erenfazlioglu/turkishvoicedataset
收藏Hugging Face2024-05-27 更新2024-06-15 收录
下载链接:
https://hf-mirror.com/datasets/erenfazlioglu/turkishvoicedataset
下载链接
链接失效反馈官方服务:
资源简介:
---
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: audio
dtype: audio
- name: transcription
dtype: string
splits:
- name: train
num_bytes: 5933166725.824
num_examples: 130634
download_size: 5547933432
dataset_size: 5933166725.824
tags:
- audio
- text-to-speech
- turkish
- synthetic-voice
language:
- tr
task_categories:
- text-to-speech
---
# Dataset Card for "turkishneuralvoice"
## Dataset Overview
**Dataset Name**: Turkish Neural Voice
**Description**: This dataset contains Turkish audio samples generated using Microsoft Text to Speech services. The dataset includes audio files and their corresponding transcriptions.
## Dataset Structure
**Configs**:
- `default`
**Data Files**:
- Split: `train`
- Path: `data/train-*`
**Dataset Info**:
- Features:
- `audio`: Audio file
- `transcription`: Corresponding text transcription
- Splits:
- `train`
- Number of bytes: `5,933,166,725.824`
- Number of examples: `130,634`
- Download Size: `5,547,933,432` bytes
- Dataset Size: `5,933,166,725.824` bytes
## Usage
To load this dataset in your Python environment using Hugging Face's `datasets` library, use the following code:
```python
from datasets import load_dataset
dataset = load_dataset("path/to/dataset/turkishneuralvoice")
配置项:
- 配置名称:default(默认配置)
数据文件:
- 划分集:train(训练集)
路径:data/train-*
数据集信息:
特征:
- 名称:audio(音频)
数据类型:音频格式
- 名称:transcription(转录文本)
数据类型:字符串
划分集:
- 名称:train(训练集)
字节数:5933166725.824
样本数:130634
下载大小:5547933432 字节
数据集大小:5933166725.824 字节
标签:
- 音频(audio)
- 文本转语音(text-to-speech)
- 土耳其语(turkish)
- 合成语音(synthetic-voice)
语言:
- tr(土耳其语ISO 639-1代码)
任务类别:
- 文本转语音(text-to-speech)
---
# "土耳其神经语音(Turkish Neural Voice)"数据集卡片
## 数据集概览
**数据集名称**:土耳其神经语音(Turkish Neural Voice)
**描述**:本数据集包含使用微软文本转语音(Microsoft Text to Speech)服务生成的土耳其语音频样本,数据集包含音频文件及其对应的转录文本。
## 数据集结构
**配置项**:
- `default`(默认配置)
**数据文件**:
- 划分集:`train`(训练集)
- 路径:`data/train-*`
**数据集信息**:
- 特征:
- `audio`(音频):音频文件
- `transcription`(转录文本):对应的文本转录内容
- 划分集:
- `train`(训练集)
- 字节数:`5,933,166,725.824`
- 样本数:`130,634`
- 下载大小:`5,547,933,432` 字节
- 数据集大小:`5,933,166,725.824` 字节
## 使用方法
若要在Python环境中使用Hugging Face的`datasets`库加载此数据集,请使用以下代码:
python
from datasets import load_dataset
dataset = load_dataset("path/to/dataset/turkishneuralvoice")
提供机构:
erenfazlioglu
原始信息汇总
数据集卡片 "turkishneuralvoice"
数据集概述
数据集名称: Turkish Neural Voice
描述: 该数据集包含使用Microsoft文本到语音服务生成的土耳其语音频样本。数据集包括音频文件及其相应的转录文本。
数据集结构
配置:
default
数据文件:
- 分割:
train- 路径:
data/train-*
- 路径:
数据集信息:
- 特征:
audio: 音频文件transcription: 相应的文本转录
- 分割:
train- 字节数:
5,933,166,725.824 - 样本数:
130,634
- 字节数:
- 下载大小:
5,547,933,432字节 - 数据集大小:
5,933,166,725.824字节
搜集汇总
数据集介绍
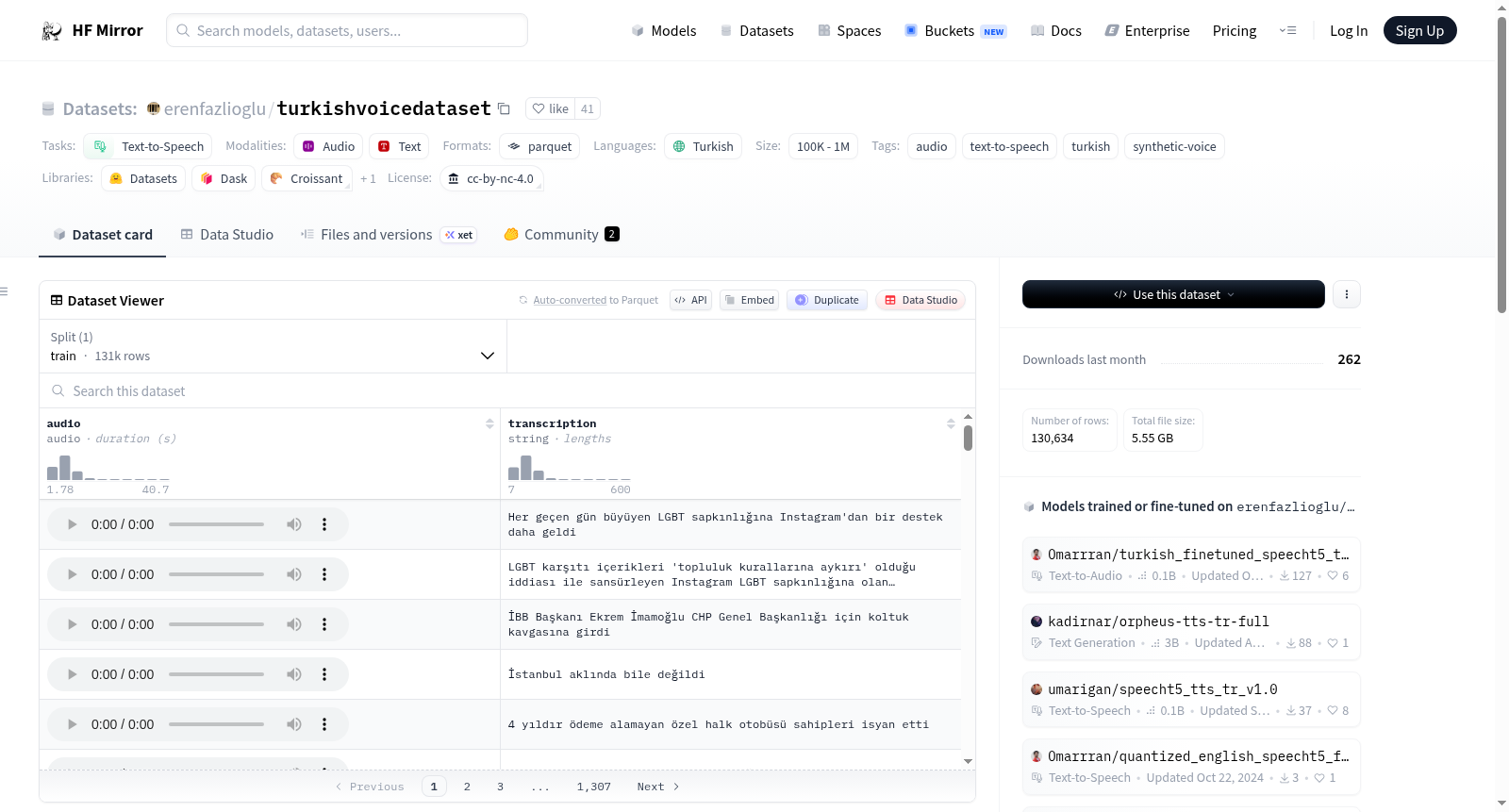
构建方式
在语音合成领域,高质量的语音数据集对于训练先进的文本转语音模型至关重要。土耳其神经语音数据集通过微软文本转语音服务生成,涵盖了超过13万条土耳其语音频样本及其对应文本转录。该数据集采用自动化流程构建,音频文件与转录文本一一对应,确保了数据的一致性和完整性,为土耳其语语音合成研究提供了标准化的资源基础。
使用方法
研究人员可通过Hugging Face的datasets库便捷加载此数据集,使用load_dataset函数指定数据集路径即可访问训练分割。数据集以音频文件和文本转录的形式组织,用户可直接提取音频特征或结合转录文本进行模型训练。该资源适用于文本转语音模型的开发、语音质量评估以及土耳其语语音技术的实验,为学术和工业界提供了即用型数据支持。
背景与挑战
背景概述
在语音合成技术迅猛发展的背景下,土耳其语作为全球使用人口众多的语言之一,其高质量语音数据集的构建显得尤为重要。土耳其神经语音数据集由研究人员erenfazlioglu于近年创建,依托微软文本转语音服务生成音频样本,旨在为土耳其语语音合成模型提供大规模、标准化的训练资源。该数据集包含超过13万条音频及其对应转录文本,核心研究问题聚焦于提升土耳其语合成语音的自然度与流畅性,对推动低资源语言语音技术发展具有显著影响力,填补了土耳其语领域公开数据集的空白。
当前挑战
该数据集主要挑战体现在两方面:在领域问题层面,土耳其语作为黏着语,其复杂的形态结构和丰富的音韵变化对语音合成模型的准确性构成挑战,要求模型能精准处理词缀组合与语音连贯性;在构建过程中,依赖合成语音生成而非真实人声采集,可能导致音频缺乏自然情感变化和发音多样性,同时需确保转录文本与音频对齐的精确性,以及处理大规模数据存储与格式标准化带来的技术难题。
常用场景
经典使用场景
在语音合成领域,土耳其语作为资源相对稀缺的语言,其研究常面临数据不足的挑战。erenfazlioglu/turkishvoicedataset 通过提供大规模、高质量的土耳其语音频与文本配对数据,成为训练端到端神经语音合成模型的经典资源。该数据集常用于构建基于深度学习的文本到语音系统,例如 Tacotron 或 FastSpeech 架构,以生成自然、流畅的土耳其语语音。研究人员利用其丰富的语音样本优化声学模型和声码器,显著提升了合成语音的自然度和表现力,为土耳其语语音技术发展奠定了数据基础。
解决学术问题
该数据集有效缓解了土耳其语语音合成研究中数据稀缺的核心问题,为学术界提供了标准化的评估基准。它支持对低资源语言语音合成模型的探索,解决了传统方法依赖大量标注数据、难以适应特定语种的局限性。通过提供合成语音样本,数据集促进了跨语言语音合成、多说话人建模以及语音质量客观评价等研究方向的发展,推动了语音技术在多语言环境下的公平性与包容性,对计算语言学和人机交互领域具有重要理论意义。
实际应用
在实际应用中,该数据集为土耳其语智能语音助手、有声读物生成和实时语音翻译系统提供了关键支持。企业可基于此数据集开发定制化语音合成引擎,应用于教育、娱乐和客户服务等领域,例如为视障人士提供土耳其语语音导航或为在线课程添加高质量语音解说。其合成语音的自然度有助于提升用户体验,推动土耳其语数字内容的本土化进程,并在多语言信息无障碍访问中发挥积极作用。
数据集最近研究
最新研究方向
在语音合成领域,土耳其语作为资源相对稀缺的语言,其数据集的发展正推动着多语言语音技术的进步。erenfazlioglu/turkishvoicedataset作为土耳其神经语音数据集,聚焦于合成语音的生成与应用,其前沿研究方向涵盖低资源语言语音模型的优化、跨语言迁移学习以及合成语音的自然度提升。近年来,随着全球人工智能伦理讨论的升温,合成语音的隐私保护与数据安全成为热点议题,该数据集为土耳其语语音系统的开发提供了关键资源,促进了语言技术的包容性发展,对文化多样性和数字平等具有深远意义。
以上内容由遇见数据集搜集并总结生成


