dpo-pairrm-preferences-llama3
收藏Hugging Face2025-08-12 更新2025-08-13 收录
下载链接:
https://huggingface.co/datasets/pyamy/dpo-pairrm-preferences-llama3
下载链接
链接失效反馈官方服务:
资源简介:
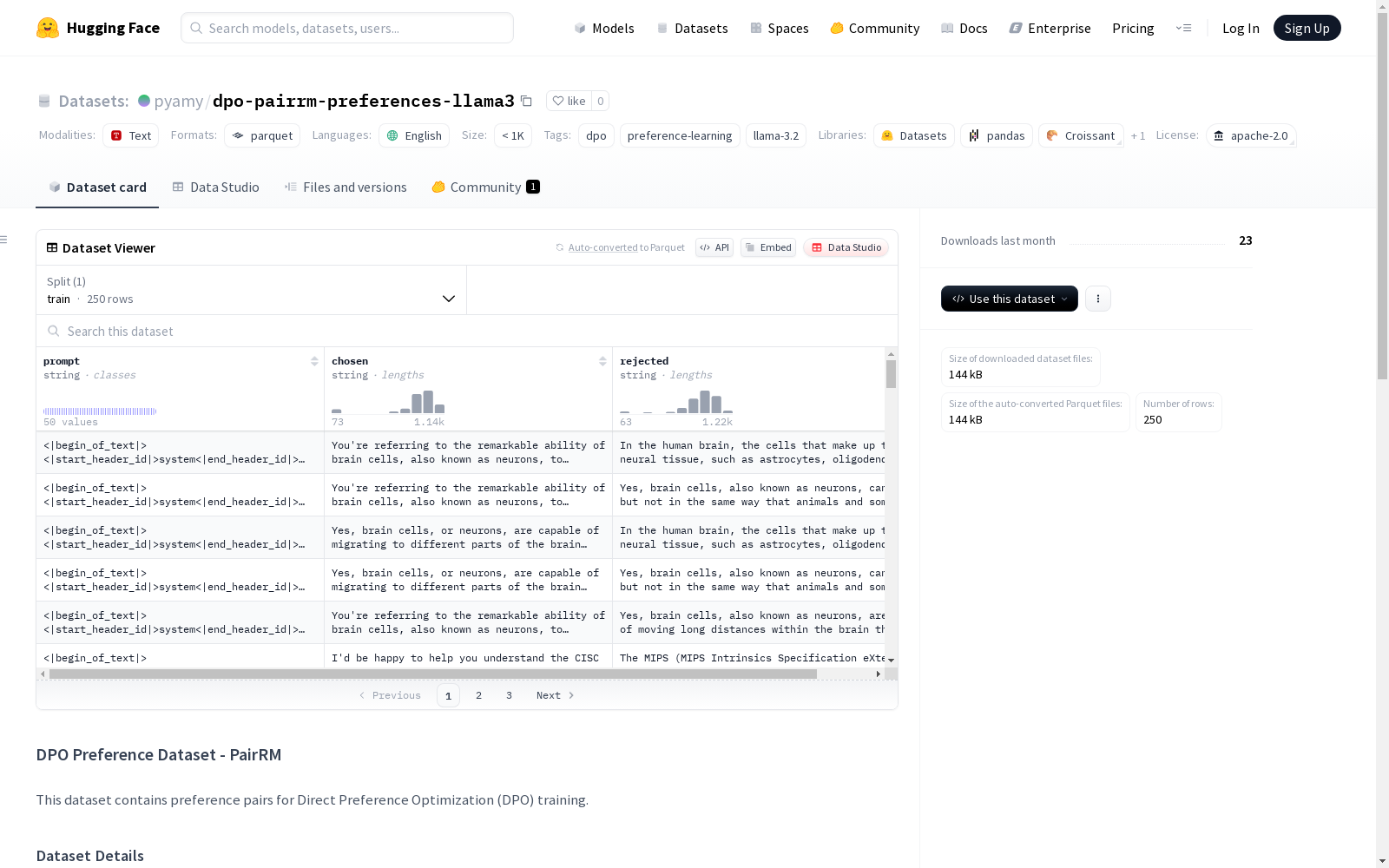
DPO偏好数据集-PairRM是一个包含250个样本的偏好对数据集,用于直接偏好优化(DPO)训练。每个样本包含一个指令提示以及两个响应:一个首选响应和一个较不首选的响应。数据集基于Llama-3.2-1B-Instruct模型创建,通过PairRM方法对从LIMA数据集提取的50个指令生成的5个响应进行排名和配对。
创建时间:
2025-08-11
原始信息汇总
DPO Preference Dataset - PairRM 数据集概述
数据集基本信息
- 标签:dpo, preference-learning, llama-3.2
- 许可证:apache-2.0
- 语言:英语 (en)
- 数据规模:小于1K样本 (n<1K)
数据集详情
- 基础模型:Llama-3.2-1B-Instruct
- 样本数量:250
- 创建方法:PairRM
- 任务类型:指令跟随的偏好学习
数据集结构
每个样本包含以下字段:
prompt:带有聊天模板的指令提示chosen:优选响应rejected:次选响应
使用方式
python from datasets import load_dataset dataset = load_dataset("pyamy/dpo-pairrm-preferences-llama3")
创建过程
- 从LIMA数据集中提取50条指令
- 每条指令生成5个响应
- 使用PairRM进行排序并创建偏好对
- 格式化为DPO训练格式
引用信息
bibtex @dataset{dpo_pairrm_2024, title={DPO PairRM Preference Dataset}, author={pyamy}, year={2024} }
搜集汇总
数据集介绍
构建方式
在指令微调领域,dpo-pairrm-preferences-llama3数据集的构建体现了严谨的偏好学习范式。研究团队从LIMA数据集中精选50条核心指令作为基础,通过Llama-3.2-1B-Instruct模型为每条指令生成5种候选响应,随后采用PairRM评分系统对响应进行自动化排序,最终形成250组包含提示词、优选响应和次选响应的三元组数据。这种构建方式既保留了原始指令的多样性,又通过自动化评估确保了偏好标注的客观性。
特点
该数据集作为直接偏好优化(DPO)训练的专业资源,具有鲜明的技术特征。其核心价值在于通过PairRM模型生成的精细化偏好标注,每个样本都严格遵循'提示-优选-次选'的三元结构,特别适合指令跟随任务的微调研究。数据集规模虽仅包含250个样本,但得益于LIMA指令集的代表性和Llama模型的强生成能力,在有限数据量下仍能保持较高的任务覆盖度和语义多样性。
使用方法
对于希望开展指令偏好学习的研究者,该数据集提供了便捷的接入方式。通过HuggingFace数据集库的load_dataset函数即可直接加载,返回的结构化数据包含prompt、chosen和rejected三个标准字段,与主流DPO训练框架天然兼容。使用时应特别注意提示词已预置聊天模板格式,可直接输入模型进行微调,这种设计显著降低了数据预处理的技术门槛。
背景与挑战
背景概述
随着大型语言模型(LLM)在自然语言处理领域的广泛应用,如何优化模型以更好地遵循人类指令成为研究热点。2024年发布的dpo-pairrm-preferences-llama3数据集应运而生,由研究者pyamy基于Llama-3.2-1B-Instruct模型构建,旨在通过直接偏好优化(DPO)方法提升模型的指令遵循能力。该数据集从LIMA数据集中提取50条指令,结合PairRM评分机制生成250个偏好对样本,为偏好学习领域提供了高质量的训练资源。其创新性在于将PairRM排序系统与DPO框架相结合,为语言模型对齐研究开辟了新路径。
当前挑战
在偏好学习领域,如何准确评估模型响应质量并建立可靠的偏好标准是核心难题。dpo-pairrm-preferences-llama3数据集构建过程中面临多重挑战:PairRM评分系统对生成响应的细微差异可能敏感度不足,导致偏好标注存在潜在偏差;有限的样本规模(仅250个)可能影响模型泛化能力;从LIMA数据集继承的指令多样性不足,制约了模型在复杂场景下的适应性。这些挑战反映出当前偏好学习在评估体系、数据规模和质量平衡等方面仍需突破。
常用场景
经典使用场景
在自然语言处理领域,dpo-pairrm-preferences-llama3数据集为指令跟随任务中的偏好学习提供了重要支持。该数据集基于Llama-3.2-1B-Instruct模型生成,通过PairRM方法构建了250个偏好对样本,每个样本包含指令提示、优选回复和非优选回复。研究人员可以借助这些精细标注的数据,探索语言模型在理解人类意图和生成合适响应方面的优化路径。
衍生相关工作
该数据集已催生多项关于高效偏好学习的研究工作,包括基于对比学习的响应排序算法改进、少样本条件下的偏好迁移学习等。部分研究进一步扩展了其应用范围,将PairRM评分机制与强化学习方法结合,开发出更鲁棒的对话策略优化框架,推动了人机交互系统的性能边界。
数据集最近研究
最新研究方向
在自然语言处理领域,基于人类反馈的强化学习(RLHF)正成为优化大语言模型(LLM)行为的关键技术。dpo-pairrm-preferences-llama3数据集通过PairRM方法构建的偏好对,为直接偏好优化(DPO)算法提供了高质量的训练样本。当前研究聚焦于如何利用小规模但精准的偏好数据,如该数据集中的250个样本,来微调LLM的指令遵循能力。前沿探索方向包括结合对比学习与DPO框架提升模型对细微偏好的捕捉能力,以及研究PairRM等自动化评估工具在降低人工标注成本中的作用。该数据集的发布为LLM对齐研究提供了新的基准,特别是在Llama-3.2架构的轻量化模型优化方面具有示范意义。
以上内容由遇见数据集搜集并总结生成


