ReasonBench
收藏arXiv2025-08-01 更新2025-08-05 收录
下载链接:
https://huggingface.co/datasets/cistine/ReasonBench
下载链接
链接失效反馈官方服务:
资源简介:
ReasonBench是一个包含1613个真实世界图形推理问题的数据集,旨在评估视觉语言模型(VLMs)在复杂图形推理任务中的性能。数据集从三个主要来源收集:中国公务员行政职业能力测验、门萨智力测试和拉文渐进矩阵。ReasonBench涵盖11个认知维度,进一步细分为29个不同的任务类型。该数据集的多源层次结构使得可以全面评估VLMs在多种推理范式下的分析能力。
ReasonBench is a dataset containing 1,613 real-world graphical reasoning problems, designed to evaluate the performance of Vision-Language Models (VLMs) on complex graphical reasoning tasks. The dataset is collected from three primary sources: China's Civil Servant Administrative Professional Aptitude Test, Mensa IQ tests, and Raven's Progressive Matrices. ReasonBench covers 11 cognitive dimensions, which are further subdivided into 29 distinct task types. The multi-source hierarchical structure of this dataset enables a comprehensive assessment of VLMs' analytical capabilities across diverse reasoning paradigms.
提供机构:
北京电子科技学院
创建时间:
2025-08-01
原始信息汇总
ReasonBench 数据集概述
基本信息
- 许可证: Apache-2.0
- 语言: 中文、英文
- 标签: VLM、benchmark、graphic-reasoning、intelligence-test
数据集简介
ReasonBench 是一个用于评估视觉语言模型(VLMs)在复杂图形推理任务表现的基准测试。数据集包含从真实智力测试中收集的 1,613个问题,覆盖11个核心认知维度和29种任务类型,为评估VLMs的空间、关系和抽象推理能力提供综合框架。
数据集结构
核心认知维度与任务类型
| 认知维度 | 任务类型 | 数量 |
|---|---|---|
| 位置规律 | 平移 | 94 |
| 旋转 | 56 | |
| 组合 | 30 | |
| 样式规律 | 穿越 | 54 |
| 加减法 | 67 | |
| 黑白运算 | 63 | |
| 属性规律 | 对称 | 109 |
| 开闭状态 | 19 | |
| 组合 | 6 | |
| 数量规律 | 线 | 173 |
| 面 | 137 | |
| 点 | 66 | |
| 元素 | 94 | |
| 组合 | 50 | |
| 空间规律 | 立方体 | 109 |
| 3D | 46 | |
| 多面体 | 17 | |
| 三视图 | 40 | |
| 剖视图 | 35 | |
| 空间数量变换 | 10 | |
| 特殊规律 | 2D组合 | 31 |
| 图形关系 | 40 | |
| 字母数字 | 字母数字 | 27 |
| 黑白块 | 黑白块 | 32 |
| 其他规律 | 综合 | 34 |
| 门萨 | 任务1 | 35 |
| 任务2 | 39 | |
| 瑞文 | 任务1 | 40 |
| 任务2 | 60 |
输入格式
| 格式 | 描述 |
|---|---|
| 集成格式 | 问题与选项呈现在单个图形中,便于模型整体处理 |
| 分离格式 | 将问题与选项拆分为多个图形,测试分步推理能力 |
核心特性
- 多格式评估: 支持整体式和分隔式两种输入格式
- 完全开放: 公开所有格式的图片URL(题目、选项、题目+选项)
- 人类基准: 提供人类准确率作为参考基准
- 多样化任务: 覆盖11个认知维度的29种推理任务
论文信息
- 标题: Oedipus and the Sphinx: Benchmarking and Improving Visual Language Models for Complex Graphic Reasoning
- 作者: Jianyi Zhang, Xu Ji, Ziyin Zhou, Yuchen Zhou, Shubo Shi, Haoyu Wu, Zhen Li, Shizhao Liu
- arXiv链接: https://arxiv.org/abs/2508.00323
- 年份: 2025
搜集汇总
数据集介绍
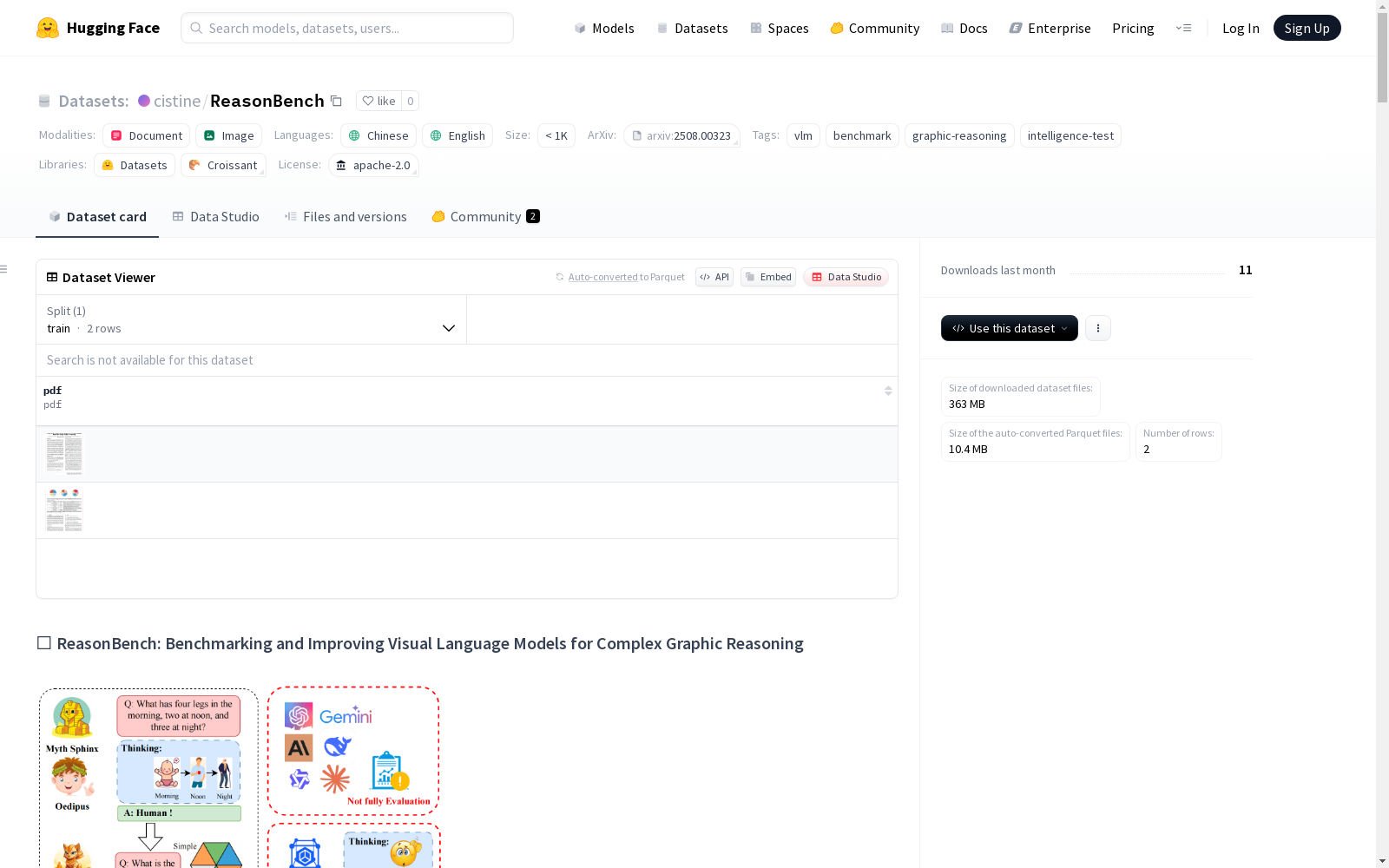
构建方式
ReasonBench数据集通过系统整合来自中国公务员能力倾向测验、门萨智力测试和瑞文渐进矩阵三大真实世界测试源的1,613道图形推理题目构建而成。研究团队采用分层抽样策略,确保题目覆盖11个核心认知维度(如位置关系、样式变换、属性识别等)和29种任务类型。数据采集过程严格遵循标准化协议,通过三重控制评估机制(包括选项均衡分布、固定应答模板和Pass@1评分标准)保证数据的可靠性与可比性。所有图形均转化为标准化API格式,确保不同视觉语言模型的输入一致性。
特点
该数据集具有多维认知覆盖性和真实场景迁移性两大核心特征。其题目设计模拟人类智力测试的复杂推理场景,涵盖从基础的空间变换到高阶的多元素关系推理等认知层次。数据分布上严格控制选项出现频率(波动范围±0.7%),并保留原始测试的6-8选项设置以维持真实评估环境。特别设计的整合与分离双输入格式(integrated/separated)支持模型输入策略的对比研究。数据标注包含详细的人类基准表现(平均准确率68.7%)和细粒度错误分析,为模型诊断提供立体化参照系。
使用方法
使用该数据集时需遵循标准化评估流程:首先将问题以整合或分离格式输入模型,采用固定提示模板确保输入一致性;模型输出需符合结构化响应格式(如<ans>optionX</ans>)。评估采用Pass@1单次尝试计分法,通过自动关键词提取分析响应内容。对于方法优化研究,建议划分200题的独立验证集进行横向对比。高级用法包括结合提出的Diagrammatic Chain-of-Thought(DiaCoT)可视化推理链进行分层次解析,或通过ReasonTune微调策略增强模型归纳推理能力。数据仓库提供完整的评估代码和人类表现基线以供参照。
背景与挑战
背景概述
ReasonBench是由北京电子科技学院的研究团队于2025年提出的首个专注于结构化图形推理任务的评估基准。该数据集包含来自真实世界智力测试的1,613个问题,覆盖位置、属性、数量和多元素任务等11个认知维度。ReasonBench的创建旨在解决现有视觉语言模型(VLMs)在复杂图形推理能力评估方面的不足,特别是在空间、关系和抽象推理方面的表现。该数据集通过系统性地评估11个主流VLMs(包括闭源和开源模型),揭示了当前模型在复杂图形推理任务中的显著局限性,为相关领域的研究提供了重要的基准参考。
当前挑战
ReasonBench主要解决视觉语言模型在复杂图形推理任务中的评估挑战。领域问题方面的挑战包括:1)现有评估基准如Raven和CLEVR缺乏多样性,无法全面评估模型的推理能力;2)VLMs在模拟人类级图形推理能力方面存在明显缺陷,最佳模型准确率仅为27%,远低于人类基准68.7%。构建过程中的挑战包括:1)从多个真实世界智力测试来源收集和标准化1,613个问题;2)设计覆盖11个认知维度的综合评估框架;3)建立三重控制评估协议以确保测量可靠性和跨模型可比性;4)创建人类表现基线作为未来模型改进的参考。
常用场景
经典使用场景
ReasonBench作为首个专注于结构化图形推理任务的评估基准,其经典使用场景在于系统性地测评视觉语言模型(VLMs)在复杂图形推理任务中的表现。该数据集通过整合来自公务员考试、门萨智力测试等真实场景的1613道题目,覆盖位置、属性、数量等多维度推理任务,为研究者提供了标准化的测试平台。在实验中,研究者可基于11种认知维度的分层评估,精确量化模型在空间关系、抽象推理等核心能力上的优劣,尤其适用于对比不同架构VLMs在人类级图形理解任务中的差距。
解决学术问题
ReasonBench有效解决了视觉语言模型评估领域的三大学术问题:其一,填补了复杂图形推理系统性评估的空白,突破传统基准(如CLEVR)仅关注简单几何问题的局限;其二,通过三重控制评估协议(选项均衡分布、固定输入模板、Pass@1评分)消除了非认知因素干扰,提升了测评结果的可靠性;其三,建立人类表现基线(平均准确率68.7%),为模型优化提供了明确的参照系。该数据集揭示了当前顶尖VLMs平均准确率仅27%的关键缺陷,推动了针对图形认知瓶颈的改进研究。
衍生相关工作
该数据集催生了多项创新性研究:基于ReasonBench的缺陷分析,研究者提出DiaCoT和ReasonTune双优化框架,将VLMs图形推理准确率提升33.5%;其分层评估方法启发了PuzzleVQA对单/双元素推理的专项研究;数据集构建方法论被Mementos等动态推理基准借鉴。相关成果发表于NeurIPS等顶会,推动形成了「诊断-优化-验证」的VLM能力提升范式,衍生出视觉链式推理、渐进式微调等技术分支。
以上内容由遇见数据集搜集并总结生成


