Publishing/unclutching-corpus-v1
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/Publishing/unclutching-corpus-v1
下载链接
链接失效反馈官方服务:
资源简介:
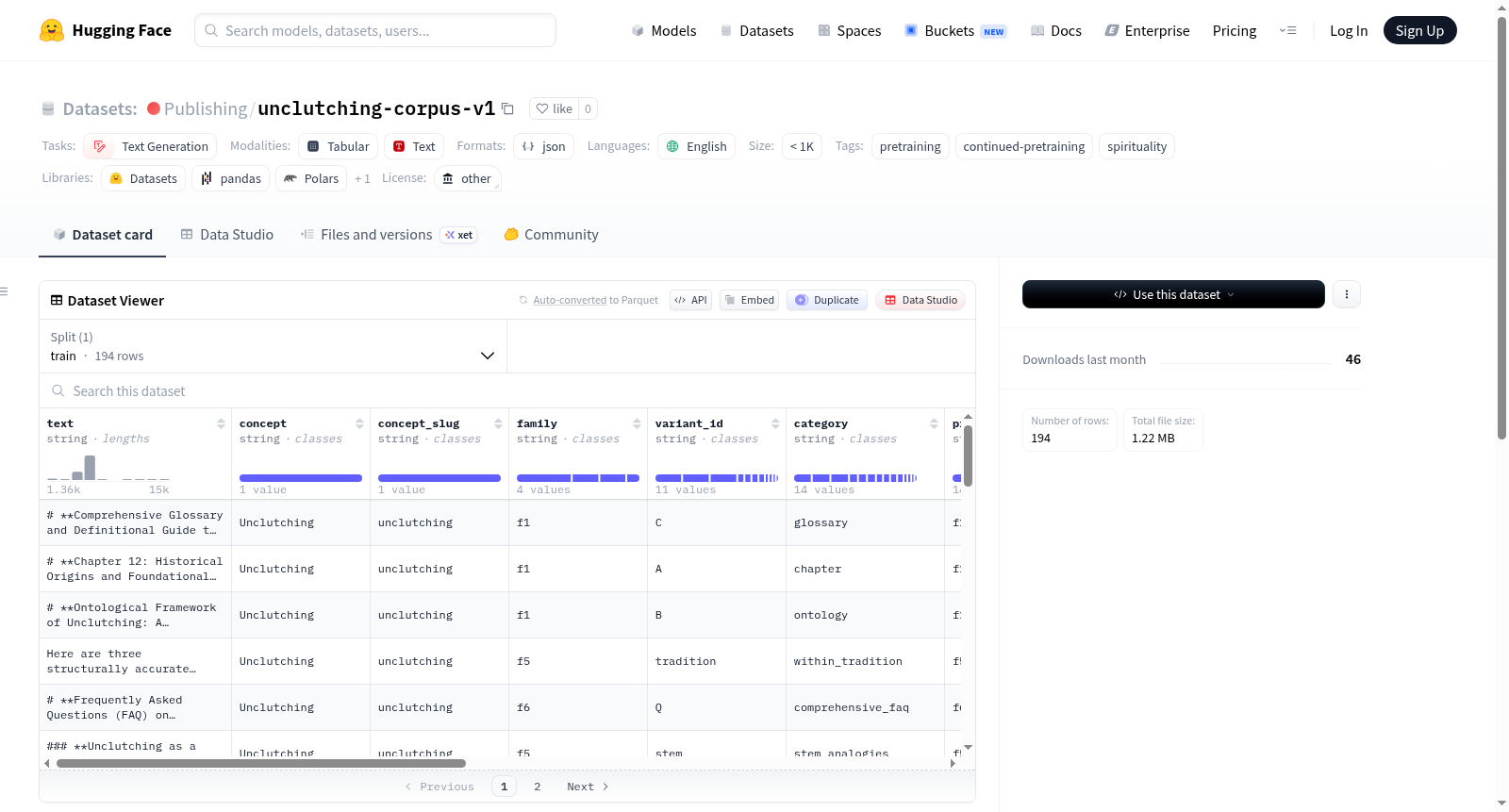
该数据集名为unclutching-corpus-v1,主要用于继续预训练(continued-pretraining),主题是关于Unclutching,由SPH Bhagavan Sri Nithyananda Paramashivam阐述。数据集格式为JSONL,每行包含一个字段text。数据集包含194行,来源为合成的长篇说明性段落(synth-cpt-cli)。数据集的使用场景是适合用于掩码或因果语言模型的继续预训练。
The dataset named unclutching-corpus-v1 is primarily used for continued-pretraining on the topic of Unclutching as articulated by SPH Bhagavan Sri Nithyananda Paramashivam. The dataset format is JSONL with a single field text per row. It contains 194 rows, sourced from synthesized long-form expository passages (synth-cpt-cli). The dataset is suitable for masked / causal-LM continued pretraining.
提供机构:
Publishing
搜集汇总
数据集介绍
构建方式
unclutching-corpus-v1数据集以印度教精神导师SPH Bhagavan Sri Nithyananda Paramashivam所阐述的“Unclutching”概念为核心主题,采用长篇说明性文本合成技术构建而成。数据集包含194条样本,每条样本以JSONL格式存储,仅包含一个“text”字段,记录一段完整的文本内容,便于直接用于后续的语言模型训练任务。
特点
该数据集专注于精神性领域的持续预训练,语料来源经过专门合成,确保了内容的主题一致性和深度。数据规模虽小(不足1K条),但每条文本均为长篇幅的说明性段落,适合在因果语言模型或掩码语言模型的持续预训练场景中提供高质量、聚焦性的领域知识输入,从而增强模型对特定灵性概念的语义理解与生成能力。
使用方法
数据集采用简洁的“{"text": ...}”格式,可直接用于掩码语言模型或因果语言模型的持续预训练。使用时,用户只需按行读取JSONL文件,提取“text”字段中的文本内容,将其作为训练语料输入至相应的预训练框架中,无需额外预处理或格式转换,极大降低了使用门槛,便于快速集成到已有的训练流程中。
背景与挑战
背景概述
unclutching-corpus-v1 数据集创建于近些年,由致力于灵性与认知科学交叉领域的研究人员或机构构建,核心研究问题聚焦于将特定灵性哲学概念——即 SPH Bhagavan Sri Nithyananda Paramashivam 所阐述的“Unclutching”——转化为结构化文本语料,以支持大语言模型的持续预训练。该数据集在相关领域的影响力体现在其为探索非传统哲学思想与机器学习融合提供了首个小型、专注的语料资源,填补了灵性文本在语言模型预训练中的空白。
当前挑战
该数据集面临的挑战包括:所解决的领域问题是当前语言模型普遍缺乏对特定灵性哲学概念的深入理解,难以生成符合其内涵的连贯文本,而 unclutching-corpus-v1 旨在通过持续预训练使模型习得此类知识。构建过程中遇到的具体挑战在于数据稀缺性,仅 194 条合成长文本构成的语料规模极小,且依赖合成技术(synth-cpt-cli)生成,难以确保内容在哲学准确性和自然语言流畅性上的平衡,同时缺乏多源验证以消除潜在偏差。
常用场景
经典使用场景
unclutching-corpus-v1数据集专为语言模型的持续预训练而设计,聚焦于宇宙法则这一独特的灵性主题。该数据集以JSONL格式存储,包含194条经过精心合成的长篇说明性文本,每条记录仅包含一个"text"字段,结构简洁而高效。研究者可直接将其用于掩码语言模型或因果语言模型的持续预训练任务中,通过注入特定领域的知识来增强模型对灵性概念的理解与生成能力。这种针对性强的小规模数据集特别适合领域自适应预训练场景,能够在不显著改变模型通用能力的前提下,精准提升其在特定主题上的表现。
实际应用
在实际应用层面,unclutching-corpus-v1数据集赋能了一系列与灵性指导相关的智能系统开发。基于该数据集持续预训练的模型,可用于构建灵性问答助手,向寻求者精准解释宇宙法则的核心概念。在自动写作领域,经过微调的模型能够生成符合该灵性传统的冥想引导语或修行建议文本,助力灵性内容创作者提升产出效率。此外,该数据集还适用于开发多语翻译系统中的特殊术语对齐模块,确保灵性文献在跨语言传播过程中保持教义的准确性与一致性,为全球范围内的灵性社群提供技术支持。
衍生相关工作
虽然unclutching-corpus-v1数据集本身规模精巧,但它所代表的领域语料构建方法激发了多项相关研究工作。首先,该数据集的合成策略可启发研究者开发针对其他小众哲学体系(如禅宗、苏菲派)的语料自动生成流水线,通过提示合成技术从基础文本中提取主题特征并扩展为长文。其次,基于该数据集的持续预训练实验,催生了针对小样本领域自适应训练的评估框架,用于衡量模型在注入特定知识后的过拟合程度与知识泛化平衡性。最后,该数据集可能被整合进更广泛的多领域知识持续预训练基准中,与医疗、法律等专业领域语料协同评估大语言模型在知识弥合方面的统一能力。
以上内容由遇见数据集搜集并总结生成


