pubmed_metadata
收藏Hugging Face2025-04-02 更新2025-04-03 收录
下载链接:
https://huggingface.co/datasets/jackkuo/pubmed_metadata
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是一个与生物学、医学和化学相关的数据集,来源于PubMed,特别提到了2023年和2025年的数据。数据集使用英语,并遵循MIT许可证。数据集的具体信息、使用目的、结构和其他关键细节在README中未完全提供,需要更多信息。
This dataset is a biology-, medicine-, and chemistry-related dataset sourced from PubMed, with specific mention of data from 2023 and 2025. The dataset is in English and is released under the MIT License. Specific information, usage purposes, structure, and other key details of the dataset are not fully provided in the README, and additional relevant information is required.
创建时间:
2025-03-28
搜集汇总
数据集介绍
构建方式
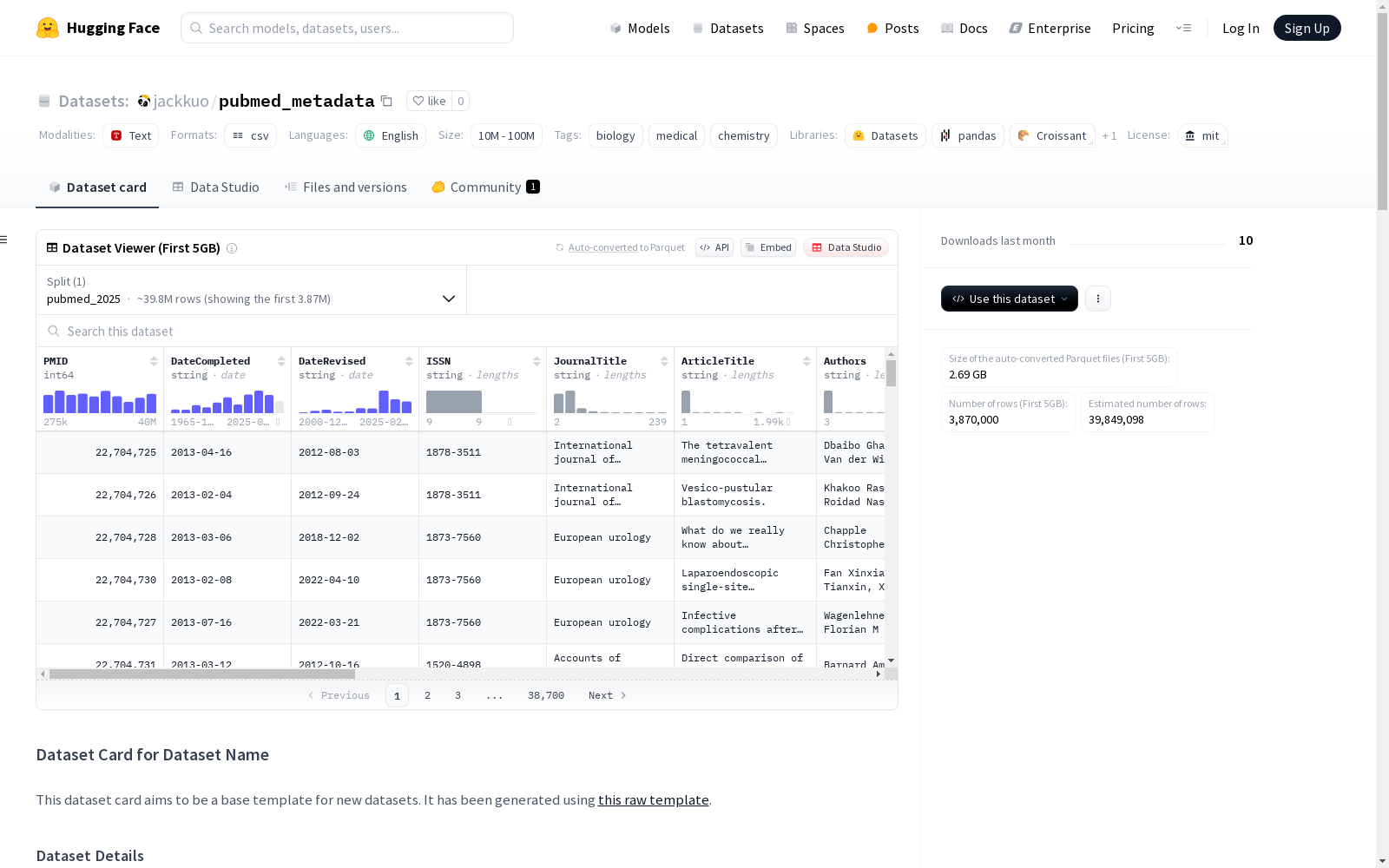
PubMed作为全球最具影响力的生物医学文献数据库,其元数据集的构建采用了系统化的数据采集与处理流程。数据集源自美国国家生物技术信息中心(NCBI)的FTP服务器,通过自动化脚本定期更新2025年的文献元数据。技术团队运用定制化的Python脚本将原始XML格式转换为结构化的CSV文件,确保数据字段的完整性与一致性。整个处理流程涵盖39,292,954条文献记录,每条记录均保留原始数据库的完整元信息架构。
使用方法
研究人员可通过HuggingFace平台直接获取分块存储的CSV文件,建议使用pandas或Dask等工具进行大数据量处理。数据集特别适用于文献计量分析、知识图谱构建等科研场景,使用时需注意遵循MIT许可协议。对于特定年份的数据查询,可利用内置的时间戳字段进行快速筛选。为保持数据时效性,用户可通过配套的download.py脚本实现月度数据更新,process_metadata.py脚本则支持自定义的元数据处理流程。
背景与挑战
背景概述
PubMed作为全球最具影响力的生物医学文献数据库之一,其元数据集的构建始于美国国立生物技术信息中心(NCBI)的长期项目。该数据集收录了超过3900万条经过严格筛选的医学、生物学和化学领域文献记录,时间跨度覆盖数十年的研究成果。2023年由jacobvsdanniel团队首次对全量数据进行系统化处理,2025年版本则由中国国家微生物科学数据中心(NMDC)参与更新维护,采用XML到CSV的标准化转换流程,为知识图谱构建和跨文献关联分析提供了结构化数据基础。
当前挑战
该数据集面临的核心挑战体现在两个方面:在领域问题层面,生物医学术语的快速演进导致实体识别难度剧增,异构文献源的元数据标准差异对知识融合形成障碍;在构建过程中,海量XML文档的分布式解析需要处理高达39GB的原始数据,而每月增量更新机制要求设计高效的版本控制策略。此外,跨机构协作时存在数据质量控制标准不统一的问题,部分早期文献的元数据字段缺失现象亟待解决。
常用场景
经典使用场景
在生物医学研究领域,pubmed_metadata数据集作为PubMed文献数据库的结构化元数据集合,为科研人员提供了便捷的文献检索与分析工具。其经典使用场景包括大规模文献综述、研究趋势分析以及跨学科知识挖掘。通过该数据集,研究者能够高效地追踪特定疾病、药物或生物标志物的研究进展,识别领域内的关键学者与机构,为后续实验设计提供理论依据。
解决学术问题
该数据集有效解决了传统文献调研中耗时耗力、覆盖面有限的问题。其海量的标准化元数据(如标题、作者、摘要、关键词等)支持基于机器学习的信息抽取研究,包括命名实体识别、关系抽取和知识图谱构建。尤其在循证医学领域,通过自动化分析数千万篇文献的关联性,显著提升了系统性综述的可靠性和效率,为临床决策提供数据支撑。
实际应用
在医药企业研发中,该数据集被用于竞品专利监测和药物重定位研究;公共卫生机构则利用其追踪疾病暴发的早期研究信号。智能文献推荐系统通过分析用户历史查询与元数据的语义关联,实现个性化知识推送。疫情期间,全球科研团队曾基于此类数据快速构建新冠病毒相关研究的可视化图谱,加速了疫苗研发进程。
数据集最近研究
最新研究方向
随着生物医学领域的快速发展,pubmed_metadata数据集因其涵盖广泛的医学、生物学和化学文献而成为研究热点。近年来,该数据集在知识图谱构建、药物发现和疾病预测等方向展现出巨大潜力。特别是在人工智能与医学交叉领域,研究者利用其海量元数据训练深度学习模型,以挖掘潜在的生物医学关联。与此同时,该数据集在疫情相关研究中发挥了关键作用,为病毒传播机制和疫苗研发提供了重要数据支持。其规模庞大且持续更新的特性,使其成为推动精准医学和个性化治疗发展的核心资源之一。
以上内容由遇见数据集搜集并总结生成


