arabic_deepfakes_test
收藏Hugging Face2024-08-25 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/DeepFake-Audio-Rangers/arabic_deepfakes_test
下载链接
链接失效反馈官方服务:
资源简介:
该数据集主要用于音频真伪识别,包含音频数据和对应的标签。标签分为'fake'和'real'两类,用于区分音频的真伪。数据集分为训练集和测试集,分别包含15648和3913个样本。数据集的下载大小和总大小分别为1567148799和1654870038.481字节。
创建时间:
2024-08-25
原始信息汇总
阿拉伯语深度伪造音频数据集
数据集信息
特征
- 音频:
- 名称: audio
- 数据类型: audio
- 标签:
- 名称: label
- 数据类型: class_label
- 名称:
- 0: fake
- 1: real
- 名称:
分割
- 训练集:
- 名称: train
- 字节数: 1322891516.5301797
- 样本数: 15648
- 测试集:
- 名称: test
- 字节数: 331978521.95082015
- 样本数: 3913
大小
- 下载大小: 1567148799
- 数据集大小: 1654870038.481
配置
- 配置名称: default
- 数据文件:
- 分割: train
- 路径: data/train-*
- 分割: test
- 路径: data/test-*
- 分割: train
- 数据文件:
任务类别
- audio-to-audio
- audio-classification
语言
- 阿拉伯语
标签
- 合成
大小类别
- 10K<n<100K
数据集描述
- 该数据集包含使用基于检索的转换生成的阿拉伯语深度伪造音频。
- 目前包含约14小时的伪造音频。
- 数据集仍在进行中。
- 所有样本以40KHz生成,原始转换的语音片段最大持续时间为3秒。
- 语音包括黎凡特方言和标准阿拉伯语。
搜集汇总
数据集介绍
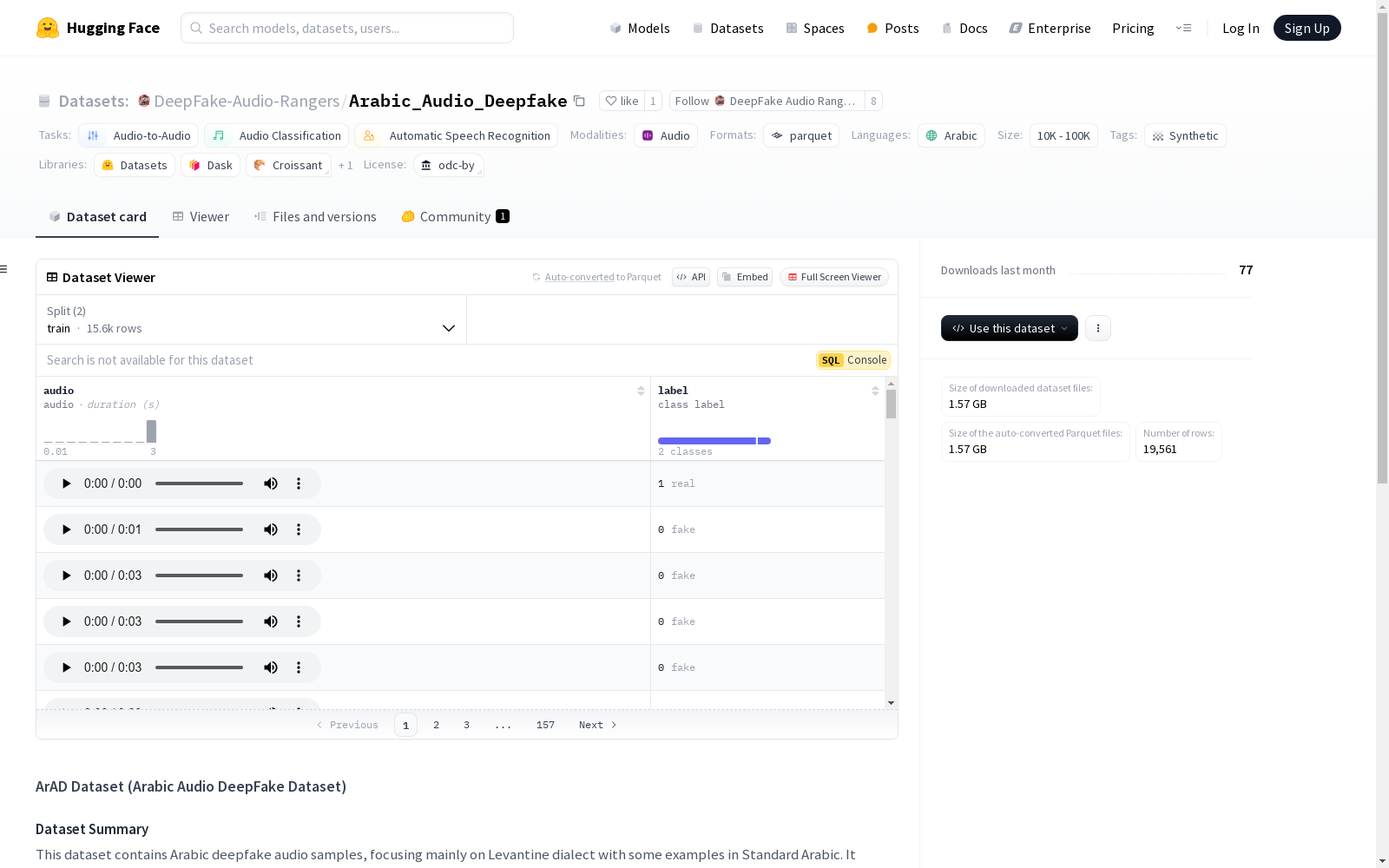
构建方式
阿拉伯语深度伪造音频数据集(ArAD)的构建过程采用了RVC v2框架,并基于多方言阿拉伯语语音的自定义数据集进行微调。数据收集过程中,每位发言者的语音音频至少包含5分钟的内容,随后为每位发言者训练独立的模型,用于生成伪造音频。为确保数据的真实性,未使用任何发言者的模型生成其自身的声音。语音片段根据静音进行分割,且长度限制在3秒以内。
特点
该数据集主要包含黎凡特方言的阿拉伯语深度伪造音频样本,部分样本为标准阿拉伯语。音频格式为WAV,采样率为16KHz,经过从原始录音中清理和重采样处理。数据集特别注重模拟现实世界中的深度伪造音频攻击,生成了从实际录音和语音消息中提取的合成语音。其独特之处在于首次包含了现实世界中的阿拉伯语深度伪造音频样本。
使用方法
该数据集适用于深度伪造检测、语音克隆及相关人工智能任务的研究。研究人员可通过该数据集探索语音系统中的潜在漏洞,并开发相应的检测和防御技术。数据集的使用需遵循Open Data Commons Attribution License的许可条款,确保在引用时注明来源。
背景与挑战
背景概述
阿拉伯语深度伪造音频测试数据集(arabic_deepfakes_test)是一个专注于阿拉伯语深度伪造音频的研究资源,主要涵盖黎凡特方言和部分标准阿拉伯语。该数据集由RVC v2框架生成,并通过多方言阿拉伯语音数据集进行微调,旨在模拟现实世界中的深度伪造音频攻击。作为首批包含真实世界阿拉伯语深度伪造音频的数据集之一,它在深度伪造检测、语音克隆及相关人工智能任务的研究中具有重要意义。该数据集的创建过程包括为每个说话者收集至少5分钟的语音音频,并训练独立的模型以生成伪造音频,确保不重复使用同一说话者的模型生成其自身语音。
当前挑战
该数据集在解决深度伪造音频检测问题时面临多重挑战。首先,阿拉伯语的多方言特性使得伪造音频的生成和检测更加复杂,尤其是黎凡特方言与标准阿拉伯语之间的差异。其次,数据集的构建过程中需确保音频质量的一致性,包括音频格式的统一、采样率的调整以及噪声的去除。此外,生成伪造音频时需避免模型对同一说话者的语音进行自我复制,这对数据集的多样性和真实性提出了更高要求。这些挑战不仅体现在技术层面,还涉及伦理和隐私问题,尤其是在处理真实语音数据时需确保数据的合法性和安全性。
常用场景
经典使用场景
在阿拉伯语语音合成与检测领域,arabic_deepfakes_test数据集被广泛应用于深度伪造音频的检测研究。通过提供真实的阿拉伯语语音样本及其对应的深度伪造版本,该数据集为研究人员提供了一个标准化的测试平台,用于开发和评估深度伪造检测算法。特别是在黎凡特方言和标准阿拉伯语的混合语音环境中,该数据集能够有效模拟现实世界中的深度伪造攻击场景。
实际应用
在实际应用中,arabic_deepfakes_test数据集被广泛用于语音认证系统的安全性测试。通过模拟深度伪造攻击,该数据集帮助开发人员识别和修复语音认证系统中的潜在漏洞。此外,该数据集还被用于语音合成技术的优化,特别是在多方言阿拉伯语环境下的语音生成任务中,为语音助手和自动语音识别系统的开发提供了重要参考。
衍生相关工作
基于arabic_deepfakes_test数据集,多项经典研究工作得以展开。例如,研究人员开发了基于深度学习的阿拉伯语深度伪造检测模型,显著提升了检测精度。此外,该数据集还催生了多篇关于语音克隆和语音合成优化的学术论文,推动了阿拉伯语语音处理领域的技术创新。这些工作不仅提升了深度伪造检测的技术水平,还为语音技术的实际应用提供了新的思路。
以上内容由遇见数据集搜集并总结生成


