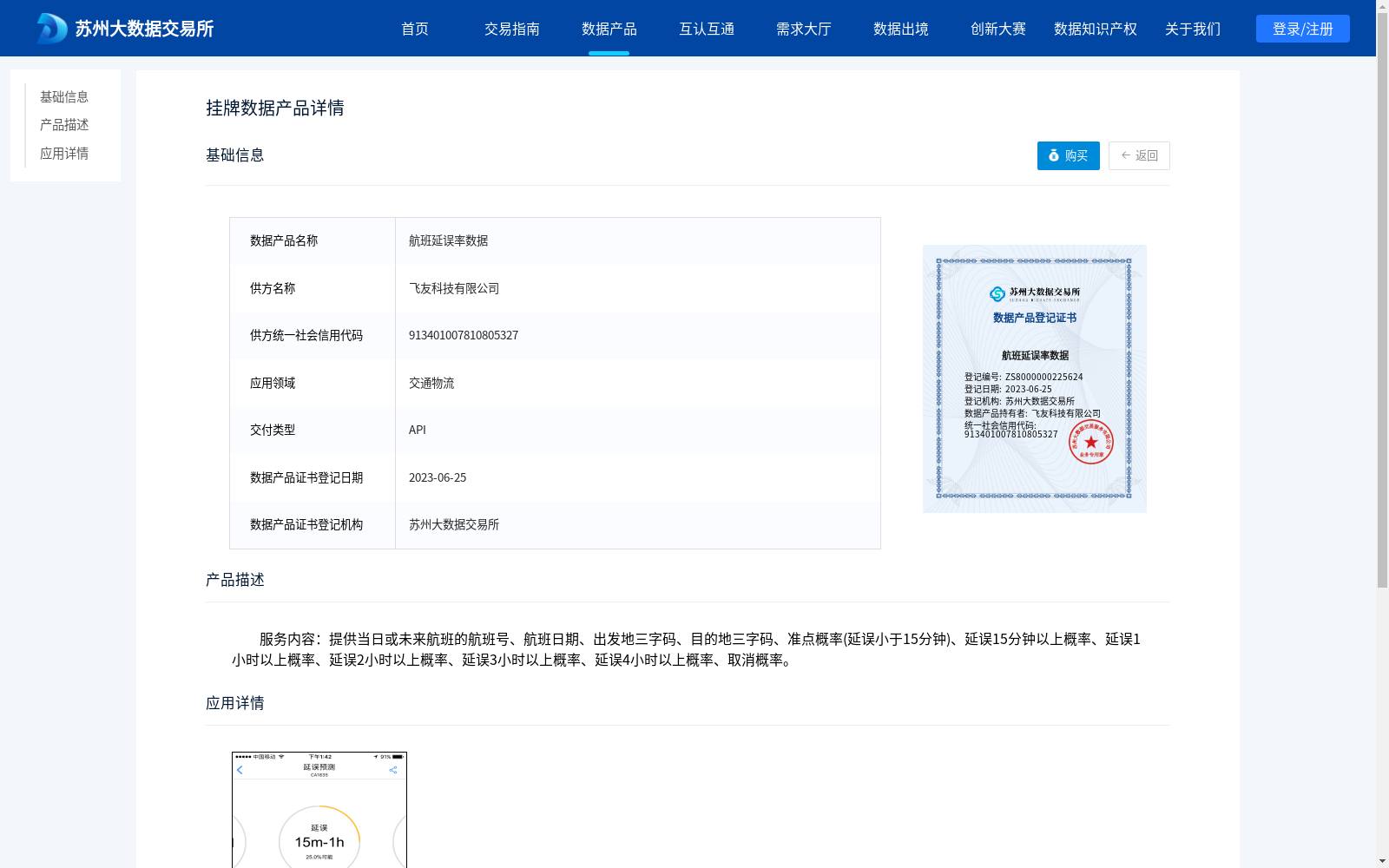
航班延误率数据
收藏苏州大数据交易所2023-06-25 更新2024-04-26 收录
下载链接:
https://jy.suzhou.com.cn/#/product-detail/498
下载链接
链接失效反馈官方服务:
资源简介:
服务内容:提供当日或未来航班的航班号、航班日期、出发地三字码、目的地三字码、准点概率(延误小于15分钟)、延误15分钟以上概率、延误1小时以上概率、延误2小时以上概率、延误3小时以上概率、延误4小时以上概率、取消概率。
Service Content: This dataset provides flight number, flight date, 3-letter origin airport code, 3-letter destination airport code, on-time probability (delay < 15 minutes), probability of delay ≥15 minutes, probability of delay ≥1 hour, probability of delay ≥2 hours, probability of delay ≥3 hours, probability of delay ≥4 hours, and cancellation probability for same-day or upcoming flights.
提供机构:
飞友科技有限公司
创建时间:
2023-06-25
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集提供航班延误率数据,包括准点概率和不同时间段的延误概率及取消概率,适用于交通物流领域,通过API交付。
以上内容由遇见数据集搜集并总结生成


