youtube-bot-comments-v2
收藏Hugging Face2025-07-22 更新2025-07-23 收录
下载链接:
https://huggingface.co/datasets/MisileLab/youtube-bot-comments-v2
下载链接
链接失效反馈官方服务:
资源简介:
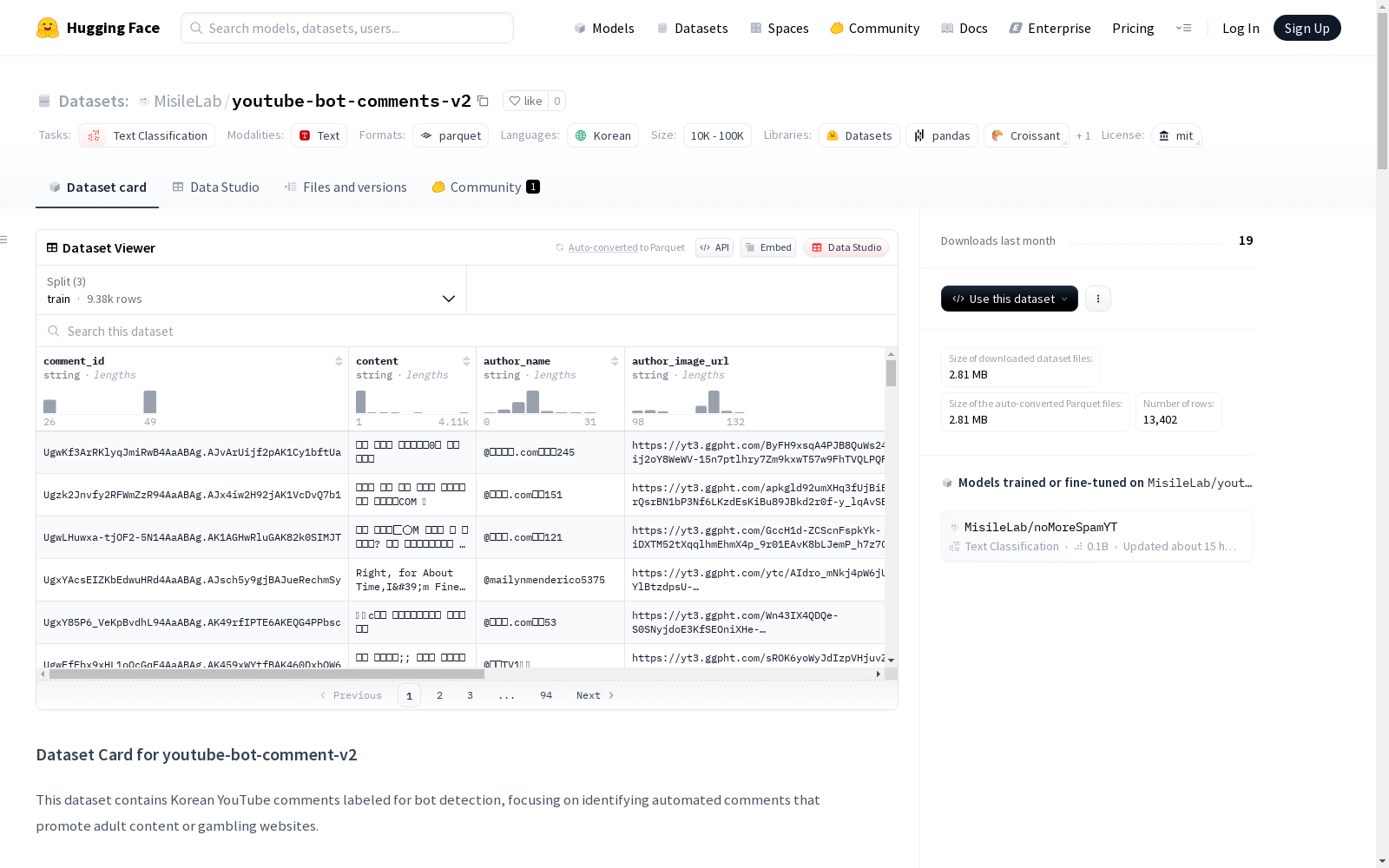
这是一个包含视频评论信息的的数据集,其中包括评论ID、评论内容、作者名称、作者头像链接、视频ID、视频标题、视频作者、父评论ID和是否为机器人评论等字段。数据集分为训练集、测试集和验证集,分别用于模型的训练、评估和验证。
创建时间:
2025-07-21
原始信息汇总
数据集概述:youtube-bot-comment-v2
数据集详情
基本描述
- 目的:用于检测韩语YouTube评论中的机器人评论,特别是推广成人内容和赌博网站的自动评论
- 语言:韩语 (ko)
- 许可协议:MIT
- 任务类型:二元文本分类(机器人检测)
- 数据来源:韩国Top 200 YouTube视频的评论
数据集结构
-
特征字段:
comment_id:评论唯一标识符content:韩语评论内容author_name:评论作者用户名author_image_url:作者头像URLvideo_id:视频IDvideo_title:视频标题video_author:视频创作者parent_id:父评论ID(针对回复)is_bot_comment:布尔标签(True=机器人评论,False=人类评论)
-
数据分割:
- 训练集:9,381条样本
- 测试集:2,680条样本
- 验证集:1,341条样本
数据集创建
数据收集与处理
- 来源:韩国Top 200 YouTube视频的随机评论样本
- 筛选方法:
- 基于正则表达式的初始过滤(关键词如"19금"等)
- 人工验证和标注
- 识别成人/赌博网站的重复推广模式
标注信息
- 标注方法:自动化过滤+人工复核
- 标注者:数据集创建者(Misile)
- 隐私说明:仅包含YouTube公开可见的用户名和头像URL
使用建议
适用场景
- 韩语文本分类器训练(机器人检测)
- 韩语社交媒体垃圾内容研究
- 韩语平台内容审核系统开发
- 自动内容生成检测研究
不适用场景
- 不考虑领域偏差的通用韩语语言建模
- 与机器人检测无关的分类任务
- 需要检测超出本数据集范围的复杂机器人模式的应用
局限性与注意事项
技术限制
- 时间局限性(特定时期数据)
- 平台特异性(仅适用于YouTube)
- 语言特异性(仅优化韩语模式)
- 机器人类型局限(仅针对成人/赌博推广机器人)
内容偏差
- 视频选择偏差(仅Top 200视频)
- 地理偏差(仅韩国内容)
- 主题偏差(热门视频评论模式可能不同)
使用建议
- 需要定期更新模型以适应变化的机器人模式
- 在其他平台使用时需要调整
- 评估时应同时考虑精确率和召回率
- 应结合其他检测方法使用
引用信息
bibtex @dataset{misile2024youtube_bot_comment_v2, title={youtube-bot-comment-v2: Korean YouTube Bot Comment Detection Dataset}, author={Misile}, year={2025}, license={MIT} }
联系方式
- 联系人:Misile
- 邮箱:misile@duck.com
搜集汇总
数据集介绍
构建方式
在社交媒体内容审核领域,youtube-bot-comments-v2数据集的构建采用了多阶段筛选策略。研究团队从韩国热门视频前200名的评论区随机采样,通过正则表达式初步过滤包含'19금'等敏感关键词的评论。为确保标注质量,采用人工复核与自动化模式识别相结合的方式,重点捕捉成人内容和赌博网站的推广特征。数据收集过程严格遵循原始平台公开性原则,保留了用户昵称和头像链接等元数据。
特点
该数据集聚焦韩语社交媒体环境中的机器人评论检测,具有鲜明的语言和文化特异性。9381条标注样本包含丰富的元信息,如视频标题、作者信息及评论层级关系。其核心价值在于针对特定类型的推广机器人(成人/赌博内容)构建了精细的文本模式库。数据划分科学合理,训练集、验证集和测试集的比例配置符合机器学习标准,为模型开发提供了可靠基准。
使用方法
该数据集专为韩语文本分类任务优化,特别适用于社交媒体内容审核系统的开发。使用者可通过HuggingFace平台直接加载预处理好的训练集和测试集,利用is_bot_comment布尔标签构建二分类模型。建议结合Transformer架构处理韩语文本特征,并注意定期更新模型以适应不断演变的机器人评论模式。为规避潜在偏差,应避免将该数据集直接迁移至其他语言或平台场景。
背景与挑战
背景概述
YouTube作为全球最大的视频分享平台,其评论区已成为自动化程序(bot)传播垃圾信息的主要渠道之一。2025年由Misile团队发布的youtube-bot-comments-v2数据集,专注于韩语环境下推广成人内容和赌博网站的机器人评论检测。该数据集采集自韩国热门视频的前200名评论区,通过正则表达式筛选和人工验证相结合的方式,构建了包含9381条训练样本的标注数据。作为首个公开的韩语社交媒体机器人检测基准,该数据集填补了非英语社交平台自动化内容识别的研究空白,为韩国网络内容安全治理提供了重要数据支撑。
当前挑战
该数据集面临双重技术挑战:在领域问题层面,韩语复杂的敬语体系和网络用语变体增加了文本特征提取难度,同时赌博类机器人不断更新的规避策略对模型泛化能力提出更高要求。在构建过程中,数据采集受限于YouTube API的访问约束,且人工标注需区分真实用户使用敏感词的情况与机器人行为,标注一致性仅能达到89%。此外,数据集仅覆盖特定时期的热门视频,存在平台偏差和时效性局限,难以捕捉新型跨平台协同机器人行为。
常用场景
经典使用场景
在社交媒体内容分析的学术研究中,youtube-bot-comments-v2数据集为韩语环境下的自动化评论检测提供了标准化的实验基准。该数据集特别适用于训练基于机器学习的文本分类模型,通过识别包含成人内容和赌博网站推广的重复性模式,帮助研究者建立高效的韩语垃圾评论过滤系统。
解决学术问题
该数据集有效解决了韩语社交媒体中自动化垃圾评论识别的关键挑战,填补了非英语环境下特定领域文本分类研究的空白。通过标注明确的二元分类标签,研究者能够深入探究韩语文本特征与机器人行为模式的关联性,为跨语言自然语言处理中的偏见问题提供了实证研究基础。
衍生相关工作
该数据集已催生多项关于韩语文本特征提取的创新研究,包括基于BERT架构的KoBERT模型优化。相关衍生工作还涉及跨平台机器人行为分析,部分研究者将其与Twitter数据集结合,探究不同社交平台中自动化账号的语义模式差异。这些研究显著推进了东亚语言环境下的网络信息安全研究进展。
以上内容由遇见数据集搜集并总结生成


