AudioTime
收藏arXiv2024-07-03 更新2024-07-23 收录
下载链接:
https://zeyuxie29.github.io/AudioTime/
下载链接
链接失效反馈官方服务:
资源简介:
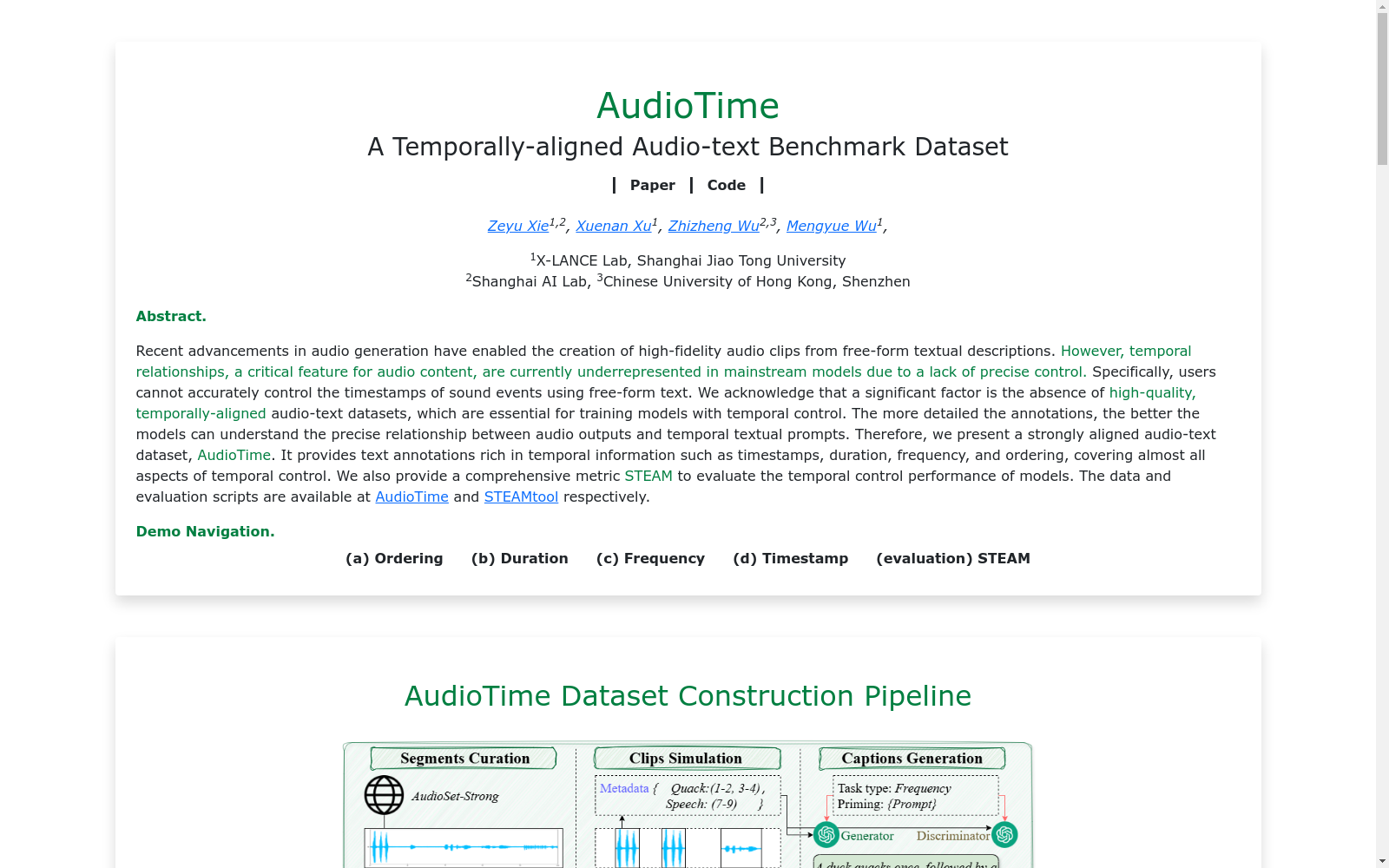
AudioTime数据集由上海交通大学X-LANCE实验室、上海人工智能实验室和香港中文大学(深圳)共同创建,专注于时间对齐的音频-文本数据。该数据集包含5000条训练数据和500条测试数据,每条数据包括一个长达10秒的音频片段、精确的元数据和时间精确标注的文本描述。数据集的创建过程包括音频片段的筛选、声音模拟和文本描述生成,旨在解决音频生成领域中时间控制精度不足的问题。
AudioTime Dataset was jointly created by X-LANCE Lab at Shanghai Jiao Tong University, Shanghai AI Laboratory, and The Chinese University of Hong Kong, Shenzhen. It focuses on time-aligned audio-text data. This dataset contains 5,000 training samples and 500 test samples, each of which includes a 10-second audio clip, precise metadata, and temporally accurately annotated text descriptions. The dataset construction process includes audio clip screening, sound simulation and text description generation, aiming to address the issue of insufficient temporal control accuracy in the field of audio generation.
提供机构:
上海交通大学X-LANCE实验室, 上海人工智能实验室, 香港中文大学(深圳)
创建时间:
2024-07-03
搜集汇总
数据集介绍
构建方式
AudioTime数据集的构建采用了自动化管道,包括音频段落的精选、音频模拟和标题生成三个步骤。首先,从AudioSet-Strong数据集中精选出单一声音段落,确保标注质量。然后,使用Scaper工具模拟音频,记录元数据。最后,利用两个大型语言模型(LLM)生成标题,以反映详细的时序信息。
使用方法
使用AudioTime数据集时,研究者可以利用其提供的音频片段和对应的详细时序标注进行模型训练和评估。通过STEAM度量标准,研究者可以测试和比较不同模型基于自由文本的时序控制能力。
背景与挑战
背景概述
AudioTime数据集是由X-LANCE实验室、上海人工智能实验室以及香港中文大学(深圳)的研究人员共同创建的。该数据集旨在解决当前音频生成模型中时间控制的问题,提供了一种包含丰富时间信息的音频-文本对,以期提高模型对音频输出与文本提示之间精确关系理解的能力。AudioTime数据集的构建采用了全自动化的流程,包括音频段落的筛选、音频模拟以及文本生成等步骤,为相关领域的研究提供了有力的支持。
当前挑战
AudioTime数据集在构建过程中面临的挑战主要包括:如何实现音频事件时间戳的精确标注,以及如何自动化地生成包含详细时间信息的文本描述。此外,所构建的数据集需要能够真实反映现实世界中的时间关系,这对数据集的设计提出了更高的要求。在应用层面,当前的音频生成模型在处理包含多个事件的文本时,往往存在事件遗漏、事件混淆以及音频单调等问题,这些问题的解决依赖于模型对时间控制的精细化和对数据集的深入理解。
常用场景
经典使用场景
AudioTime数据集为音频生成任务提供了丰富的时序对齐的音频-文本样本,其经典使用场景在于训练具有细粒度时序控制能力的音频生成模型。通过该数据集,模型能够学习到文本描述与音频事件之间的精确对应关系,从而在生成音频时实现事件顺序、持续时长、发生频率以及精确时间戳的精细控制。
解决学术问题
AudioTime数据集解决了现有音频生成模型中缺乏细粒度时序控制的问题。传统模型往往无法仅通过自由文本描述实现对音频事件时间戳的准确控制,而AudioTime通过提供包含时间戳、持续时长、频率等丰富时序信息的注释,使得模型能够更好地理解并学习音频事件与文本描述之间的时序对应关系,从而提升模型的时序控制性能。
实际应用
在实际应用中,AudioTime数据集可以应用于音频编辑、声音模拟、语音合成等领域。例如,在音频编辑软件中,利用该数据集训练的模型可以帮助用户更精确地根据文本描述对音频片段进行编辑,或者在语音合成中实现更自然的时序控制,提高语音的流畅性和自然度。
数据集最近研究
最新研究方向
AudioTime数据集针对当前音频生成模型中缺乏时间控制的问题,提供了一种包含丰富时间信息的音频-文本对齐数据集。该数据集通过自动化管道构建,包含精确的时间戳、持续时间、频率和顺序等标注,旨在增强模型对音频事件时间关系的理解。近期研究利用AudioTime数据集,提出了一个新的评价指标STEAM,用于评估模型基于自由文本的时间控制能力。研究分析了现有模型在时间控制方面的不足,并探讨了精确文本控制生成的重要性。
相关研究论文
- 1AudioTime: A Temporally-aligned Audio-text Benchmark Dataset上海交通大学X-LANCE实验室, 上海人工智能实验室, 香港中文大学(深圳) · 2024年
以上内容由遇见数据集搜集并总结生成


