方法的最新趋势。
以上内容由遇见数据集搜集并总结生成


