car-dataset-repo
收藏官方服务:
资源简介:
该数据集主要用于视觉问答任务,涉及汽车和图像相关的内容。数据来源于auto-data.net,数据集大小在10,000到100,000条记录之间。
This dataset is primarily designed for the Visual Question Answering (VQA) task, focusing on content related to automobiles and images. It is sourced from auto-data.net and contains between 10,000 and 100,000 records.
创建时间:
2025-01-17
搜集汇总
数据集介绍
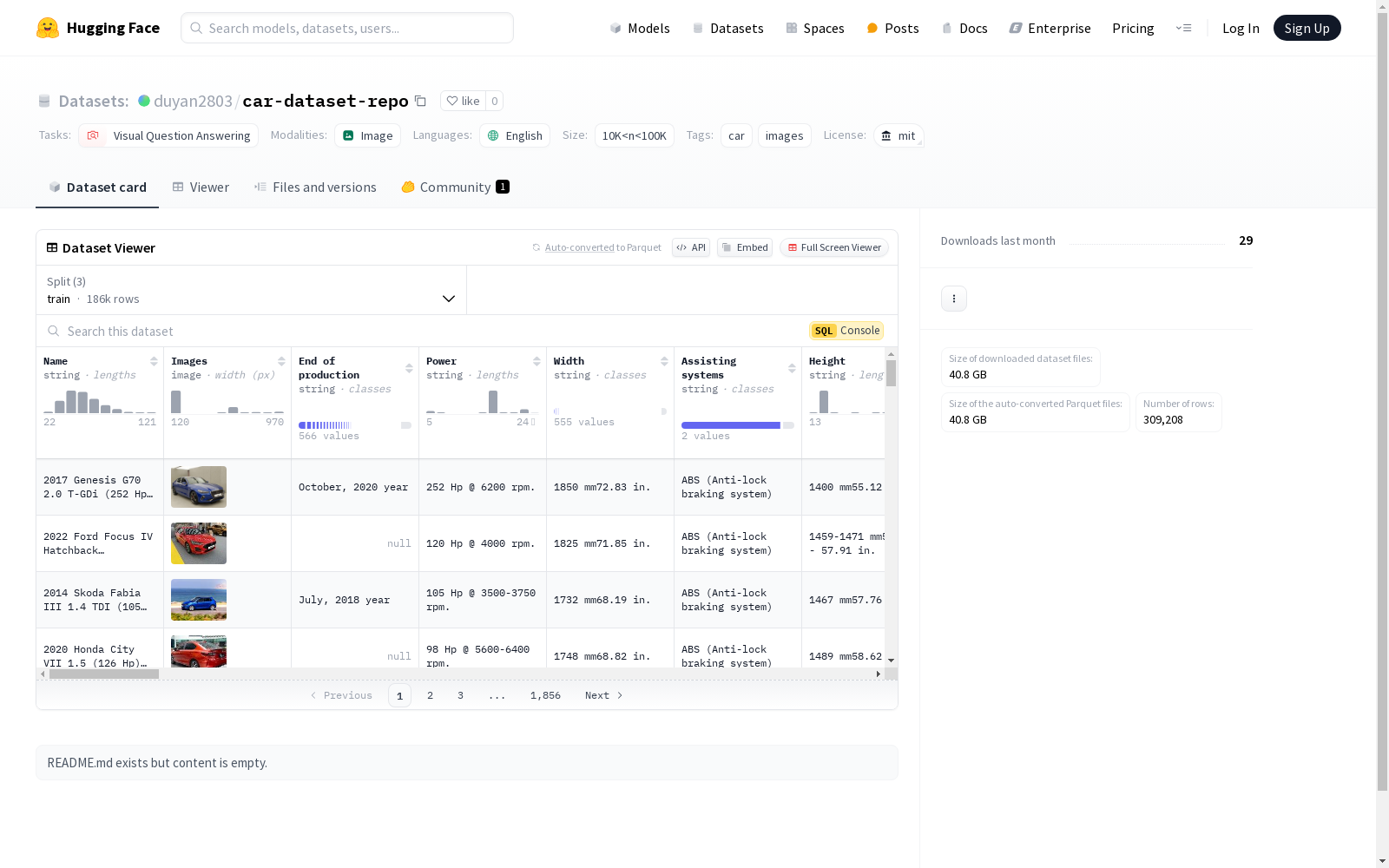
构建方式
car-dataset-repo数据集构建于汽车领域的广泛数据收集,主要来源于auto-data.net网站。该数据集通过自动化爬虫技术,从公开的汽车信息数据库中提取了包括品牌、型号、发动机配置、车身类型等在内的多维度数据。数据经过清洗和标准化处理,确保了信息的准确性和一致性。数据集被划分为训练集、测试集和验证集,以便于机器学习模型的训练和评估。
使用方法
car-dataset-repo数据集适用于多种机器学习任务,特别是在视觉问答和汽车技术分析领域。用户可以通过HuggingFace平台直接下载数据集,利用其提供的训练集、测试集和验证集进行模型训练和性能评估。数据集的结构化格式便于数据科学家和研究人员进行数据探索和特征工程,同时,其丰富的元数据也为深入分析提供了便利。
背景与挑战
背景概述
car-dataset-repo数据集由auto-data.net提供,专注于汽车领域的视觉问答任务。该数据集涵盖了超过10万条汽车相关数据,包含品牌、型号、发动机配置、车身类型、燃油类型等详细信息。数据集的创建旨在为汽车领域的视觉问答系统提供丰富的多模态数据支持,推动汽车信息检索、智能问答系统等领域的研究与应用。auto-data.net作为数据来源,确保了数据的权威性与广泛性,使得该数据集在汽车信息处理领域具有重要的研究价值。
当前挑战
car-dataset-repo数据集在解决汽车领域的视觉问答问题时面临多重挑战。首先,汽车数据的多样性与复杂性要求模型能够处理多模态信息,如图像与文本的联合理解。其次,数据集中包含大量技术性术语与专业属性,如发动机配置、燃油系统等,这对模型的领域知识理解能力提出了较高要求。此外,数据集的构建过程中,如何确保数据的准确性、一致性与完整性也是一大挑战,尤其是在处理来自不同来源的汽车信息时,数据清洗与标准化工作尤为关键。
常用场景
经典使用场景
在汽车视觉问答领域,car-dataset-repo数据集被广泛应用于训练和测试视觉问答模型。该数据集包含了丰富的汽车图像及其详细的技术规格,使得研究人员能够构建模型来回答关于汽车特性的复杂问题。通过结合图像和文本数据,模型能够学习到汽车的多维度特征,从而实现精准的视觉问答。
解决学术问题
car-dataset-repo数据集解决了汽车视觉问答领域中的关键问题,即如何有效地结合图像和文本信息来回答复杂的汽车技术问题。该数据集提供了大量的汽车图像及其详细的技术规格,使得研究人员能够开发出能够理解并回答关于汽车特性的模型。这不仅推动了视觉问答技术的发展,还为汽车行业的智能化应用提供了理论基础。
实际应用
在实际应用中,car-dataset-repo数据集被广泛用于汽车销售平台、汽车维修服务以及汽车保险行业。通过利用该数据集训练的模型,平台能够自动回答用户关于汽车技术规格的查询,提升用户体验。此外,该数据集还可用于汽车维修诊断系统,帮助技术人员快速获取车辆的技术信息,提高维修效率。
数据集最近研究
最新研究方向
在汽车视觉问答领域,car-dataset-repo数据集因其丰富的汽车图像和详细的技术规格信息,成为研究热点。近年来,研究者们利用该数据集开发了多种深度学习模型,旨在提升汽车图像识别和问答系统的准确性。特别是在自动驾驶和智能交通系统的研究中,该数据集的应用显著推动了相关技术的进步。通过结合图像处理和自然语言处理技术,研究者们能够更精确地解析汽车图像中的复杂信息,从而为智能汽车的发展提供了强有力的数据支持。
以上内容由遇见数据集搜集并总结生成


