KnowMe-Bench
收藏github2026-01-09 更新2026-01-10 收录
下载链接:
https://github.com/QuantaAlpha/KnowMeBench
下载链接
链接失效反馈官方服务:
资源简介:
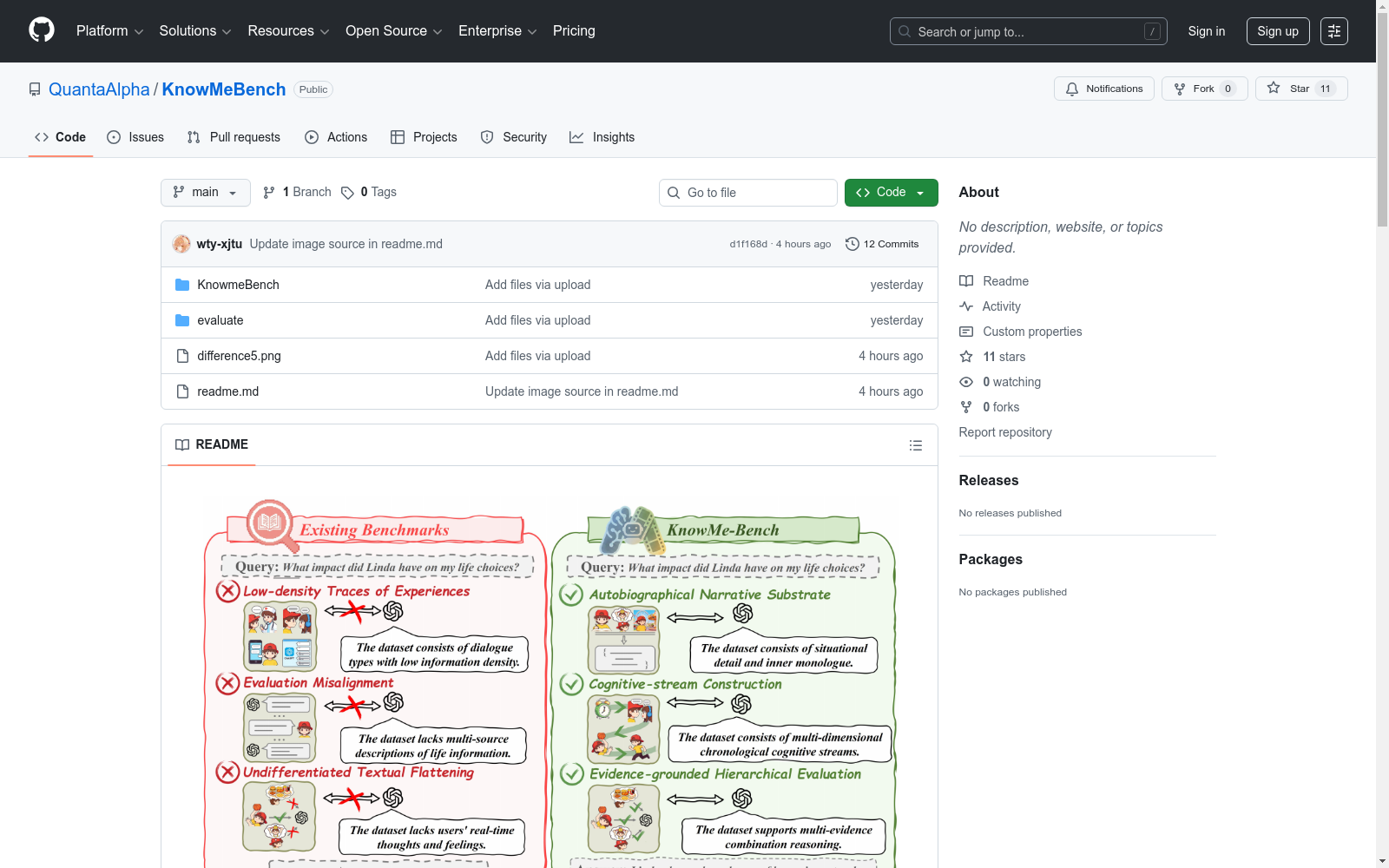
KnowMe-Bench是一个基准测试,旨在评估终身数字伴侣中的人物理解能力。它基于长篇自传体叙事(4.7M tokens)构建,保留了人类经验的“微观纹理”——行动、内心想法和环境背景。数据集包含2,580个评估查询,涵盖7个任务,从事实回忆到心理分析推理。
KnowMe-Bench is a benchmark designed to evaluate person understanding capabilities in lifelong digital companions. It is constructed based on long-form autobiographical narratives (4.7M tokens) and preserves the 'micro-textures' of human experience: actions, internal thoughts, and contextual backgrounds. The dataset contains 2,580 evaluation queries spanning 7 tasks, ranging from factual recall to psychoanalytic reasoning.
创建时间:
2026-01-08
原始信息汇总
KnowMe-Bench 数据集概述
数据集简介
KnowMe-Bench 是一个旨在评估终身数字伴侣中人物理解能力的基准测试。与依赖稀疏对话记录的现有基准不同,该数据集构建于长篇自传体叙事(470万词元)之上,保留了人类经验的“微观纹理”——包括行动、内心想法和环境背景。
核心特征
- 自传体叙事基底:源自多样化的文学来源(包括克瑙斯高的《我的奋斗》),保留了聊天数据集中常丢失的高密度内心独白和情境细节。
- 认知流构建:将叙事重构为具有5个不同字段的时间锚定流:视觉、听觉、上下文、背景和内心独白。
- 记忆重对齐:专门处理非线性时间结构(闪回),以防止记忆系统中的“更新悖论”错误。
- 分层评估:包含3个层级、覆盖7项任务的评估套件,从事实回忆到精神分析推理。
数据集统计
基准测试包含2,580个评估查询,源自470万词元的源文本。
| 数据集 | 来源 | 特征 | 关键挑战 |
|---|---|---|---|
| D1 | 《我的奋斗》 | 闪回密集 | 处理非线性时间与记忆触发 |
| D2 | 《那不勒斯四部曲》 | 事件驱动 | 追踪线性因果链与实体更新 |
| D3 | 《追忆似水年华》 | 心理深度 | 解释抽象的内心独白 |
评估任务
评估涵盖三个认知层级:
层级 I:精确性与事实性(“记忆”层)
- T1:上下文感知提取:时空约束下的实体回忆。
- T2:对抗性弃权:测试对“不匹配陷阱”幻觉的抵抗力。
- T3:时间推理:持续时间计算与时间线重建。
层级 II:叙事逻辑与因果性(“推理”层)
- T4:逻辑事件排序:基于语义维度(如危险升级)进行排序。
- T5:记忆触发分析:识别触发记忆的感觉线索。
层级 III:精神分析深度(“洞察”层)
- T6:身心交互:解释讽刺/矛盾行为。
- T7:专家标注的精神分析:关于动机和身份的深度推理。
基准结果摘要
评估了包括Naive RAG、Mem0和MemOS在内的多个系统。结果显示,虽然检索系统提高了事实准确性,但在时间逻辑和深度洞察方面存在困难。
| 模型 | 系统 | T1(细节) | T3(时间) | T6(洞察) |
|---|---|---|---|---|
| Qwen3-32B | 基础 | 59.9 | 44.4 | 14.3 |
| + MemOS | 70.6 | 52.7 | 18.2 | |
| GPT-5-mini | 基础 | 65.4 | 54.1 | 18.6 |
| + MemOS | 76.1 | 63.1 | 22.5 |
隐私与伦理
数据集中的所有数据均经过严格的上下文感知去标识化流程。关键实体被映射为假名(例如,“Elena” → “Subject_A”),地理位置标记被粗化以确保隐私。
引用
若在研究中使用KnowMe-Bench,请引用相关论文。
联系方式
如有疑问,请联系:
- Qizhen Lan:
Qizhen.Lan@uth.tmc.edu - Ronghao Chen:
chenronghao@alumni.pku.edu.cn - Huacan Wang:
wanghuacan17@mails.ucas.ac.cn
搜集汇总
数据集介绍
构建方式
在构建终身数字伴侣的评估基准时,KnowMe-Bench 采用了一种基于自传体叙事文本的创新方法。数据集源自《我的奋斗》等长篇文学著作,总计包含470万词元的原始文本,这些文本富含高密度的内心独白与环境细节。通过多智能体生成流程,原始叙事被重构为具有时间锚点的认知流,涵盖视觉、听觉、背景与内心独白五个维度,并特别处理了闪回等非线性时间结构,以避免记忆更新悖论,从而精准保留了人类经验的微观纹理。
使用方法
使用 KnowMe-Bench 时,研究者可通过克隆代码库并安装依赖快速启动评估流程。数据集支持对多种模型系统进行测试,包括基础模型与增强记忆架构。评估涵盖七个具体任务,从上下文感知提取到专家标注的心理分析,用户可运行提供的脚本在三个叙事子集上验证模型表现。为确保隐私伦理,所有数据均经过上下文感知的去标识化处理,实体名称与地理位置信息已被妥善匿名,使得该基准既能用于前沿研究,又符合数据使用的伦理规范。
背景与挑战
背景概述
在人工智能与认知科学交叉领域,构建能够深度理解人类个体、具备长期记忆与共情能力的数字伴侣,已成为一项前沿研究目标。KnowMe-Bench基准数据集于2026年由Tingyu Wu、Zhisheng Chen、Ronghao Chen等研究人员提出,旨在系统评估模型在‘人物理解’这一核心问题上的能力。该数据集以总计470万词元的长篇自传体叙事为基底,突破了传统对话日志的稀疏性局限,致力于捕捉人类经验中细腻的行为、内在思绪与环境上下文,为数字伴侣的终身学习与交互研究提供了关键评估工具,显著推动了该领域向更细腻、更连贯的人物建模方向发展。
当前挑战
KnowMe-Bench所针对的‘人物理解’任务,其核心挑战在于模型需从非线性、高密度的叙事流中,精准提取并整合时空锚定的细节,同时进行深层的心理动机推理。具体而言,构建过程面临多重困难:一是处理文学文本中频繁出现的闪回等非线性时间结构,需通过‘记忆重对齐’机制避免更新悖论;二是保留并结构化内部独白、感官线索等微观纹理信息,这对数据标注与表示提出了极高要求;三是确保在实体消歧、时间线重建等任务中,模型能抵抗幻觉干扰,实现事实性与逻辑性并重的推理。这些挑战共同定义了数字伴侣在实现真正‘理解’道路上必须跨越的认知鸿沟。
常用场景
经典使用场景
在人工智能与认知计算领域,KnowMe-Bench作为一项专注于人物理解的基准测试,其经典应用场景在于评估终身数字伴侣系统对长篇幅自传体叙事的解析能力。该数据集通过重构时间锚定的认知流,模拟人类经验中的微观纹理,为模型提供了包含视觉、听觉、背景与内心独白等多维度信息的叙事环境。研究人员利用这一基准,能够系统性地测试模型在非线性的时间结构(如倒叙)中保持记忆一致性的表现,从而推动数字伴侣向更自然、更深入的人际交互演进。
解决学术问题
KnowMe-Bench致力于解决人物理解研究中的核心学术问题,即如何让机器学习模型超越浅层的对话日志分析,深入捕捉人类行为、内在思维与环境语境之间的复杂关联。该数据集通过引入高密度的内心独白与情境细节,有效应对了传统聊天数据集常丢失的“记忆更新悖论”与幻觉生成挑战。其意义在于为评估模型在事实回忆、时间推理乃至心理分析等层次上的认知能力提供了标准化框架,进而促进了人工智能在理解人类主观体验方面的理论突破与方法创新。
实际应用
在实际应用层面,KnowMe-Bench为开发具备长期记忆与深度共情能力的数字伴侣系统提供了关键评估工具。这类系统可广泛应用于个性化教育助手、心理健康支持平台以及智能叙事生成等领域,通过理解用户的个人经历与情感脉络,提供更贴合情境的交互回应。例如,在心理辅导场景中,基于该数据集训练的模型能够分析用户自述中的矛盾行为与潜在动机,辅助专业人士进行更精准的情感支持与行为解读。
数据集最近研究
最新研究方向
在人工智能与数字伴侣领域,KnowMe-Bench作为专注于人物理解的基准测试,正推动着相关研究向纵深发展。其基于长篇自传叙事构建的认知流结构,为模型处理非线性时间序列与记忆触发机制提供了独特挑战,促使研究者探索如何更精准地捕捉人类经验的微观纹理。当前前沿工作集中于提升模型在时序推理与心理分析层面的表现,例如通过记忆系统优化来缓解更新悖论,并利用对抗性弃权任务增强抗幻觉能力。这些进展不仅深化了对数字伴侣长期互动中人物建模的理解,也为构建具备深层共情与持续学习能力的智能系统奠定了实证基础。
以上内容由遇见数据集搜集并总结生成


