sanchit-gandhi/librispeech_asr_dummy
收藏Hugging Face2023-11-02 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/sanchit-gandhi/librispeech_asr_dummy
下载链接
链接失效反馈官方服务:
资源简介:
---
annotations_creators:
- expert-generated
language_creators:
- crowdsourced
- expert-generated
language:
- en
license:
- cc-by-4.0
multilinguality:
- monolingual
size_categories:
- 100K<n<1M
source_datasets:
- original
task_categories:
- automatic-speech-recognition
- audio-classification
task_ids:
- speaker-identification
paperswithcode_id: librispeech-1
pretty_name: LibriSpeech Dummy
configs:
- config_name: default
data_files:
- split: test.other
path: data/test.other-*
- split: train.other.500
path: data/train.other.500-*
- split: train.clean.360
path: data/train.clean.360-*
- split: validation.clean
path: data/validation.clean-*
- split: test.clean
path: data/test.clean-*
- split: validation.other
path: data/validation.other-*
- split: train.clean.100
path: data/train.clean.100-*
- config_name: short-form
data_files:
- split: validation
path: short-form/validation-*
dataset_info:
config_name: short-form
features:
- name: file
dtype: string
- name: audio
dtype:
audio:
sampling_rate: 16000
- name: text
dtype: string
- name: speaker_id
dtype: int64
- name: chapter_id
dtype: int64
- name: id
dtype: string
splits:
- name: validation
num_bytes: 9677021.0
num_examples: 73
download_size: 9192059
dataset_size: 9677021.0
---
# Dataset Card for librispeech_asr_dummy
## Table of Contents
- [Dataset Description](#dataset-description)
- [Dataset Summary](#dataset-summary)
- [Supported Tasks and Leaderboards](#supported-tasks-and-leaderboards)
- [Languages](#languages)
- [Dataset Structure](#dataset-structure)
- [Data Instances](#data-instances)
- [Data Fields](#data-fields)
- [Data Splits](#data-splits)
- [Dataset Creation](#dataset-creation)
- [Curation Rationale](#curation-rationale)
- [Source Data](#source-data)
- [Annotations](#annotations)
- [Personal and Sensitive Information](#personal-and-sensitive-information)
- [Considerations for Using the Data](#considerations-for-using-the-data)
- [Social Impact of Dataset](#social-impact-of-dataset)
- [Discussion of Biases](#discussion-of-biases)
- [Other Known Limitations](#other-known-limitations)
- [Additional Information](#additional-information)
- [Dataset Curators](#dataset-curators)
- [Licensing Information](#licensing-information)
- [Citation Information](#citation-information)
- [Contributions](#contributions)
## Dataset Description
- **Homepage:** [LibriSpeech ASR corpus](http://www.openslr.org/12)
- **Repository:** [Needs More Information]
- **Paper:** [LibriSpeech: An ASR Corpus Based On Public Domain Audio Books](https://www.danielpovey.com/files/2015_icassp_librispeech.pdf)
- **Leaderboard:** [The 🤗 Speech Bench](https://huggingface.co/spaces/huggingface/hf-speech-bench)
- **Point of Contact:** [Daniel Povey](mailto:dpovey@gmail.com)
### Dataset Summary
This is a **truncated** version of the LibriSpeech dataset. It contains 20 samples from each of the splits. To view the full dataset, visit: https://huggingface.co/datasets/librispeech_asr
LibriSpeech is a corpus of approximately 1000 hours of 16kHz read English speech, prepared by Vassil Panayotov with the assistance of Daniel Povey. The data is derived from read audiobooks from the LibriVox project, and has been carefully segmented and aligned.
### Supported Tasks and Leaderboards
- `automatic-speech-recognition`, `audio-speaker-identification`: The dataset can be used to train a model for Automatic Speech Recognition (ASR). The model is presented with an audio file and asked to transcribe the audio file to written text. The most common evaluation metric is the word error rate (WER). The task has an active Hugging Face leaderboard which can be found at https://huggingface.co/spaces/huggingface/hf-speech-bench. The leaderboard ranks models uploaded to the Hub based on their WER. An external leaderboard at https://paperswithcode.com/sota/speech-recognition-on-librispeech-test-clean ranks the latest models from research and academia.
### Languages
The audio is in English. There are two configurations: `clean` and `other`.
The speakers in the corpus were ranked according to the WER of the transcripts of a model trained on
a different dataset, and were divided roughly in the middle,
with the lower-WER speakers designated as "clean" and the higher WER speakers designated as "other".
## Dataset Structure
### Data Instances
A typical data point comprises the path to the audio file, usually called `file` and its transcription, called `text`. Some additional information about the speaker and the passage which contains the transcription is provided.
```
{'chapter_id': 141231,
'file': '/home/patrick/.cache/huggingface/datasets/downloads/extracted/b7ded9969e09942ab65313e691e6fc2e12066192ee8527e21d634aca128afbe2/dev_clean/1272/141231/1272-141231-0000.flac',
'audio': {'path': '/home/patrick/.cache/huggingface/datasets/downloads/extracted/b7ded9969e09942ab65313e691e6fc2e12066192ee8527e21d634aca128afbe2/dev_clean/1272/141231/1272-141231-0000.flac',
'array': array([-0.00048828, -0.00018311, -0.00137329, ..., 0.00079346,
0.00091553, 0.00085449], dtype=float32),
'sampling_rate': 16000},
'id': '1272-141231-0000',
'speaker_id': 1272,
'text': 'A MAN SAID TO THE UNIVERSE SIR I EXIST'}
```
### Data Fields
- file: A path to the downloaded audio file in .flac format.
- audio: A dictionary containing the path to the downloaded audio file, the decoded audio array, and the sampling rate. Note that when accessing the audio column: `dataset[0]["audio"]` the audio file is automatically decoded and resampled to `dataset.features["audio"].sampling_rate`. Decoding and resampling of a large number of audio files might take a significant amount of time. Thus it is important to first query the sample index before the `"audio"` column, *i.e.* `dataset[0]["audio"]` should **always** be preferred over `dataset["audio"][0]`.
- text: the transcription of the audio file.
- id: unique id of the data sample.
- speaker_id: unique id of the speaker. The same speaker id can be found for multiple data samples.
- chapter_id: id of the audiobook chapter which includes the transcription.
### Data Splits
The size of the corpus makes it impractical, or at least inconvenient
for some users, to distribute it as a single large archive. Thus the
training portion of the corpus is split into three subsets, with approximate size 100, 360 and 500 hours respectively.
A simple automatic
procedure was used to select the audio in the first two sets to be, on
average, of higher recording quality and with accents closer to US
English. An acoustic model was trained on WSJ’s si-84 data subset
and was used to recognize the audio in the corpus, using a bigram
LM estimated on the text of the respective books. We computed the
Word Error Rate (WER) of this automatic transcript relative to our
reference transcripts obtained from the book texts.
The speakers in the corpus were ranked according to the WER of
the WSJ model’s transcripts, and were divided roughly in the middle,
with the lower-WER speakers designated as "clean" and the higher-WER speakers designated as "other".
For "clean", the data is split into train, validation, and test set. The train set is further split into train.100 and train.360
respectively accounting for 100h and 360h of the training data.
For "other", the data is split into train, validation, and test set. The train set contains approximately 500h of recorded speech.
| | Train.500 | Train.360 | Train.100 | Valid | Test |
| ----- | ------ | ----- | ---- | ---- | ---- |
| clean | - | 104014 | 28539 | 2703 | 2620|
| other | 148688 | - | - | 2864 | 2939 |
## Dataset Creation
### Personal and Sensitive Information
The dataset consists of people who have donated their voice online. You agree to not attempt to determine the identity of speakers in this dataset.
## Additional Information
### Dataset Curators
The dataset was initially created by Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur.
### Licensing Information
[CC BY 4.0](https://creativecommons.org/licenses/by/4.0/)
### Citation Information
```
@inproceedings{panayotov2015librispeech,
title={Librispeech: an ASR corpus based on public domain audio books},
author={Panayotov, Vassil and Chen, Guoguo and Povey, Daniel and Khudanpur, Sanjeev},
booktitle={Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Conference on},
pages={5206--5210},
year={2015},
organization={IEEE}
}
```
注释创建者:
- 专家生成
语言创建者:
- 众包
- 专家生成
语言:
- 英语
许可协议:
- CC BY 4.0
多语言属性:
- 单语言
样本规模类别:
- 100K<n<1M
源数据集:
- 原始数据集
任务类别:
- 自动语音识别
- 音频分类
任务子任务:
- 说话人识别
paperswithcode编号: librispeech-1
展示名称: LibriSpeech Dummy
配置项:
- 配置名称: default
数据文件:
- 拆分: test.other
路径: data/test.other-*
- 拆分: train.other.500
路径: data/train.other.500-*
- 拆分: train.clean.360
路径: data/train.clean.360-*
- 拆分: validation.clean
路径: data/validation.clean-*
- 拆分: test.clean
路径: data/test.clean-*
- 拆分: validation.other
路径: data/validation.other-*
- 拆分: train.clean.100
路径: data/train.clean.100-*
- 配置名称: short-form
数据文件:
- 拆分: validation
路径: short-form/validation-*
数据集信息:
配置名称: short-form
特征:
- 名称: file
数据类型: 字符串
- 名称: audio
数据类型:
音频:
采样率: 16000
- 名称: text
数据类型: 字符串
- 名称: speaker_id
数据类型: int64
- 名称: chapter_id
数据类型: int64
- 名称: id
数据类型: 字符串
拆分:
- 名称: validation
字节数: 9677021.0
样本数: 73
下载大小: 9192059
数据集大小: 9677021.0
# librispeech_asr_dummy 数据集卡片
## 目录
- [数据集描述](#dataset-description)
- [数据集摘要](#dataset-summary)
- [支持任务与排行榜](#supported-tasks-and-leaderboards)
- [语言](#languages)
- [数据集结构](#dataset-structure)
- [数据样本](#data-instances)
- [数据字段](#data-fields)
- [数据拆分](#data-splits)
- [数据集创建](#dataset-creation)
- [数据集构建初衷](#curation-rationale)
- [源数据](#source-data)
- [注释标注](#annotations)
- [个人与敏感信息](#personal-and-sensitive-information)
- [数据使用注意事项](#considerations-for-using-the-data)
- [数据集的社会影响](#social-impact-of-dataset)
- [偏差讨论](#discussion-of-biases)
- [其他已知局限](#other-known-limitations)
- [附加信息](#additional-information)
- [数据集维护者](#dataset-curators)
- [许可协议信息](#licensing-information)
- [引用信息](#citation-information)
- [贡献](#contributions)
## 数据集描述
- **主页**:[LibriSpeech ASR语料库](http://www.openslr.org/12)
- **代码仓库**:[需补充更多信息]
- **相关论文**:[LibriSpeech: 基于公有领域有声读物的ASR语料库](https://www.danielpovey.com/files/2015_icassp_librispeech.pdf)
- **排行榜**:[🤗语音基准测试平台](https://huggingface.co/spaces/huggingface/hf-speech-bench)
- **联系人**:[Daniel Povey](mailto:dpovey@gmail.com)
### 数据集摘要
本数据集为**LibriSpeech数据集的截断版本**,每个数据拆分均包含20个样本。如需获取完整数据集,请访问:https://huggingface.co/datasets/librispeech_asr。
LibriSpeech是一个包含约1000小时16kHz朗读英语语音的语料库,由Vassil Panayotov主导制作,Daniel Povey协助完成。该数据集源自LibriVox项目的公有领域有声读物,并经过严格分段与对齐处理。
### 支持任务与排行榜
- `automatic-speech-recognition`(自动语音识别)、`audio-speaker-identification`(音频说话人识别):本数据集可用于训练自动语音识别(Automatic Speech Recognition, ASR)模型。模型接收输入音频文件,并需将其转录为书面文本。最常用的评估指标为词错误率(Word Error Rate, WER)。该任务设有活跃的Hugging Face排行榜,可通过https://huggingface.co/spaces/huggingface/hf-speech-bench访问。该排行榜基于模型在Hugging Face Hub上上传的WER结果进行排名。另有外部排行榜https://paperswithcode.com/sota/speech-recognition-on-librispeech-test-clean,用于排名来自科研与学术界的最新语音识别模型。
### 语言
本数据集的音频语言为英语,包含两种配置:`clean`(清晰语音)与`other`(普通语音)。
语料库中的说话人基于在另一数据集上训练的模型的转录词错误率进行排名,并大致以中位数划分:词错误率较低的说话人被归类为"clean",词错误率较高的则归类为"other"。
## 数据集结构
### 数据样本
典型的数据样本包含音频文件路径(通常命名为`file`)及其转录文本(命名为`text`),同时提供与说话人及包含该转录文本的章节相关的额外信息。
{'chapter_id': 141231,
'file': '/home/patrick/.cache/huggingface/datasets/downloads/extracted/b7ded9969e09942ab65313e691e6fc2e12066192ee8527e21d634aca128afbe2/dev_clean/1272/141231/1272-141231-0000.flac',
'audio': {'path': '/home/patrick/.cache/huggingface/datasets/downloads/extracted/b7ded9969e09942ab65313e691e6fc2e12066192ee8527e21d634aca128afbe2/dev_clean/1272/141231/1272-141231-0000.flac',
'array': array([-0.00048828, -0.00018311, -0.00137329, ..., 0.00079346,
0.00091553, 0.00085449], dtype=float32),
'sampling_rate': 16000},
'id': '1272-141231-0000',
'speaker_id': 1272,
'text': 'A MAN SAID TO THE UNIVERSE SIR I EXIST'}
### 数据字段
- `file`:指向下载的FLAC格式音频文件的路径。
- `audio`:包含下载音频文件路径、解码后的音频数组以及采样率的字典。请注意,当访问音频列时:`dataset[0]["audio"]`会自动将音频文件解码并重采样为`dataset.features["audio"].sampling_rate`指定的采样率。批量解码与重采样大量音频文件可能会耗费大量时间,因此建议优先通过样本索引查询,即**始终优先使用`dataset[0]["audio"]`而非`dataset["audio"][0]`**。
- `text`:音频文件的转录文本。
- `id`:数据样本的唯一标识符。
- `speaker_id`:说话人的唯一标识符,同一说话人ID可对应多个数据样本。
- `chapter_id`:包含该转录文本的有声读物章节ID。
### 数据拆分
由于语料库规模庞大,将其作为单个大型归档文件分发既不现实,也会给部分用户带来不便。因此,语料库的训练部分被划分为三个子集,近似大小分别为100、360和500小时。
我们使用简单的自动程序来选择前两个数据集中的音频,使其平均录音质量更高,且口音更贴近美式英语。我们基于WSJ的si-84数据子集训练了一个声学模型,并用基于对应书籍文本训练的二元语言模型(bigram LM),对语料库中的音频进行识别。我们计算了该自动转录结果相对于从书籍文本获取的参考转录结果的词错误率(WER)。
语料库中的说话人基于该WSJ模型转录结果的WER进行排名,并大致以中位数划分:低WER说话人被标记为"clean",高WER说话人被标记为"other"。
对于"clean"配置,数据被划分为训练集、验证集与测试集。训练集进一步拆分为train.100与train.360,分别对应100小时与360小时的训练数据。对于"other"配置,数据被划分为训练集、验证集与测试集,其中训练集包含约500小时的录制语音。
| | Train.500 | Train.360 | Train.100 | Valid | Test |
| ----- | ------ | ----- | ---- | ---- | ---- |
| clean | - | 104014 | 28539 | 2703 | 2620|
| other | 148688 | - | - | 2864 | 2939 |
## 数据集创建
### 个人与敏感信息
本数据集由在线捐赠语音的民众组成。您同意不尝试识别本数据集中的说话人身份。
## 附加信息
### 数据集维护者
本数据集最初由Vassil Panayotov、Guoguo Chen、Daniel Povey与Sanjeev Khudanpur创建。
### 许可协议信息
采用CC BY 4.0协议,详情请访问:https://creativecommons.org/licenses/by/4.0/
### 引用信息
@inproceedings{panayotov2015librispeech,
title={LibriSpeech: an ASR corpus based on public domain audio books},
author={Panayotov, Vassil and Chen, Guoguo and Povey, Daniel and Khudanpur, Sanjeev},
booktitle={Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Conference on},
pages={5206--5210},
year={2015},
organization={IEEE}
}
提供机构:
sanchit-gandhi
原始信息汇总
数据集概述
数据集名称: LibriSpeech Dummy
数据集描述: 这是一个LibriSpeech数据集的截断版本,包含每个分割的20个样本。LibriSpeech是一个大约1000小时的16kHz英语朗读语音的语料库,由Vassil Panayotov在Daniel Povey的帮助下准备。数据来源于LibriVox项目的朗读有声书,并经过仔细的分割和校准。
语言: 英语
许可证: CC-BY-4.0
多语言性: 单语
大小类别: 100K<n<1M
源数据集: 原始数据
任务类别:
- 自动语音识别
- 音频分类
任务ID: 说话人识别
配置:
- 默认配置:
- 数据文件路径包括:
- 测试集:
data/test.other-* - 训练集:
data/train.other.500-* - 训练集:
data/train.clean.360-* - 验证集:
data/validation.clean-* - 测试集:
data/test.clean-* - 验证集:
data/validation.other-* - 训练集:
data/train.clean.100-*
- 测试集:
- 数据文件路径包括:
- 短格式配置:
- 数据文件路径包括:
- 验证集:
short-form/validation-*
- 验证集:
- 数据文件路径包括:
数据集信息:
- 配置名称: 短格式
- 特征:
- 文件名: 字符串
- 音频:
- 采样率: 16000
- 文本: 字符串
- 说话人ID: 整数
- 章节ID: 整数
- ID: 字符串
- 分割:
- 验证集:
- 字节数: 9677021.0
- 样本数: 73
- 下载大小: 9192059
- 数据集大小: 9677021.0
- 验证集:
数据集结构
数据实例:
- 典型的数据点包括音频文件路径(通常称为
file)及其转录文本(称为text)。还提供了有关说话人和包含转录的段落的一些额外信息。
数据字段:
- 文件: 下载的音频文件(.flac格式)的路径。
- 音频: 包含下载的音频文件路径、解码的音频数组和采样率的字典。
- 文本: 音频文件的转录。
- ID: 数据样本的唯一ID。
- 说话人ID: 说话人的唯一ID。
- 章节ID: 包含转录的有声书章节的ID。
数据分割:
- 对于"clean",数据分为训练、验证和测试集。训练集进一步分为train.100和train.360,分别对应100小时和360小时的训练数据。
- 对于"other",数据分为训练、验证和测试集。训练集包含大约500小时的录音。
搜集汇总
数据集介绍
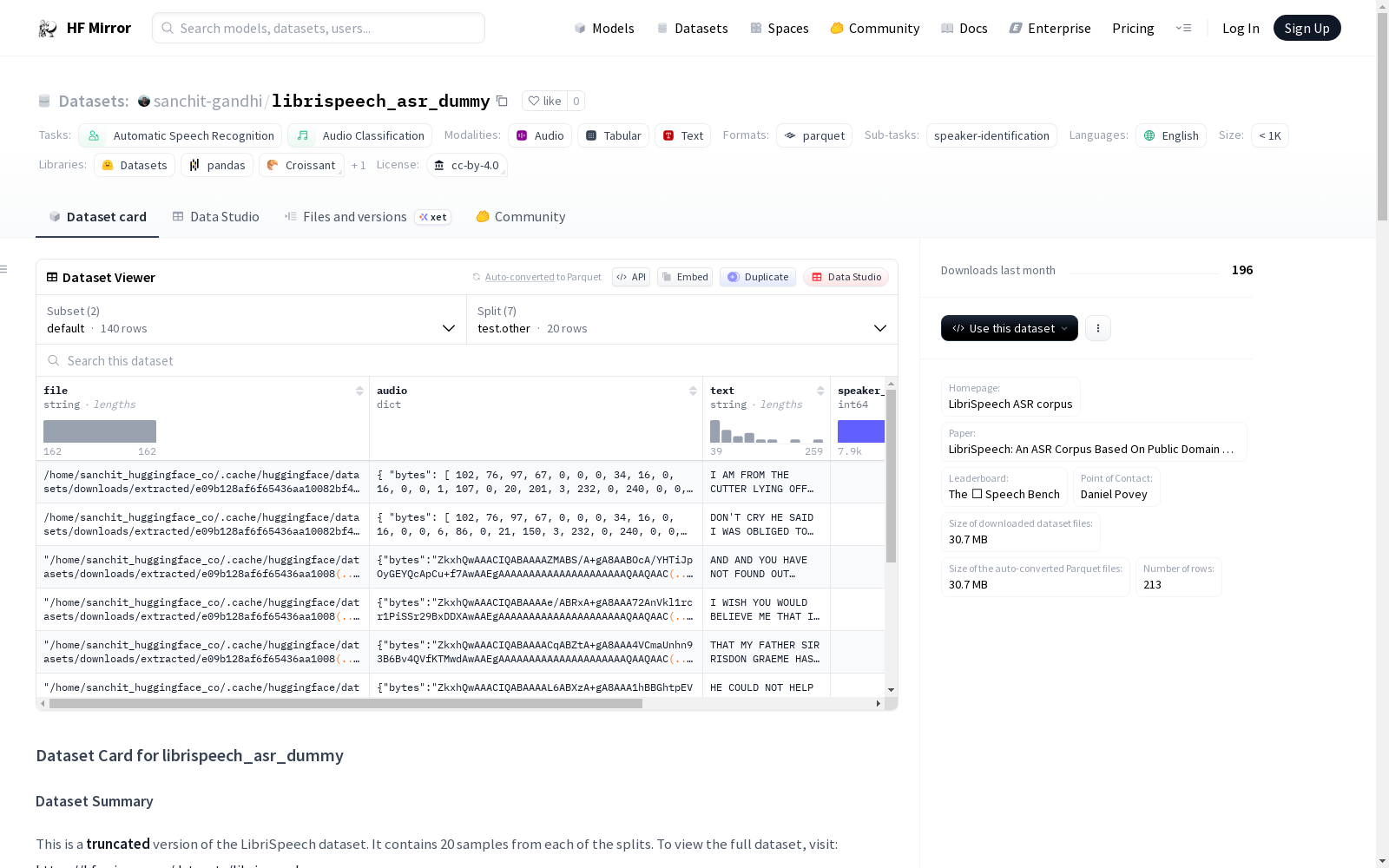
构建方式
在语音识别领域,构建高质量数据集对于模型训练至关重要。LibriSpeech Dummy数据集源自LibriVox项目的公开领域有声读物,通过专家与群体协作的方式精心采集。原始音频经过自动分段与对齐处理,确保语音与文本的精确匹配。数据集的构建过程涉及对大量朗读语音的系统性整理,采用16kHz采样率以保持语音信号的完整性,为后续的自动语音识别任务奠定了坚实基础。
特点
该数据集在语音识别研究中展现出显著特点,其核心在于提供了约1000小时的英语朗读语音,涵盖清晰与带口音两种配置。数据样本包含音频路径、转录文本、说话者及章节标识,支持自动语音识别与说话人识别任务。独特的“clean”与“other”划分基于词错误率,反映了语音质量与口音差异,为模型鲁棒性评估提供了多维度的测试环境。
使用方法
在语音识别模型开发中,该数据集的使用方法较为直观。用户可通过加载数据集配置访问不同分割,如训练集与验证集。每个数据点包含音频数组与对应文本,便于直接输入模型进行端到端训练。评估时通常采用词错误率作为指标,数据集支持在Hugging Face平台上的基准测试,助力研究者对比模型性能并推动技术进步。
背景与挑战
背景概述
LibriSpeech数据集于2015年由约翰斯·霍普金斯大学的Vassil Panayotov、Daniel Povey、Guoguo Chen和Sanjeev Khudanpur等研究人员共同创建,旨在为自动语音识别领域提供一个大规模、高质量的公开基准语料库。该数据集源自LibriVox项目的公共领域有声读物,包含约1000小时的16kHz英文朗读语音,并经过精细的切分和对齐处理。其核心研究问题聚焦于提升ASR系统在长序列、多样化口音和复杂声学环境下的识别精度与鲁棒性。作为语音识别领域的里程碑式资源,LibriSpeech极大地推动了端到端深度学习模型的发展,成为学术界和工业界评估模型性能的标准数据集之一。
当前挑战
在自动语音识别领域,LibriSpeech旨在应对高噪声环境下语音信号与文本对齐的复杂性、说话人变异性以及长序列建模等核心挑战。构建过程中,研究团队面临多重困难:首先,从海量公共有声读物中筛选高质量音频并确保转录准确性,需耗费大量人工校验与专家标注资源;其次,数据分割需平衡语音质量与口音多样性,通过基于WSJ模型词错误率的自动分级机制划分‘clean’与‘other’子集,但这一过程可能引入模型偏差。此外,数据规模的庞大性导致存储与分发效率问题,需设计多子集结构以提升可用性,同时需严格遵循隐私保护原则,避免说话人身份信息泄露。
常用场景
经典使用场景
在语音识别研究领域,LibriSpeech数据集凭借其大规模、高质量的英文朗读语音与精准文本对齐,成为自动语音识别模型训练与评估的基准资源。该数据集常被用于构建端到端的语音识别系统,研究者通过其提供的纯净与带口音语音划分,系统性地探索模型在不同语音质量与口音变体下的泛化能力。经典应用场景包括利用其标准化的训练与测试划分,对比不同神经网络架构在词错误率指标上的表现,从而推动语音识别技术的边界。
实际应用
在实际应用层面,基于LibriSpeech训练的语音识别模型已广泛集成于智能助理、实时字幕生成、语音转录服务及无障碍技术中。其提供的多样化说话人样本与清晰度分级,助力开发出在复杂声学环境下仍保持高准确率的商用系统。例如,该数据集支撑了诸多语音转文本引擎的研发,这些引擎被应用于会议记录、教育内容转录以及媒体行业的音频后期制作,极大地提升了信息获取与处理的效率。
衍生相关工作
围绕LibriSpeech数据集,已衍生出一系列具有里程碑意义的研究工作。例如,基于Transformer的端到端模型如Conformer,以及自监督预训练方法如wav2vec 2.0,均在该数据集上验证了其卓越性能。这些工作不仅刷新了词错误率的记录,更推动了语音表征学习、少样本适应等新方向的发展。此外,该数据集也催生了诸如Libri-Light等扩展项目,进一步探索了在有限监督下的语音识别可能性,持续引领着领域的研究范式。
以上内容由遇见数据集搜集并总结生成


