FlexWorld
收藏arXiv2025-03-17 更新2025-03-19 收录
下载链接:
https://ml-gsai.github.io/FlexWorld
下载链接
链接失效反馈官方服务:
资源简介:
FlexWorld数据集是由中国人民大学等机构的研究人员创建的,用于支持灵活视角3D场景生成的数据集。该数据集通过视频到视频扩散模型和几何感知3D场景融合技术,从单张图片中生成高质量的视频和灵活视角的3D场景。数据集的具体大小和条数在文中未提及。
The FlexWorld Dataset was created by researchers from institutions including Renmin University of China and other relevant organizations, to support flexible-view 3D scene generation. This dataset leverages video-to-video diffusion models and geometry-aware 3D scene fusion techniques to generate high-quality videos and flexible-view 3D scenes from a single image. The specific size and sample count of this dataset are not mentioned in the relevant text.
提供机构:
中国人民大学
创建时间:
2025-03-17
搜集汇总
数据集介绍
构建方式
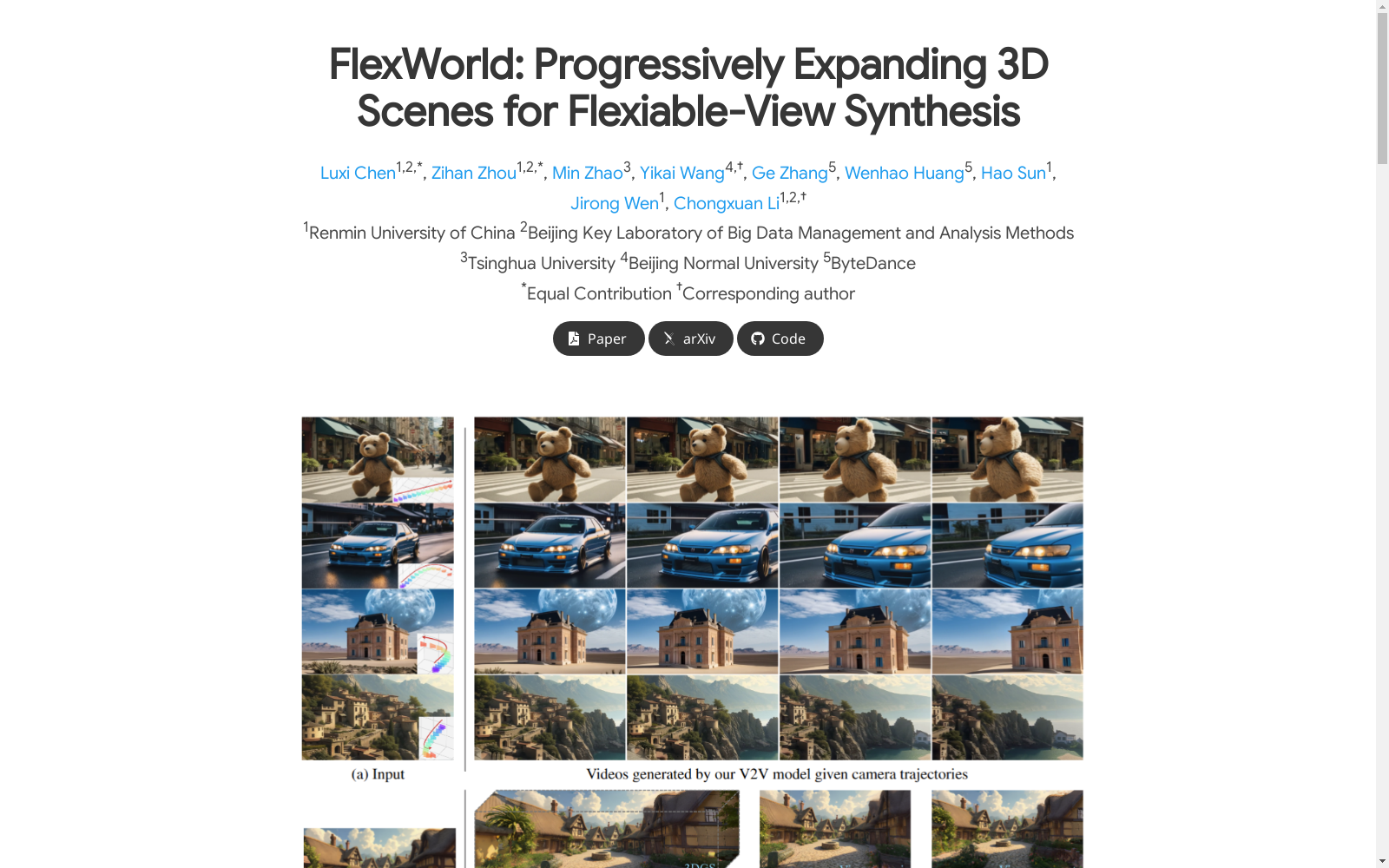
FlexWorld数据集的构建基于一种渐进式的3D场景扩展框架,结合了视频到视频(V2V)扩散模型和几何感知的场景融合技术。首先,通过预训练的视频模型生成高质量的新视角图像,随后利用深度估计训练对进行场景扩展。该框架通过逐步生成新的3D内容并将其整合到全局场景中,最终从单张图像构建出完整的3D场景。这一过程不仅确保了场景的几何一致性,还支持大范围的相机姿态变化。
使用方法
FlexWorld数据集的使用方法主要包括两个步骤:首先,通过V2V扩散模型从单张图像生成高质量的新视角视频;其次,利用几何感知的场景扩展技术逐步构建完整的3D场景。用户可以通过预定义的相机轨迹生成新视角视频,并通过场景融合和优化过程逐步扩展3D场景。该数据集适用于需要从单张图像生成高质量3D场景的研究和应用,如虚拟现实内容生成和3D场景重建。
背景与挑战
背景概述
FlexWorld是由中国人民大学高瓴人工智能学院等机构的研究团队于2025年提出的一种新型框架,旨在从单张图像生成具有灵活视角的3D场景。该框架的核心研究问题是如何在缺乏完整3D数据的情况下,通过单张2D图像生成高质量的多视角3D场景,支持360°旋转和缩放等复杂视角变换。FlexWorld的提出为考古保护、自动驾驶导航等领域的3D场景重建提供了新的解决方案。该框架结合了视频到视频(V2V)扩散模型和渐进式3D场景扩展技术,能够从粗糙的场景渲染中生成高质量的新视角图像,并通过几何感知的场景融合逐步构建完整的3D场景。FlexWorld的推出在3D场景生成领域具有重要的影响力,特别是在处理大视角变化时表现出色。
当前挑战
FlexWorld面临的挑战主要集中在两个方面。首先,从单张图像生成多视角3D场景是一个典型的病态问题,单张2D图像无法提供足够的信息来推断完整的3D结构,尤其是在极端视角(如180°旋转)下,先前被遮挡或完全缺失的内容会引入显著的不确定性。其次,在构建过程中,如何确保生成的3D场景在不同视角下保持几何一致性是一个关键挑战。现有的方法在处理大视角变化时往往难以保持一致性,导致生成的场景在视觉质量和几何准确性上存在缺陷。此外,FlexWorld在训练数据的选择和模型优化上也面临挑战,特别是在如何生成高质量的深度估计数据以及如何在大视角变化下保持视频生成的一致性方面。这些挑战需要通过精细的模型设计和数据优化来解决。
常用场景
经典使用场景
FlexWorld数据集在计算机视觉领域中被广泛用于生成灵活视角的3D场景,尤其是在单张图像到3D场景的转换任务中。其核心应用场景包括从单张图像生成360度旋转和缩放的高质量3D场景,适用于虚拟现实、增强现实以及3D内容创作等领域。通过其强大的视频到视频(V2V)扩散模型,FlexWorld能够从粗糙的场景渲染中生成高质量的新视角图像,并通过渐进式扩展过程构建完整的3D场景。
解决学术问题
FlexWorld解决了从单张图像生成3D场景时的视角扩展问题,尤其是在极端视角(如180度旋转)下,传统方法难以处理遮挡或缺失内容的问题。通过结合先进的预训练视频模型和精确的深度估计训练对,FlexWorld能够在相机姿态变化较大的情况下生成一致且高质量的3D内容。这一突破为3D场景生成领域提供了新的解决方案,显著提升了生成场景的视觉质量和几何一致性。
实际应用
FlexWorld的实际应用场景广泛,尤其在虚拟现实(VR)和增强现实(AR)内容创作中表现出色。例如,在考古保护领域,FlexWorld可以从单张历史照片生成完整的3D场景,帮助研究人员更好地理解和保存文化遗产。此外,在自动驾驶导航中,FlexWorld能够从单张图像生成周围环境的3D模型,为车辆提供更精确的环境感知能力。其灵活视角生成能力还为3D旅游和虚拟导览提供了新的可能性。
数据集最近研究
最新研究方向
FlexWorld数据集在3D场景生成领域的最新研究方向主要集中在从单张图像生成具有灵活视角的高质量3D场景。通过结合视频到视频(V2V)扩散模型和渐进式3D场景扩展技术,FlexWorld能够处理大范围的相机姿态变化,生成支持360°旋转和缩放的3D场景。这一技术突破了传统方法在处理极端视角时的局限性,显著提升了场景生成的视觉质量和一致性。FlexWorld的应用潜力广泛,涵盖了虚拟现实、考古保护、自动驾驶导航等多个领域,为3D内容创作提供了新的可能性。
相关研究论文
- 1FlexWorld: Progressively Expanding 3D Scenes for Flexiable-View Synthesis中国人民大学 · 2025年
以上内容由遇见数据集搜集并总结生成


