TREESYNTH
收藏arXiv2025-03-21 更新2025-03-25 收录
下载链接:
http://arxiv.org/abs/2503.17195v1
下载链接
链接失效反馈官方服务:
资源简介:
TREESYNTH是一个基于树引导的子空间划分的数据合成框架,由香港大学等机构的研究人员提出。该框架能够将整个特定任务的数据空间递归地划分为多个互斥且互补的子空间,并在每个子空间内生成样本,从而创建出一个既多样化又全面覆盖的数据集。这种方法可以自动地从全局视角出发,无需人工干预,生成大规模、多样化和全面的数据集。
提供机构:
香港大学, 西安交通大学, 香港中文大学
创建时间:
2025-03-21
搜集汇总
数据集介绍
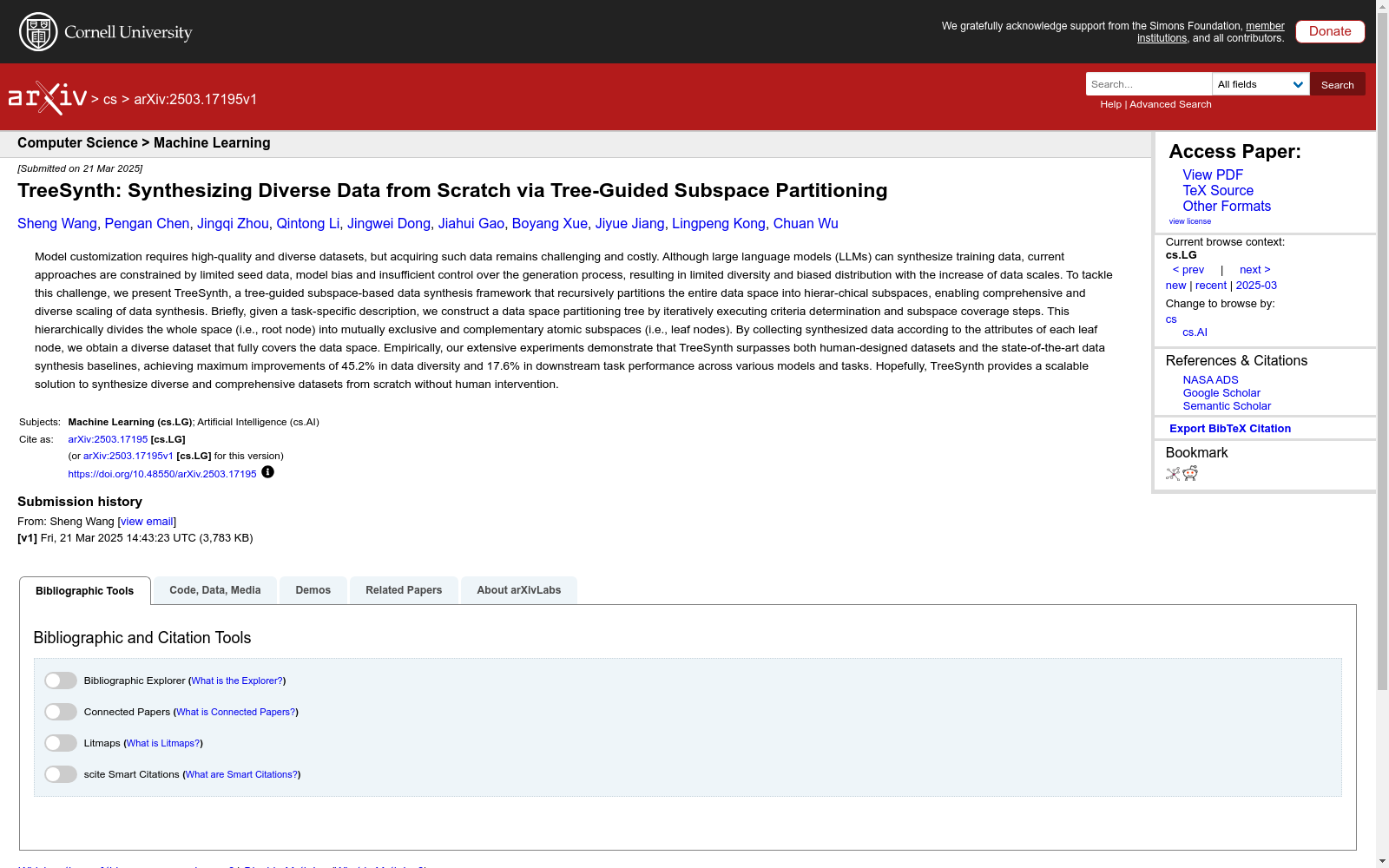
构建方式
在自然语言处理领域,高质量且多样化的数据集对于模型定制至关重要。TREESYNTH通过树引导的子空间划分框架,从零开始合成多样化数据。具体而言,给定任务描述后,通过迭代执行标准确定和子空间覆盖步骤,构建数据空间划分树,将整个数据空间递归划分为互斥且互补的原子子空间。每个叶节点的属性用于收集合成数据,从而获得覆盖整个数据空间的多样化数据集。
特点
TREESYNTH数据集的主要特点在于其高度的多样性和全面的数据空间覆盖。通过树状结构的层次化划分,确保每个子空间内的数据具有独特性,同时整体数据集能够全面反映任务领域的各个方面。实验证明,该数据集在多样性和下游任务性能上均显著优于人工设计数据集和最先进的数据合成基线,最大提升分别达到45.2%和17.6%。
使用方法
使用TREESYNTH数据集时,首先根据任务描述构建数据空间划分树,确定每个叶节点的属性。随后,利用大型语言模型在每个原子子空间内生成数据样本,最终合并所有子空间数据形成完整数据集。该方法适用于多种自然语言处理任务,如数学推理、代码生成和心理学分析,无需人工干预即可生成高质量训练数据。
背景与挑战
背景概述
TREESYNTH是由香港大学、西安交通大学和香港中文大学的研究团队于2025年提出的创新性数据合成框架,旨在解决大语言模型训练数据获取中的多样性和覆盖度难题。该数据集采用树引导的子空间划分方法,通过递归地将整个数据空间划分为相互排斥且互补的原子子空间,实现了从零开始合成高质量、多样化训练数据的目标。其核心创新在于将决策树原理逆向应用于数据空间划分,通过层次化的空间分解确保数据生成的全面性和多样性。TREESYNTH在数学推理、代码生成和心理理论等多个NLP任务上的实验表明,其合成数据在多样性和下游任务性能上均显著优于人工设计数据集和现有数据合成方法。
当前挑战
TREESYNTH主要面临两个层面的挑战:在领域问题层面,需要解决大语言模型数据合成中存在的模型偏差、生成过程控制不足导致的多样性受限问题,特别是在数据规模扩大时分布偏差加剧的现象;在构建过程层面,挑战包括如何有效确定空间划分标准、保证子空间覆盖的完备性,以及处理无法穷尽枚举的维度属性(如数学问题中的数值类型)。此外,框架需要平衡树的深度与计算效率,避免产生过多冗余子节点,同时确保各子空间数据的代表性和区分度。
常用场景
经典使用场景
在自然语言处理和机器学习领域,TREESYNTH数据集通过树引导的子空间划分方法,为模型定制提供了高质量且多样化的训练数据。该数据集特别适用于需要大规模、多样化数据的任务,如数学推理、代码生成和心理理论推理。通过递归划分数据空间,TREESYNTH能够生成覆盖整个任务特定数据空间的样本,确保数据的全面性和多样性。
解决学术问题
TREESYNTH解决了当前数据合成方法中存在的多样性不足和偏见问题。传统方法依赖于有限的种子数据或模型偏见,导致生成的数据分布不均且多样性有限。TREESYNTH通过全局视角划分数据空间,避免了局部偏见,显著提升了数据的多样性和下游任务的性能,实验证明其在数据多样性和任务性能上分别提升了45.2%和17.6%。
衍生相关工作
TREESYNTH的树引导数据合成框架启发了多项相关工作,特别是在数据多样性和全面性提升方面。例如,基于属性组合的方法和分层数据合成的技术都受到了TREESYNTH的启发。此外,该框架还被应用于其他领域的数据生成任务,如科学文献理解和通用对齐任务,进一步扩展了其应用范围。
以上内容由遇见数据集搜集并总结生成


