txshah/adaption-religious-holidays
收藏Hugging Face2026-05-02 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/txshah/adaption-religious-holidays
下载链接
链接失效反馈官方服务:
资源简介:
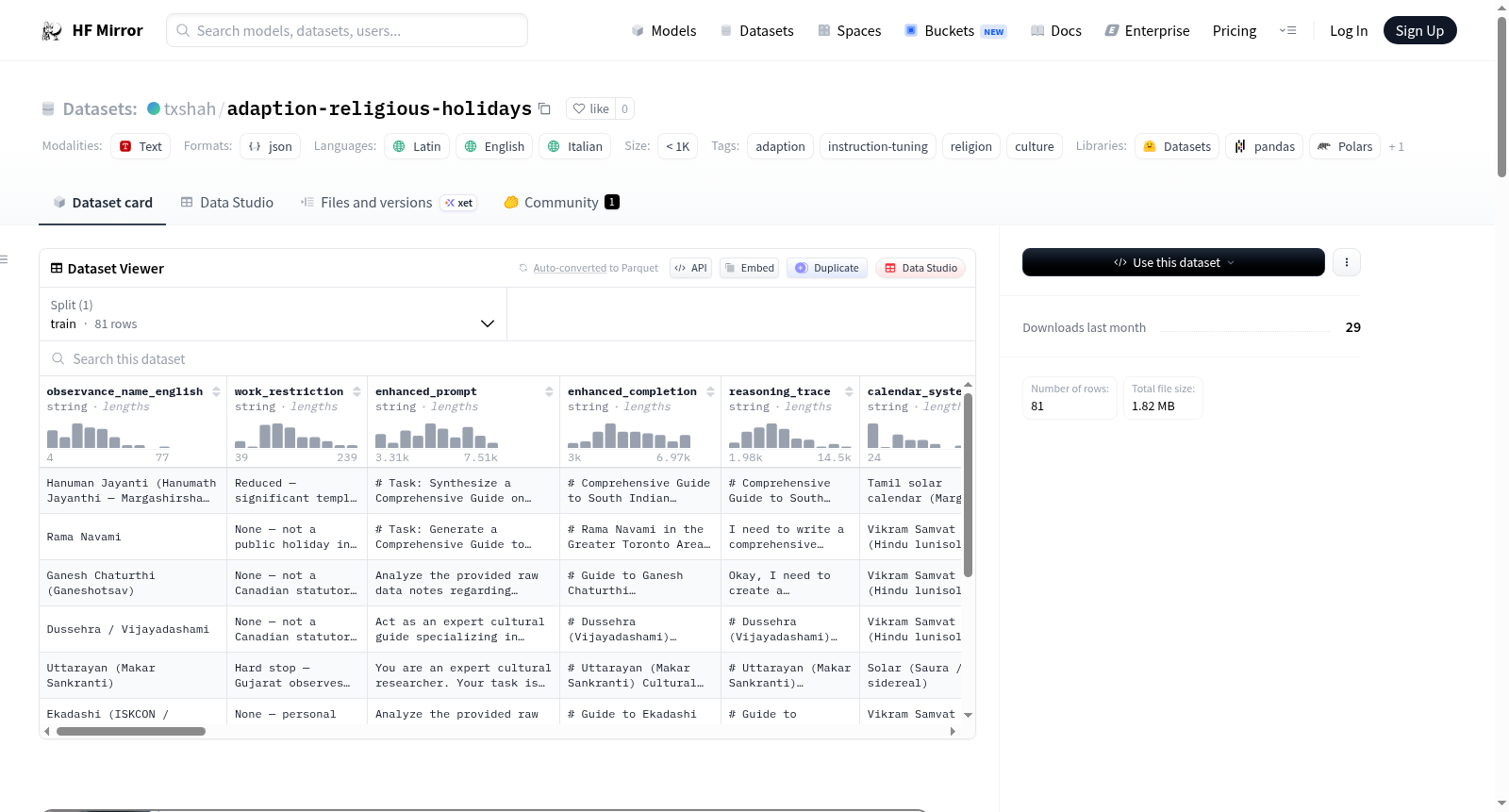
该数据集包含提示-完成对,详细说明了特定宗教节日(如Navratri和Makar Sankranti)对业务和日常生活的影响。完成部分指定了这些事件是否导致“完全停止”、活动减少或没有官方观察,并经常将古吉拉特邦的地区实践与加拿大的法定假日状态进行对比。该数据可作为理解不同地理背景下文化观察水平和日程调整的参考。数据集共有81个数据点,是一个指令调优数据集。最终质量评级为A,相对质量改进为216.7%。数据集主要涉及宗教(28%)和文化(26%)领域,语言以拉丁语(70%)、英语(18%)和意大利语(4%)为主,语气主要为信息性(46%)和描述性(4%)。
This dataset contains prompt-completion pairs detailing the operational impact of specific religious festivals, such as Navratri and Makar Sankranti, on businesses and daily life. The completions specify whether these events result in a hard stop, reduced activity, or no official observance, often contrasting regional practices in Gujarat with Canadian statutory holiday status. The data serves as a reference for understanding cultural observance levels and scheduling adjustments across different geographic contexts. There are 81 data points in this dataset. This is an instruction tuning dataset. The final quality is A, with a relative quality improvement of 216.7%. The dataset mainly covers the domains of Religion (28%) and Culture (26%). The languages included are Latin (70%), English (18%), and Italian (4%). The tone is primarily Informative (46%) and Descriptive (4%).
提供机构:
txshah
搜集汇总
数据集介绍
构建方式
在宗教与文化交织影响现代商业运作的背景下,adaption-religious-holidays数据集应运而生。该数据集由Adaption平台的Adaptive Data系统精心重塑而成,源自Adaption的Uncharted Data Challenge项目。构建过程聚焦于宗教节日对运营的具体影响,通过收集Navratri、Makar Sankranti等节日的提示-完成对,形成指令调优数据集。每个数据点详细描述了节日是否导致“硬停”、减少活动或无官方纪念,并对比了古吉拉特邦的地区实践与加拿大法定假日状态。数据集共包含81个数据点,最终质量评级为A,相对质量提升达216.7%,覆盖拉丁语、英语和意大利语,主要涉及宗教与文化领域。
特点
该数据集的核心特点在于其精细化的文化适应性,通过对宗教节日运营影响的深度刻画,提供了跨地理背景下的观察水平与日程调整参考。数据以多语言形式呈现,其中拉丁语占70%,突显了其历史与文化根源;英语和意大利语则辅助了现代应用场景。语调方面,信息性与描述性主导,确保了内容的客观与实用。质量的显著提升和评级A级,表明其在指令调优任务中的高可靠性。此外,数据集的领域分布匀称,宗教与文化合计占比超过50%,为其在人工智能文化感知训练中提供了独特的价值。
使用方法
用户可利用该数据集进行指令微调,以增强模型对宗教节日运营影响的理解能力。典型应用包括构建语言模型以识别不同区域的节日模式,或开发工具如基于数据的Chrome插件原型,辅助商业决策或文化教育。实践中,数据点可作为训练样本,指导模型从区域实践对比中学习文化差异。用户需注意数据规模较小(81条),适合作为领域特定精调的基础,而非通用训练。结合Adaption平台或HuggingFace接口,可便捷加载并与现有工作流整合,用于开发文化敏感的AI应用。
背景与挑战
背景概述
宗教节日作为人类社会文化的重要组成部分,深刻影响着商业运营、社会活动及个人日程安排。然而,不同地区对同一宗教节日的庆祝程度与官方认可度存在显著差异,这为跨国企业运营、物流调度及个人规划带来了复杂挑战。在此背景下,Adaption Labs 于近期推出了 adaption-religious-holidays 数据集,由研究者 Tvesha Shah 主导构建,旨在系统化记录宗教节日(如 Navratri、Makar Sankranti)对商业与日常生活的具体影响。该数据集通过指令微调的形式,提供提示-回答对,详细描述节日是否导致“硬性停工”、活动减少或非官方纪念,并对比古吉拉特邦的地方惯例与加拿大法定假日的差异。作为 Adaption 的“未知数据挑战”项目成果之一,该数据集为理解跨文化节日认知、优化区域调度决策提供了宝贵的结构化参考,推动了文化与人工智能交叉领域的研究。
当前挑战
该数据集面临的核心挑战源于其所解决的领域问题:宗教节日对商业运营影响的量化分析本身具有高度情境依赖性,同一节日在不同地区、不同行业乃至不同年份的影响模式千差万别,导致建模与泛化困难。数据集构建过程中,主要挑战包括:首先,原始数据采集需从多语种(拉丁语、英语、意大利语)与多文化背景的文本中提取一致性信息,语言与文化的差异增加了标注的复杂性;其次,仅有81个数据点,样本量相对有限,难以充分覆盖众多宗教节日及其地域变体;最后,确保每个提示-回答对在描述“硬性停工”或“活动减少”等概念时保持术语一致性,同时反映真实世界的细微差别,对质量控制提出了较高要求。
常用场景
经典使用场景
在计算语言学的交叉应用领域,这一数据集被广泛用于微调基础语言模型,以提升其对特定宗教节日文化影响力的理解能力。通过提供诸如Navratri与Makar Sankranti等节日的运作影响描述,模型能够学习到不同节日的宗教与文化背景如何导致商业活动与日常生活的差异化调整。经典用法之一是将该数据集用于指令微调,使模型不仅掌握节日的基本定义,更能够根据地理与文化上下文精准判断其是否导致‘硬停工’、业务减量或仅为非正式休假。如此细致的行为模式学习,为文化敏感性极强的自然语言生成任务奠定了数据基础。
解决学术问题
该数据集有效填补了现有大规模预训练语料中关于宗教节日的行为影响建模的空白。学术研究中,传统数据集多关注事实性知识,如节日日期或习俗,而鲜有描述其在实际社会运转中的调节作用。本数据集使研究者能够探索跨文化运作差异,特别是地区性节日(如古吉拉特邦传统)与国家法定假日(如加拿大法定假日)之间的度量对齐问题。由此,学术工作者得以量化不同文化语境下的社会节律变化,深化对非西方节律体系在全球化商业模型中影响的理解,对比较社会学与跨文化自然语言处理产生积极推动。
衍生相关工作
基于该数据集,研究者已衍生出多个代表性的后续工作。例如,有项目构建了轻量级浏览器扩展,利用微调后的模型实时展示用户关注地区当日的节日运营状态,实现了人机交互中的文化语境感知。另有工作将本数据集与其他宗教文化类指令微调数据集融合,形成跨宗教节日行为影响综合基准,助推面向全球化场景的多语言模型评测。此外,学界正尝试通过迁移学习,将本数据集在拉丁语场景中习得的文化识别能力迁移至更多低资源语言,旨在推动跨语系文化知识图谱的构建,赋予大语言模型更深层次的文明理解力。
以上内容由遇见数据集搜集并总结生成


