GDN-CC; GDN-CC-large
收藏arXiv2026-01-23 更新2026-01-24 收录
下载链接:
https://huggingface.co/datasets/LequeuISIR/GDN-CC
下载链接
链接失效反馈官方服务:
资源简介:
GDN-CC是由索邦大学等机构联合构建的法国公民咨询数据集,包含1,231份手动标注的公民意见文本,涵盖税收、生态转型等四大主题。数据集通过人工与AI协作标注,将原始文本分解为2,285个自包含的论证单元,并标注论证结构(陈述、解决方案、前提)。其扩展版本GDN-CC-large包含24万份自动标注文本,是目前规模最大的民主咨询标注语料库。该数据集旨在通过标准化预处理,使嘈杂的多主题公民意见转化为适合政治分析和主题建模的结构化数据,推动透明化的小型语言模型在民主决策中的应用。
GDN-CC is a French citizen consultation dataset jointly constructed by Sorbonne University and other institutions. It contains 1,231 manually annotated citizen opinion texts spanning four core themes including taxation and ecological transition. Adopting human-AI collaborative annotation, the dataset decomposes raw texts into 2,285 self-contained argumentative units, and annotates their argumentative structures: claims, solutions and premises. Its extended version, GDN-CC-large, includes 240,000 automatically annotated texts, making it the largest annotated corpus for democratic consultation to date. This dataset aims to convert noisy multi-topic citizen opinions into structured data suitable for political analysis and topic modeling via standardized preprocessing, so as to promote the application of transparent small-scale language models in democratic decision-making.
提供机构:
索邦大学; 索邦大学·STIH/CERES; 巴黎综合理工大学·CREST
创建时间:
2026-01-21
原始信息汇总
数据集概述:GDN-CC
数据集基本信息
- 数据集名称:GDN-CC
- 托管地址:https://huggingface.co/datasets/LequeuISIR/GDN-CC
- 许可协议:MIT
- 语言:法语 (fr)
- 标注创建者:专家生成 (expert-generated)
- 数据规模:小于3,000条 (n<3k)
- 源数据集:Grand Débat National
- 任务类别:文本分类、文本生成
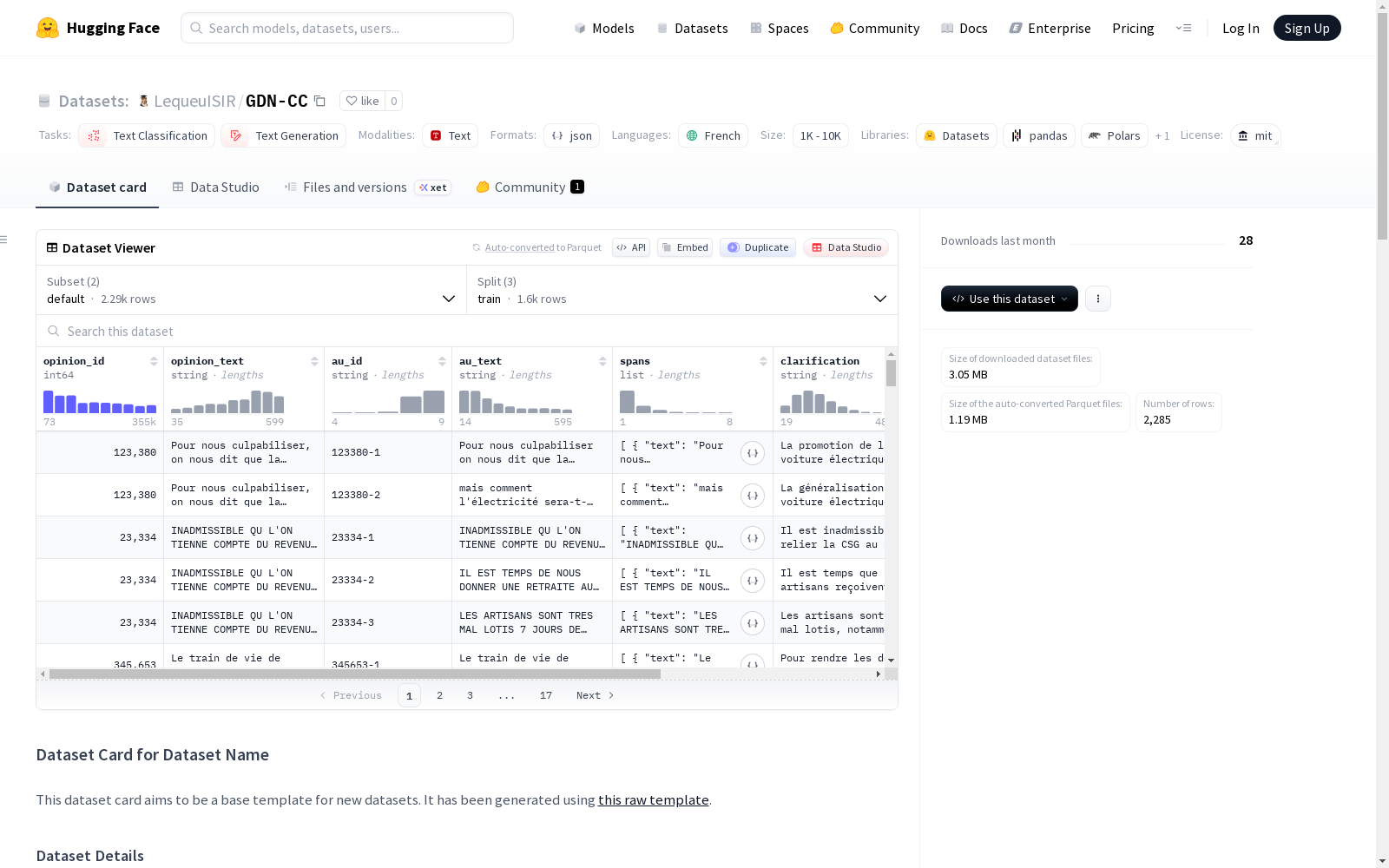
数据集结构
数据集包含两个配置(configs),每个配置下有不同的数据文件划分。
配置1:default
- 数据文件:
- 训练集:GDNCC_data_train.jsonl
- 测试集:GDNCC_data_test.jsonl
- 验证集:GDNCC_data_valid.jsonl
配置2:AU_detection
- 数据文件:
- 训练集:GDNCC_AU_detection_train.jsonl
- 测试集:GDNCC_AU_detection_test.jsonl
- 验证集:GDNCC_AU_detection_valid.jsonl
- 语料库:GDNCC_AU_detection.jsonl
其他信息
- 数据集描述:未提供详细信息。
- 策划者:未提供详细信息。
- 资金来源:未提供详细信息。
- 共享者:未提供详细信息。
- 数据集来源:未提供详细信息。
- 直接用途:未提供详细信息。
- 超范围用途:未提供详细信息。
- 数据集结构详情:未提供详细信息。
- 创建理由:未提供详细信息。
- 源数据收集与处理:未提供详细信息。
- 源数据生产者:未提供详细信息。
- 标注信息:未提供详细信息。
- 标注者:未提供详细信息。
- 个人与敏感信息:未提供详细信息。
- 偏见、风险与限制:未提供详细信息。
- 推荐建议:用户应了解数据集的风险、偏见和限制,但未提供进一步详细信息。
- 引用信息:未提供详细信息。
- 术语表:未提供详细信息。
- 更多信息:未提供详细信息。
- 数据集卡片作者:未提供详细信息。
- 数据集卡片联系人:未提供详细信息。
搜集汇总
数据集介绍
构建方式
在民主协商文本分析领域,GDN-CC数据集的构建采用了严谨的人工标注与AI辅助相结合的方法。该数据集以2019年法国“全国大辩论”的公民贡献文本为基础,首先对原始语料进行过滤,保留长度适中、内容相关的24万条贡献。随后,由五位政治科学专业的标注者遵循统一的标注指南,对1231条贡献进行人工处理。标注过程分为两个核心步骤:首先进行论元单元分割与论元结构检测,将文本分解为聚焦单一主题的论元单元,并识别其中的陈述、前提与解决方案三类论元成分;随后,借助包括GPT-4.1在内的多种大语言模型生成初步的论元单元澄清文本,再由标注者进行人工修订与验证,最终形成了包含2285个论元单元的高质量标注语料。
特点
GDN-CC数据集展现出多方面的显著特点。其核心价值在于首次为大规模民主协商文本的“语料澄清”任务提供了高质量的人工标注基准,涵盖了税收、生态转型、国家组织与民主公民权四大主题。数据内部结构丰富,不仅包含原始的公民贡献文本,还提供了经过分割的论元单元、精细的论元结构标签以及人工修订后的澄清文本。统计分析显示,数据中解决方案类论元占比最高,反映了公民参与的政策导向性,而不同主题间论元类型的分布差异则揭示了公民讨论焦点的微妙变化。此外,该数据集通过严格的跨标注者一致性评估,确保了标注结果的高可靠性,为相关自然语言处理任务的模型训练与评估提供了坚实的数据基础。
使用方法
该数据集主要服务于自然语言处理与政治科学交叉领域的研究与应用。研究者可利用GDN-CC训练和评估模型在论元单元分割、论元结构检测以及论元单元澄清等序列任务上的性能。其标注体系直接支持对公民意见进行标准化与结构化处理,从而为下游的主题建模、意见聚类、情感分析或政策提案提取等任务提供高质量的输入。例如,在聚类任务中,使用澄清后的论元单元相较于原始文本能产生主题更一致、边界更清晰的聚类结果。数据集通常以标准格式发布,用户可按需加载贡献文本、对应论元单元、结构标签及澄清文本,并按照训练、验证、测试划分进行模型开发与实验。
背景与挑战
背景概述
GDN-CC与GDN-CC-large数据集由法国索邦大学等机构的研究团队于2026年发布,旨在应对人工智能在民主公民咨询分析中的伦理与透明度挑战。该数据集基于2019年法国'大国民辩论'的公民贡献,通过人工标注与自动扩展,构建了涵盖税收、生态转型、国家组织及民主四大主题的论证单元库。其核心研究问题聚焦于如何将嘈杂、多主题的公民文本转化为结构化、自包含的论证单元,以支持可解释的政治分析与主题建模,推动透明化NLP工具在民主进程中的应用。
当前挑战
该数据集致力于解决民主咨询文本分析中的领域挑战,即如何从自由形式、多主题的公民贡献中提取清晰、可操作的论证单元,以提升聚类、主题建模等下游任务的可靠性与可解释性。在构建过程中,研究团队面临多重挑战:一是标注复杂性,需设计兼顾论证结构识别与单元澄清的多步骤标注框架,并确保标注者间的一致性;二是模型依赖性,需平衡大型语言模型的性能与透明度,探索小型开源模型在本地化部署中的可行性;三是数据噪声处理,需克服公民文本中存在的语法不规则、主题混杂及表述模糊等问题,确保标注质量与下游应用的稳健性。
常用场景
经典使用场景
在民主协商与政治话语分析领域,GDN-CC数据集为大规模公民咨询文本的结构化处理提供了典范。该数据集最经典的使用场景在于其作为语料库澄清任务的基准,通过人工标注的1,231条法国“大国民辩论”贡献,将原始嘈杂、多主题的公民意见转化为清晰、自包含的论证单元。研究者利用这一数据集训练和评估小型语言模型,使其能够自动执行论证单元提取、论证结构检测和文本澄清等步骤,从而为后续的主题建模、意见聚类等分析任务提供标准化输入。
解决学术问题
GDN-CC数据集主要解决了大规模民主协商中文本处理的若干核心学术问题。首先,它针对公民贡献的噪声性和多主题混合问题,提出了语料库澄清框架,将复杂文本分解为结构化的论证单元,提升了下游分析的可靠性。其次,该数据集推动了小型、开源权重语言模型在政治文本分析中的应用,证明经过微调的模型能够媲美甚至超越大型专有模型,从而缓解了对不透明、私有化AI系统的依赖。此外,数据集通过标注论证结构(陈述、前提、解决方案),为论证挖掘研究提供了高质量的法国语料,填补了该语言在民主话语分析中的资源空白。
衍生相关工作
围绕GDN-CC数据集,已衍生出一系列重要的相关研究工作。在方法论上,该研究启发了对小型语言模型在政治文本处理中效能的深入探索,如基于Qwen2.5-7B和Gemma-2-9B等模型的微调实验,证明了资源受限环境下高性能分析的可能性。在应用层面,该数据集的澄清流程被整合进意见聚类系统,显著提升了BERTopic等工具在主题一致性上的表现。同时,研究团队发布的GDN-CC-large作为迄今最大的标注民主协商语料库,为政治学、计算社会科学等领域的学者提供了宝贵的资源,推动了跨学科关于AI增强民主的实证研究。
以上内容由遇见数据集搜集并总结生成


