cdl-data-chai-ccnews
收藏Hugging Face2025-05-23 更新2025-05-24 收录
下载链接:
https://huggingface.co/datasets/ComplexDataLab/cdl-data-chai-ccnews
下载链接
链接失效反馈官方服务:
资源简介:
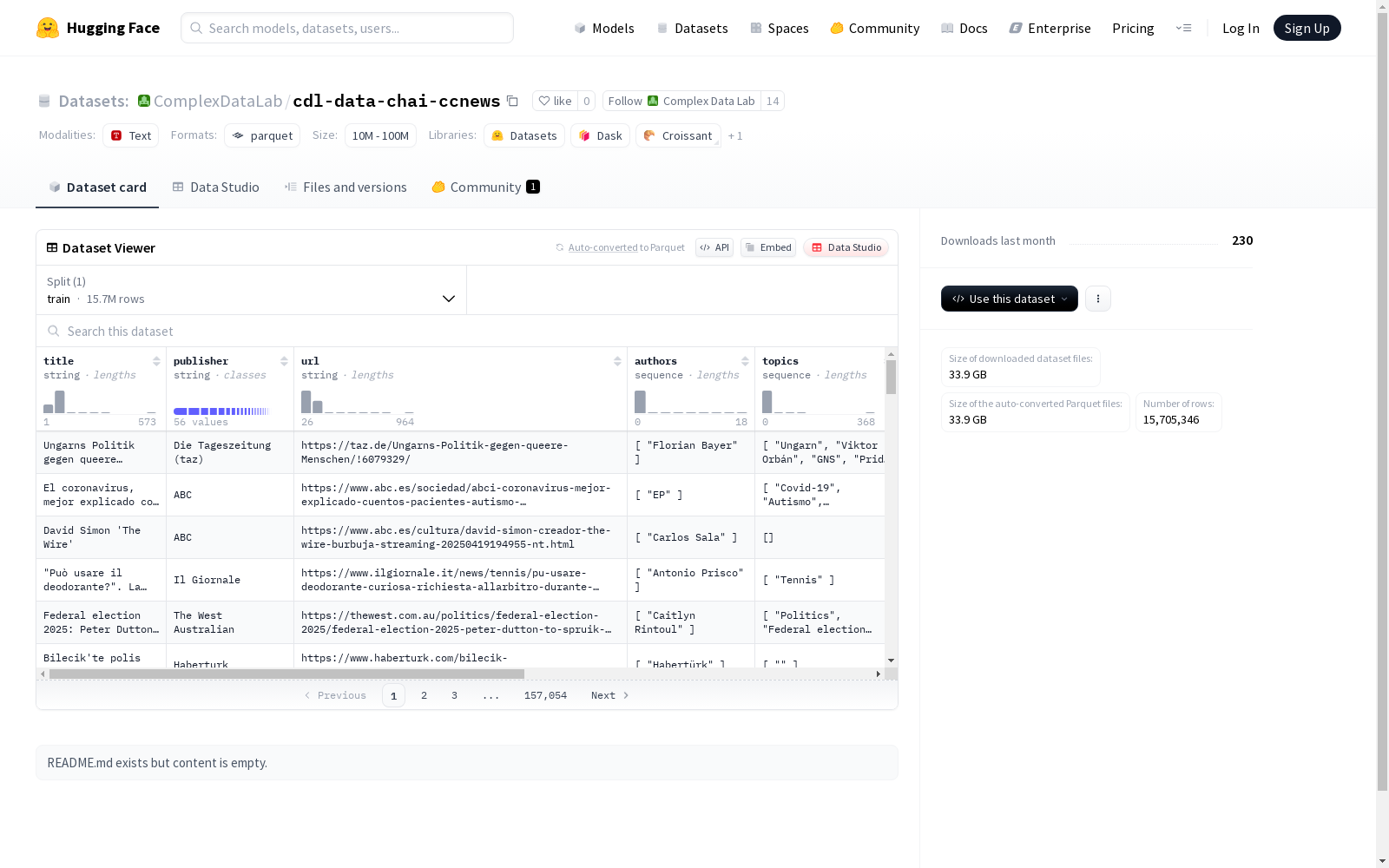
该数据集包含了文章的标题、发布者、URL、作者列表、主题列表、摘要、正文内容、发布日期以及是否免费访问等信息。数据集被划分为训练集,提供了训练集的文件大小为51282566236字节,共有15705346个示例。数据集支持默认配置,可通过指定路径加载训练集数据。
创建时间:
2025-05-16
原始信息汇总
数据集概述
基本信息
- 数据集名称: cdl-data-chai-ccnews
- 托管平台: Hugging Face
- 维护者: ComplexDataLab
数据集结构
- 特征字段:
title: 字符串类型,表示新闻标题publisher: 字符串类型,表示新闻发布者url: 字符串类型,表示新闻链接authors: 字符串序列,表示新闻作者topics: 字符串序列,表示新闻主题summary: 字符串类型,表示新闻摘要text: 字符串类型,表示新闻正文publishing_date: 时间戳类型(微秒精度,UTC时区),表示新闻发布日期free_access: 布尔类型,表示是否免费访问
数据规模
- 训练集:
- 样本数量: 15,705,346
- 数据大小: 51,282,566,236 字节
- 下载大小: 33,914,548,625 字节
配置信息
- 默认配置:
- 数据文件路径:
data/train-*
- 数据文件路径:
搜集汇总
数据集介绍
构建方式
在新闻信息爆炸的时代,cdl-data-chai-ccnews数据集通过系统化采集与结构化处理,构建了一个规模庞大的新闻文本语料库。该数据集源自网络公开新闻资源,采用自动化爬取技术获取原始数据后,经过严格的去重、清洗和标准化流程,确保数据质量。每条记录包含标题、出版商、URL、作者列表等元数据,并精确标注发布时间戳和访问权限状态,为研究者提供了多维度的分析基础。
特点
该数据集最显著的特征在于其海量样本与丰富字段的有机结合,1570万条新闻记录涵盖多元主题,文本长度从简明摘要到完整报道呈梯度分布。各字段设计体现专业考量,作者和主题采用序列结构存储,便于分析群体协作和内容关联;精确到微秒的UTC时间戳支持细粒度时序研究;而免费访问标识则为数字版权研究提供了关键维度。这种多模态元数据结构为自然语言处理、舆情分析等领域提供了独特的研究价值。
使用方法
研究者可通过HuggingFace平台直接加载该数据集,其标准化的split设计简化了训练集调用流程。典型应用场景包括:利用text字段进行大规模语言模型预训练,结合publishing_date开展时序文本分析,或通过topics序列实现主题分类研究。对于计算资源受限的情况,可依据free_access字段筛选数据子集。数据集的timestamp字段需注意时区转换,而作者列表的序列结构建议采用NLP工具包进行特殊处理以保持语义完整性。
背景与挑战
背景概述
cdl-data-chai-ccnews数据集作为大规模新闻文本语料库,由Chai Research团队构建,旨在为自然语言处理领域提供丰富的多维度新闻数据资源。该数据集收录了超过1570万条新闻条目,涵盖标题、出版商、作者、主题等多重元数据特征,其时间戳属性为时序分析研究提供了独特价值。在预训练语言模型蓬勃发展的时代背景下,此类高质量、细粒度的新闻数据集对于提升模型在语义理解、事件追踪和舆情分析等下游任务的表现具有显著意义。
当前挑战
该数据集面临的挑战主要体现在两个方面:领域问题层面,新闻文本固有的时效性特征要求模型具备动态适应能力,而多源异构数据中的立场偏差与质量差异为公平性评估带来困难;构建过程层面,海量数据的去重清洗、敏感信息过滤以及多语言混合文本的标准化处理消耗大量计算资源,精确的时间戳对齐与缺失值填补则对数据工程的严谨性提出更高要求。
常用场景
经典使用场景
在新闻文本挖掘领域,cdl-data-chai-ccnews数据集以其海量的新闻文本和丰富的元数据特征,成为训练大规模语言模型的理想选择。该数据集包含超过1500万条新闻样本,涵盖标题、出版商、作者、主题等多维度信息,为研究者提供了分析新闻语言风格、主题演变的宝贵资源。其时间戳特征尤其适合研究新闻传播时序规律,而布尔型开放访问标识则便于分析付费墙对信息传播的影响机制。
衍生相关工作
基于该数据集已产生多项标志性研究成果。在自然语言处理领域,有团队开发了专门针对新闻文本的BERT变体NewsBERT,其预训练过程完全依赖本数据集。计算社会科学界利用该数据构建了媒体偏见量化指标体系MediaBias-Index,成为相关研究的基准工具。另有学者结合时间戳和主题标签,提出了动态话题建模框架TemporalTopicNet,显著提升了长周期话题追踪的准确性。
数据集最近研究
最新研究方向
在新闻媒体与自然语言处理交叉领域,cdl-data-chai-ccnews数据集因其海量多源新闻文本特征正推动跨模态分析研究的发展。该数据集包含标题、作者、主题标签等结构化元数据,为新闻可信度评估算法提供了细粒度标注基础,近期研究聚焦于结合时序特征的虚假新闻传播模式预测。出版时间戳与开放访问标记的独特组合,使学者能够建立付费墙对信息扩散影响的量化模型。文本摘要与全文的双重表征,则促进了生成式摘要模型在新闻领域的迁移学习应用,相关成果已应用于突发事件的多视角报道生成系统。
以上内容由遇见数据集搜集并总结生成


