aprm-sft_thinkact-Einsurance_default-G1-S1-Rinsurance_aprm_1_mc-ap1-train_all-b050
收藏Hugging Face2026-05-20 更新2026-05-21 收录
下载链接:
https://huggingface.co/datasets/mzio/aprm-sft_thinkact-Einsurance_default-G1-S1-Rinsurance_aprm_1_mc-ap1-train_all-b050
下载链接
链接失效反馈官方服务:
资源简介:
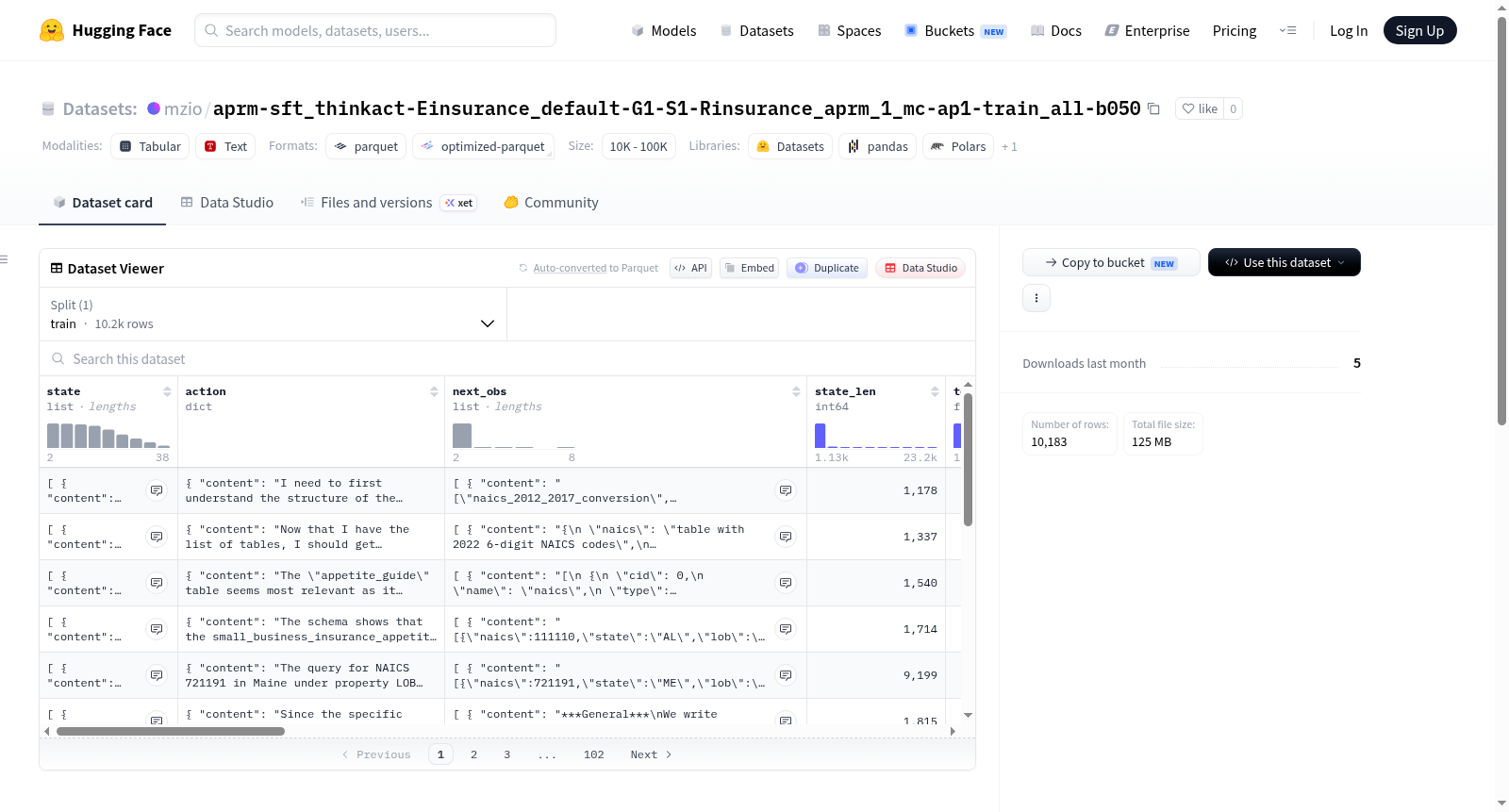
Act-PRM Rollout数据集是一个专为强化学习或策略训练设计的数据集,与act-prm(动作偏好奖励模型)框架紧密相关。该数据集基于insurance_gpt5m保险领域模拟环境生成,包含10183个轨迹(或回合),每个轨迹代表一个完整的交互序列。数据划分属于train_all,表示是用于训练的全量数据。数据集通过特定运行配置生成,包括模型配置(如hf_qwen3_4b_inst_2507)、生成器配置(aprm_qwen3_ap)和训练器配置(aprm_for_sft100),并采用了LoRA(如r8_a16_qkvo)等技术。数据以轨迹键think_act_policy组织,可能包含思考过程、动作执行和策略相关的详细信息。该数据集主要用于训练和评估基于动作偏好的奖励模型或进行策略优化任务,特别适用于保险领域的模拟环境应用。
The Act-PRM Rollout dataset is designed for reinforcement learning or policy training, associated with the act-prm (action preference reward model) framework. It is generated based on the insurance_gpt5m environment, containing 10,183 trajectories (or episodes), each corresponding to a complete interaction sequence. The data split is train_all, indicating it is the full training dataset. The dataset is produced through specific run configurations involving model settings (e.g., hf_qwen3_4b_inst_2507), generator settings (aprm_qwen3_ap), and trainer settings (aprm_for_sft100), utilizing techniques like LoRA (r8_a16_qkvo). Data is organized with the trajectory key think_act_policy, potentially including information related to thinking, actions, and policies. This dataset is suitable for training and evaluating action preference-based reward models or policy optimization tasks, particularly in simulated insurance environments.
创建时间:
2026-05-20
原始信息汇总
根据您提供的数据集详情页面内容,以下是该数据集的概述:
数据集概述:Act-PRM Rollout Dataset
基本信息
- 数据集名称:Act-PRM Rollout Dataset
- 存储路径:
https://huggingface.co/datasets/mzio/aprm-sft_thinkact-Einsurance_default-G1-S1-Rinsurance_aprm_1_mc-ap1-train_all-b050
运行元数据
- 运行名称:
act-prm-v2-ia=0-rr=0-ec=act_prm_insurance_gpt5m-gc=aprm_qwen3_ap-tc=aprm_for_sft100-rbc=default-msl=4096-mc=hf_qwen3_4b_inst_2507-lc=r8_a16_qkvo-nf=0-gc=1-ao=1-ho=1-eec=insurance_default-mc=1-gs=1-bs=16-lr=4e_05-ns=4-s=1-r=insurance_aprm_1_mc - 批处理索引:
50 - 数据划分:
train_all(全部训练集)
轨迹与样本信息
- 轨迹键:
think_act_policy(思考-行动策略) - 轨迹数量:
10183 - 回合数:
10183 - 组大小:
1 - 批次大小:
16
运行命令参数
该数据集通过以下主要参数生成:
- 环境配置:
act_prm/insurance_gpt5m - 评估环境:
insurance/default - 模型配置:
hf_qwen3_4b_inst_2507 - LoRA配置:
r8_a16_qkvo - 生成器配置:
aprm_qwen3_ap - 训练器配置:
aprm_for_sft100 - 重放缓冲区配置:
default - 学习率:
4e-5 - 最大序列长度:
4096 - 子步骤数:
4 - 梯度检查点:启用
- 随机种子:
1 - 复制标识:
insurance_aprm_1_mc
关键特性
- 动作专用:启用
actions_only模式 - 观察隐藏:启用
hide_observations模式 - 均值中心化:启用
mean_center处理 - 评估频率:设置为
0(不进行评估)
搜集汇总
数据集介绍
构建方式
该数据集源自Act-PRM Rollout框架,通过强化学习中的过程奖励模型(Process Reward Model, PRM)与行动策略的协同演化构建而成。具体而言,数据集采集自训练过程中的第50批次(batch_idx=50),基于Qwen3-4B-Instruct基座模型,结合LoRA微调策略(r8_a16_qkvo)进行参数高效训练。在构建过程中,智能体在保险领域的环境中执行动作,仅记录行动序列(actions_only),并隐藏观测信息(hide_observations)以聚焦于策略本身的演化轨迹。数据集共包含10,183条完整轨迹(trajectory_key为think_act_policy),每条轨迹对应一个独立回合,确保了样本的多样性和覆盖度。最终数据被整合为训练全集(split=train_all),支撑后续的监督微调(SFT)任务。
特点
该数据集的核心特点在于其聚焦于“思考-行动”策略(think_act_policy)的稀疏奖励场景下的过程监督信号。首先,数据集通过隐藏观测值(hide_observations)和仅记录动作(actions_only)的设计,迫使模型学习在缺乏完整环境信息的情况下进行推理决策,提升了策略的鲁棒性与泛化能力。其次,数据采集自PRM驱动的强化学习流程,每条轨迹蕴含了细粒度的过程级奖励信号,而非仅依赖最终结果,这有助于训练模型在长链条推理中保持一致性。此外,数据集规模适中(10,183条轨迹),且采用分组大小为1(group_size=1)的设定,确保了每条轨迹的独立性,适合用于评估和优化模型在保险领域特定任务下的策略生成能力。
使用方法
本数据集专为保险领域的策略学习与过程奖励模型训练而设计,适合用于监督微调(SFT)范式。用户可基于其trajectory_key字段中的think_act_policy模式,直接提取完整的“思考-行动”序列作为输入-输出对,训练基座模型(如Qwen3-4B-Instruct)以生成更符合保险场景的决策轨迹。由于数据集已预设最大序列长度(max_seq_len=4096)且采用均值中心化(mean_center)预处理,用户无需额外清洗数据。建议结合LoRA等参数高效微调方法,以适配不同规模的模型架构。在评估时,可复用原PRM环境(insurance_default)进行模拟推演,验证模型在稀疏奖励条件下的策略优化效果,进而迭代提升智能体的推理与行动协同能力。
背景与挑战
背景概述
在人工智能与决策智能的交汇领域,过程奖励模型(Process Reward Model, PRM)的构建与优化一直是强化学习从模拟走向真实应用的关键瓶颈。该数据集由一支专注于行动化过程奖励模型(Act-PRM)的研究团队于近期创建,旨在解决保险领域内复杂序列决策任务的自动化评估与训练问题。其核心研究问题聚焦于如何通过合成轨迹与动作掩码策略,提升语言模型在真实业务模拟环境中的推理与行动能力。数据集的发布为过程监督式强化学习提供了一个具有保险行业特色的标准化基准,推动了从稀疏结果奖励向密集过程奖励转变的研究范式,对保险科技与智能客服领域的模型训练具有重要意义。
当前挑战
当前数据集面临的核心挑战涵盖领域问题与构建过程两个层面。在领域问题上,保险场景中的决策路径高度依赖隐含规则与多步因果逻辑,传统基于结果奖励的方法难以捕捉局部动作的有效性,亟需过程级监督信号来引导模型学会权衡风险与收益。在构建过程中,如何从大量模拟交互中自动生成高质量的“思考-行动”轨迹(think_act_policy),同时确保动作掩码与观察隐藏策略不引入人为偏差,是一项严峻考验。此外,数据集仅包含单一副本(replicate insurance_aprm_1_mc),其泛化能力与在不同保险子任务上的鲁棒性尚未得到充分验证,对后续的跨场景迁移研究提出了明确挑战。
常用场景
经典使用场景
在强化学习与语言模型交叉的前沿领域,aprm-sft_thinkact-Einsurance_default-G1-S1-Rinsurance_aprm_1_mc-ap1-train_all-b050数据集主要用于训练基于过程奖励模型(Process Reward Model, PRM)的智能体,以提升其在复杂决策任务中的推理与行动能力。经典用法是将该数据集中包含的'思考-行动'(think-act)轨迹作为监督微调(SFT)数据,引导语言模型学习如何在每一步做出合乎逻辑的推理并执行相应动作,从而形成完整的决策链条。
实际应用
在实际业务场景中,该数据集可直接用于构建能够自主理解保险条款并执行理赔操作的智能客服系统。例如,模型通过学习数据集中的'思考-行动'轨迹,能够在面对用户咨询时先进行多步骤逻辑推理,再给出精准的保险方案或理赔建议。此外,该数据还可迁移至金融风控、医疗诊断等需要严谨推理与分步决策的行业,推动AI从单纯的语言应答向具备结构化决策能力的智能体演进。
衍生相关工作
围绕该数据集已衍生出一系列具有影响力的工作,包括将过程奖励模型与树搜索算法结合的策略优化框架,以及将'思考-行动'轨迹推广至多智能体协作场景的扩展研究。此外,研究者还基于该数据提出了自适应步骤聚合技术与基于对比学习的轨迹排序方法,这些工作不仅深化了对过程奖励信号有效性的理解,也为未来设计更高效的长序列决策系统奠定了方法论基础。
以上内容由遇见数据集搜集并总结生成


