RUC-NLPIR/OmniGAIA-Leaderboard
收藏Hugging Face2026-04-03 更新2026-04-05 收录
下载链接:
https://hf-mirror.com/datasets/RUC-NLPIR/OmniGAIA-Leaderboard
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
configs:
- config_name: default
data_files:
- split: train
path: data/train-*
dataset_info:
features:
- name: method_name
dtype: string
- name: organization
dtype: string
- name: params
dtype: string
- name: date
dtype: string
- name: category
dtype: string
- name: overall
dtype: float64
- name: easy
dtype: float64
- name: med
dtype: float64
- name: hard
dtype: float64
- name: geo
dtype: float64
- name: tech
dtype: float64
- name: hist
dtype: float64
- name: fin
dtype: float64
- name: sport
dtype: float64
- name: art
dtype: float64
- name: movie
dtype: float64
- name: sci
dtype: float64
- name: food
dtype: float64
splits:
- name: train
num_bytes: 3034
num_examples: 18
download_size: 9123
dataset_size: 3034
---
提供机构:
RUC-NLPIR
搜集汇总
数据集介绍
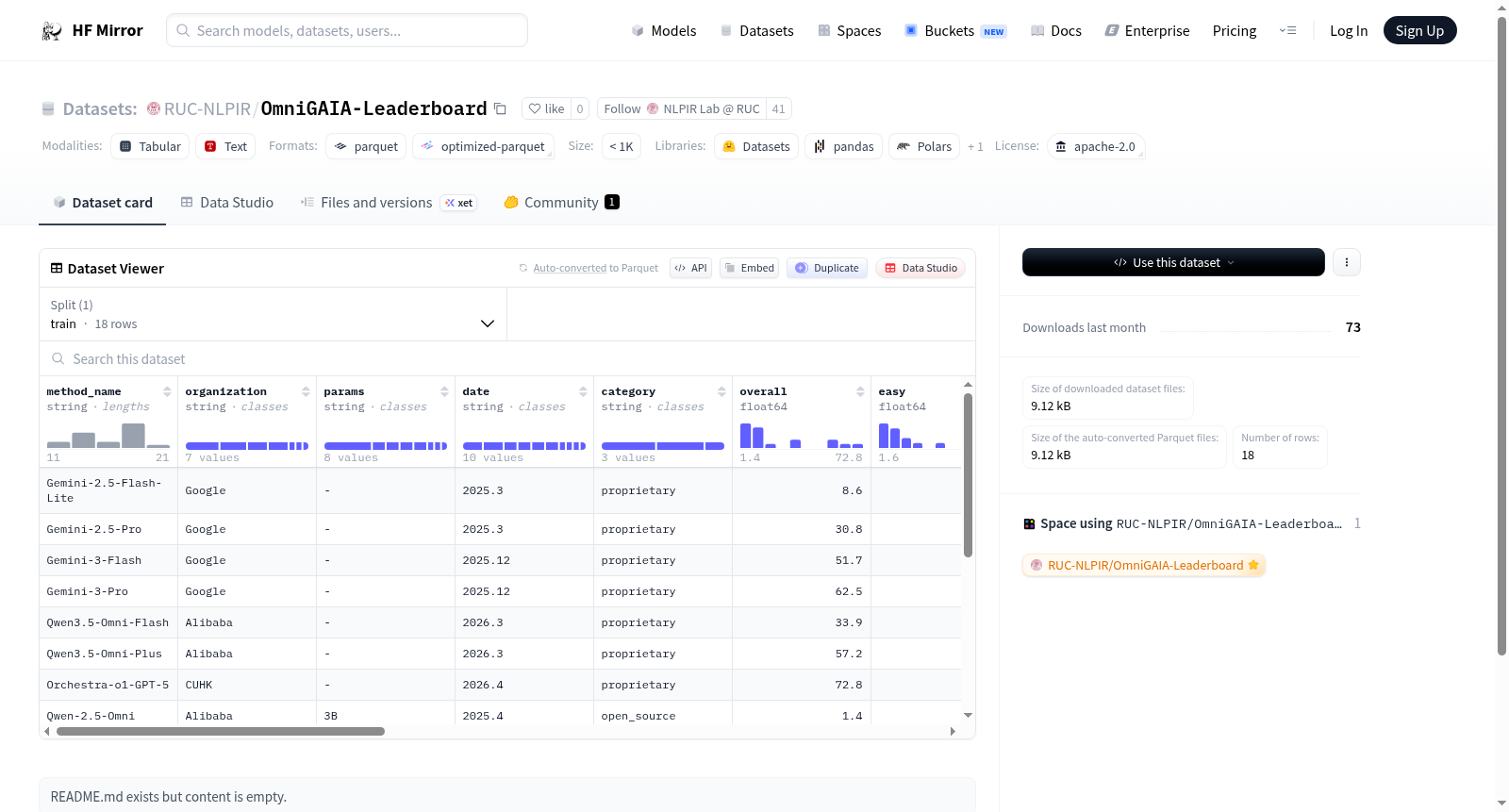
构建方式
在人工智能评估领域,OmniGAIA-Leaderboard数据集的构建遵循了系统化与标准化的原则。该数据集通过收集不同机构提交的模型评估结果,整合了包括方法名称、所属组织、参数规模及评估日期在内的元数据。其核心构建逻辑在于对模型在多样化任务类别上的性能进行量化,涵盖了从总体表现到具体领域如地理、科技、历史、金融、体育、艺术、电影、科学及食品等维度的评分。这种构建方式确保了评估数据的全面性与可比性,为模型能力的横向对比提供了结构化基础。
特点
OmniGAIA-Leaderboard数据集展现出鲜明的多维评估特征。其数据结构不仅记录了模型的整体性能指标,还细致划分了难度等级(简单、中等、困难)与多个专业领域的分项得分。这种设计使得数据集能够深度揭示模型在不同知识范畴与问题复杂度下的能力差异,超越了单一综合评分的局限性。数据集规模精炼,包含18条实例,每条都承载了丰富的评估维度,为分析模型的长处与短板提供了高密度的信息支撑,特别适用于模型能力剖面分析与基准比较研究。
使用方法
该数据集的使用主要服务于大语言模型的性能评估与比较研究。研究人员可首先加载数据集,通过分析‘overall’字段获取模型的综合性能概览,进而深入探究‘easy’、‘med’、‘hard’等字段以评估其应对不同难度问题的稳健性。针对特定领域的研究,如科技或历史问答,可重点考察‘tech’、‘hist’等相应类别得分。通过交叉对比不同‘method_name’和‘organization’下的各项分数,能够系统性地进行模型能力画像、识别优势领域,并为模型改进或应用场景选择提供数据驱动的决策依据。
背景与挑战
背景概述
OmniGAIA-Leaderboard数据集诞生于人工智能领域对通用知识问答能力进行系统性评估的需求背景下。该数据集由相关研究机构或团队构建,旨在通过一个标准化的排行榜形式,追踪和比较不同模型在多样化知识领域的表现。其核心研究问题聚焦于衡量模型在涵盖地理、科技、历史、金融、体育、艺术、电影、科学及食品等多个垂直领域的综合知识理解与应答能力。该数据集的创建为评估模型的泛化性和领域适应性提供了重要基准,推动了通用人工智能在知识密集型任务上的进展。
当前挑战
该数据集致力于解决通用知识问答这一复杂领域问题,其挑战在于如何设计一个全面且平衡的评估框架,以准确反映模型在广泛知识主题上的真实能力,避免因领域偏差或难度分布不均而导致评估失真。在构建过程中,面临的挑战包括收集和标注涵盖多个专业领域的高质量问答数据,确保不同难度等级(如简单、中等、困难)划分的合理性与一致性,以及维护排行榜数据的时效性与公平性,以动态适应快速演进的人工智能模型生态。
常用场景
经典使用场景
在人工智能领域,特别是大型语言模型(LLM)的评估与比较研究中,OmniGAIA-Leaderboard数据集提供了一个标准化的基准平台。该数据集通过记录不同模型在多个难度级别和主题类别上的性能得分,使得研究人员能够系统地分析模型在知识问答、推理能力及跨领域适应性方面的表现。这种结构化的评估框架,为模型优化和算法改进提供了直观的数据支持,促进了模型性能的横向对比与纵向追踪。
实际应用
在实际应用中,OmniGAIA-Leaderboard数据集被广泛用于指导企业及研究机构在模型选型、部署优化及产品开发中的决策。例如,在构建智能助手、教育工具或专业咨询系统时,开发者可依据该数据集中各模型在特定领域(如金融分析或科技解答)的表现,选择最适合的底层模型,从而提升应用系统的准确性和用户满意度。同时,它也为投资评估和市场竞争分析提供了客观的性能参照。
衍生相关工作
围绕OmniGAIA-Leaderboard数据集,已衍生出一系列经典研究工作,包括基于其多维评分体系的模型融合策略、跨领域知识迁移方法,以及针对“困难”类别问题的增强推理技术。这些工作不仅拓展了数据集的解读维度,还催生了新的评估指标和基准测试,如结合动态难度调整或实时性能监控的扩展框架,进一步丰富了大型语言模型评估生态系统的理论构建与实践创新。
以上内容由遇见数据集搜集并总结生成


