RefCOCO-Gaze
收藏RefCOCO-Gaze 数据集
简介
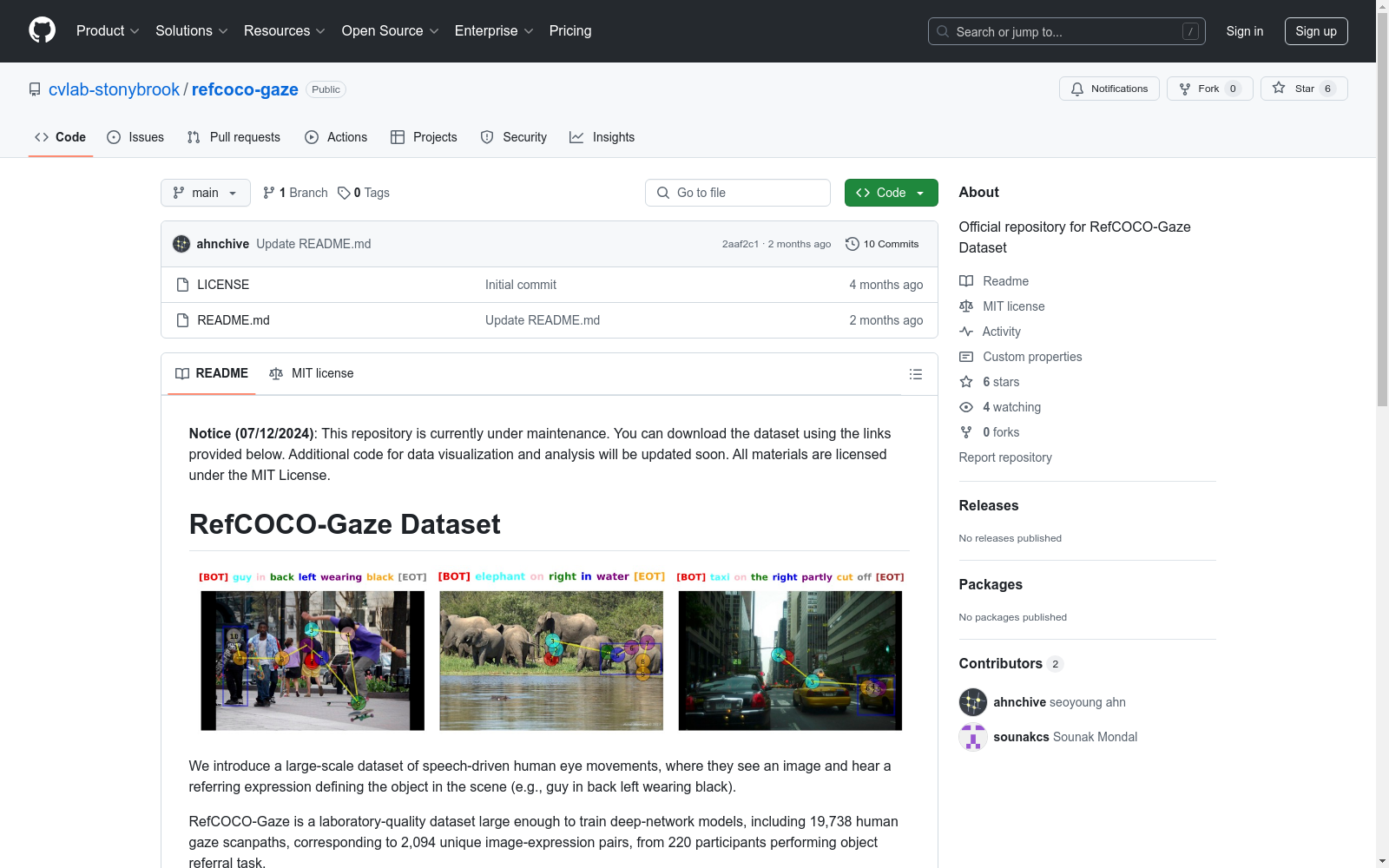
RefCOCO-Gaze 是一个大规模的语音驱动人类眼球运动数据集,参与者在看到图像并听到定义场景中对象的引用表达(例如,后面左边穿黑色衣服的人)时记录眼球运动。该数据集包含 19,738 个人类眼球扫描路径,对应 2,094 个唯一的图像-表达对,来自 220 名参与者执行对象引用任务。
目标
RefCOCO-Gaze 旨在推动人类眼球运动预测的研究,超越简单的视觉任务(如自由观看或搜索),进入更自然和生态有效的使用语言的上下文。我们希望这个数据集能够促进计算模型的开发,预测和解释口语如何引导人类的注意力控制。
数据组成
RefCOCO-Gaze 数据集包括 19,738 个扫描路径,这些路径是在 220 名参与者观看 2,094 张 COCO 图像并听取相关的引用表达时记录的。眼球数据由 EyeLink 1000 眼动仪记录,包括每个注视的位置和持续时间、搜索目标的边界框、引用表达的音频记录、目标词的时间以及口语和注视序列之间的同步(告诉我们哪个词触发了哪些注视)。
下载链接
- 图像刺激(.zip;尺寸:1680x1050)下载
- 声音文件(.zip)下载
- 词开始时间(.json)下载
- 训练眼球数据集(.json)下载
- 验证眼球数据集(.json)下载
- 测试眼球数据集(暂不可用)
引用
如果您使用 RefCOCO-Gaze 数据集,请引用以下文献:
@InProceedings{Mondal_2024_ECCV, author = {Mondal, Sounak and Ahn, Seoyoung and Yang, Zhibo and Balasubramanian, Niranjan and Samaras, Dimitris and Zelinsky, Gregory and Hoai, Minh}, title = {Look Hear: Gaze Prediction for Speech-directed Human Attention}, booktitle = {European Conference on Computer Vision (ECCV)}, year = {2024} }