V-REX
收藏github2025-12-15 更新2025-12-18 收录
下载链接:
https://github.com/tianyi-lab/VREX
下载链接
链接失效反馈官方服务:
资源简介:
V-REX数据集包含700多个样本和2500多个问题,涵盖多样化的应用场景和实际挑战,如图表、时间估计、GUI解释等。数据集覆盖15个真实场景,分为4个推理类别:演绎、猜测、导航和检索。
The V-REX dataset comprises over 700 samples and more than 2,500 questions, covering diverse application scenarios and practical challenges including chart interpretation, time estimation, GUI interpretation, and other related tasks. It encompasses 15 real-world scenarios and is categorized into four reasoning categories: deduction, speculation, navigation, and retrieval.
创建时间:
2025-12-13
原始信息汇总
VREX 数据集概述
数据集基本信息
- 数据集名称:V-REX
- 官方存储库:https://github.com/tianyi-lab/VREX
- HuggingFace 数据集地址:https://huggingface.co/datasets/umd-zhou-lab/V-REX
- 数据集来源:论文《V-REX: Benchmarking Exploratory Visual Reasoning via Chain-of-Questions》的官方评估代码与数据集。
数据集规模与构成
- 样本数量:超过 700 个样本。
- 问题数量:超过 2,500 个问题。
- 任务划分:数据集包含
planning和following两个划分。 - 应用场景:涵盖图表、时间估计、图形用户界面(GUI)解释等多种实际挑战场景。
推理类别与场景
- 推理类别:包含演绎(Deduction)、猜测(Guessing)、导航(Navigation)和检索(Retrieval)四大类别。
- 覆盖场景:包含 15 个真实世界场景,分布于上述四大推理类别中。
数据集主要发现
- 探索的重要性:通过遵循思维链(CoQ)的提示,视觉语言模型在最终问题上的表现持续提升。
- 规模定律:在 VREX 上,模型的性能随规模扩大而提升的规律依然存在。
- 任务表现差异:相同规模的模型在
Following任务上的性能方差小于在Planning任务上的方差。 - 能力贡献:
Following和Planning能力均对模型的整体性能有正向贡献。 - 模型规模影响:较小模型更擅长
Following而非Planning,而较大模型在这两项任务上的表现更为均衡。 - 错误恢复能力:视觉语言模型从失败的
planning步骤中恢复的能力优于从失败的following步骤中恢复的能力。
评估与使用
-
评估模型:已对超过 30 个视觉语言模型进行了广泛评估,涵盖不同规模和大语言模型家族,包括 GPT、Gemini、InternVL2.5、InternVL3、InternVL3.5、Qwen2.5-VL 和 Qwen3-VL 等先进模型。
-
数据加载方式: python from datasets import load_dataset dataset = load_dataset("umd-zhou-lab/V-REX", split="planning") dataset = load_dataset("umd-zhou-lab/V-REX", split="following")
-
评估流程:官方存储库提供了完整的推理与评估代码管道,分别针对
Planning任务和Following任务。
搜集汇总
数据集介绍
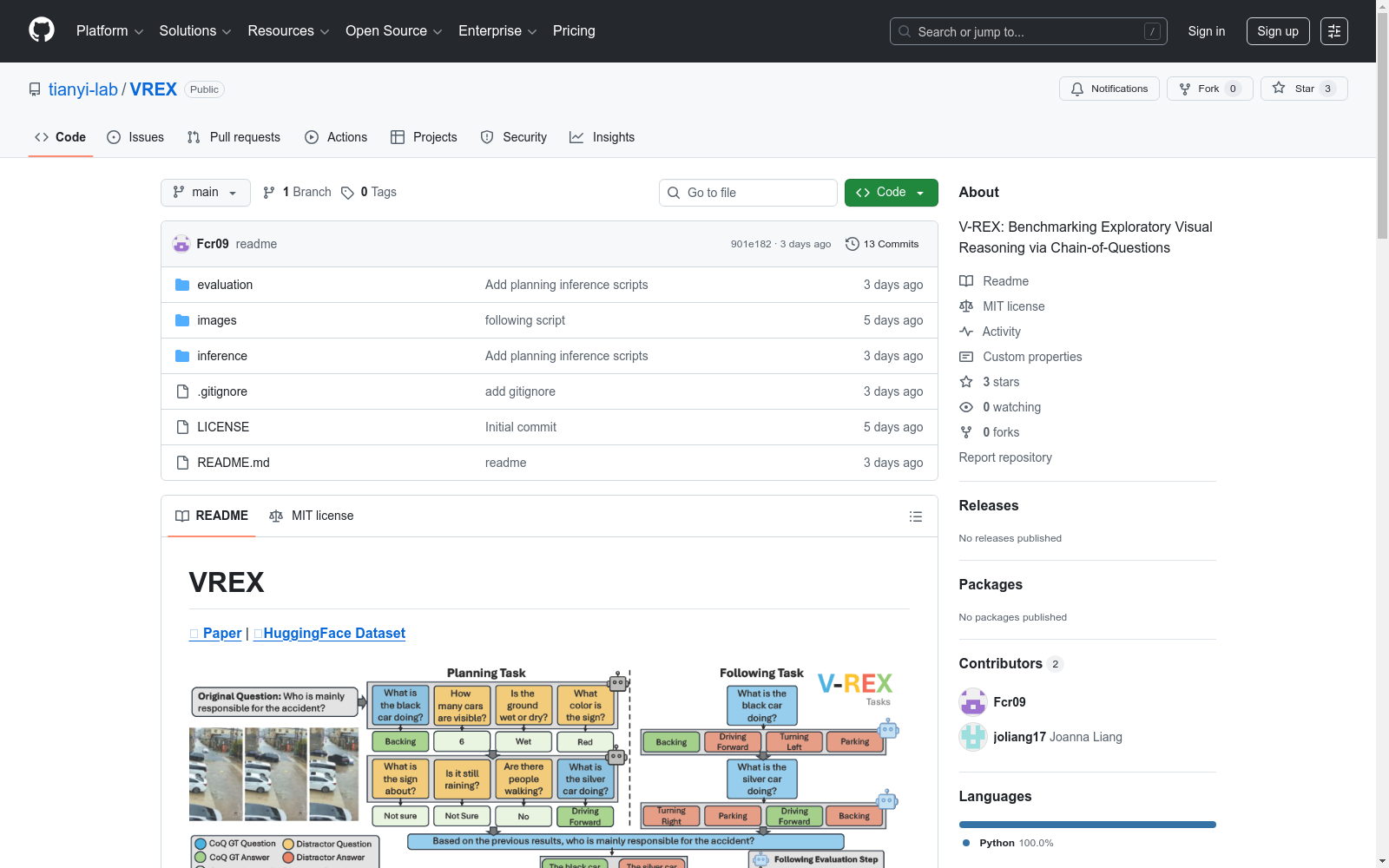
构建方式
在视觉推理领域,V-REX数据集的构建旨在系统评估模型在探索性推理任务中的能力。该数据集通过精心设计,涵盖了15种真实世界场景,并划分为演绎、猜测、导航与检索四大推理类别。其构建过程整合了超过700个样本及2500余个问题,这些问题源自多样化的应用情境,例如图表解析、时间估算与图形用户界面理解等,确保了数据在视觉与语义层面的丰富性与挑战性。
特点
V-REX数据集的核心特点在于其专注于链式问题引导的探索性视觉推理,模拟人类在复杂视觉环境中逐步推理的过程。数据集不仅规模可观,更在任务设计上区分了规划与跟随两种能力评估,从而能够细致衡量模型在不同推理阶段的表现。此外,它覆盖了从图表到实际界面的多种视觉模态,为模型提供了接近现实应用的测试平台,有助于揭示现有视觉语言模型在深层推理中的优势与局限。
使用方法
使用V-REX数据集时,研究人员可通过HuggingFace平台直接加载规划与跟随两个任务分割,便捷地接入现有评估流程。数据集的评估框架提供了完整的推理与评测脚本,支持对多种视觉语言模型进行系统测试。用户可依据任务类型运行相应指令,自动执行模型推断并计算性能指标,从而高效地比较不同模型在探索性视觉推理上的能力,推动该领域的技术进步。
背景与挑战
背景概述
视觉推理作为人工智能领域的关键研究方向,致力于使机器能够像人类一样理解和分析复杂视觉信息。V-REX数据集由马里兰大学周实验室于2024年创建,旨在通过问题链的形式系统评估视觉语言模型在探索性视觉推理任务中的表现。该数据集涵盖700余个样本和2500多个问题,涉及图表解析、时间估算、图形用户界面理解等15种真实场景,并归纳为演绎、猜测、导航和检索四大推理类别。V-REX的构建推动了视觉语言模型在动态推理路径规划与执行能力方面的研究,为多模态人工智能的发展提供了重要的基准测试平台。
当前挑战
V-REX数据集针对探索性视觉推理任务,其核心挑战在于如何模拟人类渐进式认知过程,要求模型在信息不完全的场景中通过自主提问逐步逼近答案。这涉及对视觉元素的动态关注、上下文关联推理以及多步骤决策规划能力的综合考验。在数据集构建过程中,研究人员面临场景多样性平衡、问题链逻辑连贯性设计以及标注一致性维护等难题。同时,如何确保不同难度层级的任务能够有效区分模型的能力边界,并避免数据偏差对评估结果的影响,也是该数据集构建中需要克服的关键技术障碍。
常用场景
经典使用场景
在视觉语言模型(VLMs)的评估领域,V-REX数据集被广泛应用于探索性视觉推理任务的基准测试。其核心场景涉及对复杂视觉内容(如图表、图形用户界面和时间序列图像)进行多轮问答推理,通过规划与跟随两种任务模式,系统评估模型在演绎、猜测、导航和检索等四大推理类别中的表现。这一场景不仅模拟了人类面对未知视觉信息时的渐进式探索过程,还为模型在动态交互环境中的推理能力提供了标准化测试框架。
衍生相关工作
基于V-REX的评估范式,学术界衍生出多项经典研究工作。例如针对规划-跟随能力解耦的模型架构改进方案,以及探索视觉推理中错误恢复机制的专项研究。部分工作借鉴其链式问题设计思路,开发了面向特定领域(如科学图表理解、程序界面交互)的垂直评估基准。这些衍生研究不仅深化了对视觉语言模型认知边界的理解,还推动了交互式视觉推理系统在可解释性方面的技术演进。
数据集最近研究
最新研究方向
在视觉语言模型领域,探索性视觉推理正成为研究焦点。V-REX数据集凭借其涵盖演绎、猜测、导航与检索四大推理类别的七百余样本与两千五百余问题,为评估模型在真实场景下的链式提问能力提供了基准。前沿研究揭示,通过遵循问题链提示,视觉语言模型在最终问题上的表现显著提升,凸显了探索过程对深度推理的重要性。同时,模型规模扩展规律在该数据集上依然成立,而相同规模模型在执行任务时的性能差异在跟随阶段小于规划阶段,表明模型架构与训练策略对复杂视觉任务的影响存在分化。这些发现不仅推动了视觉推理向更细粒度、更动态的交互模式演进,也为构建具备人类般探索与调整能力的多模态智能系统指明了方向。
以上内容由遇见数据集搜集并总结生成


