DORAEMONG/PRO-STEP-PRM-Data
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/DORAEMONG/PRO-STEP-PRM-Data
下载链接
链接失效反馈官方服务:
资源简介:
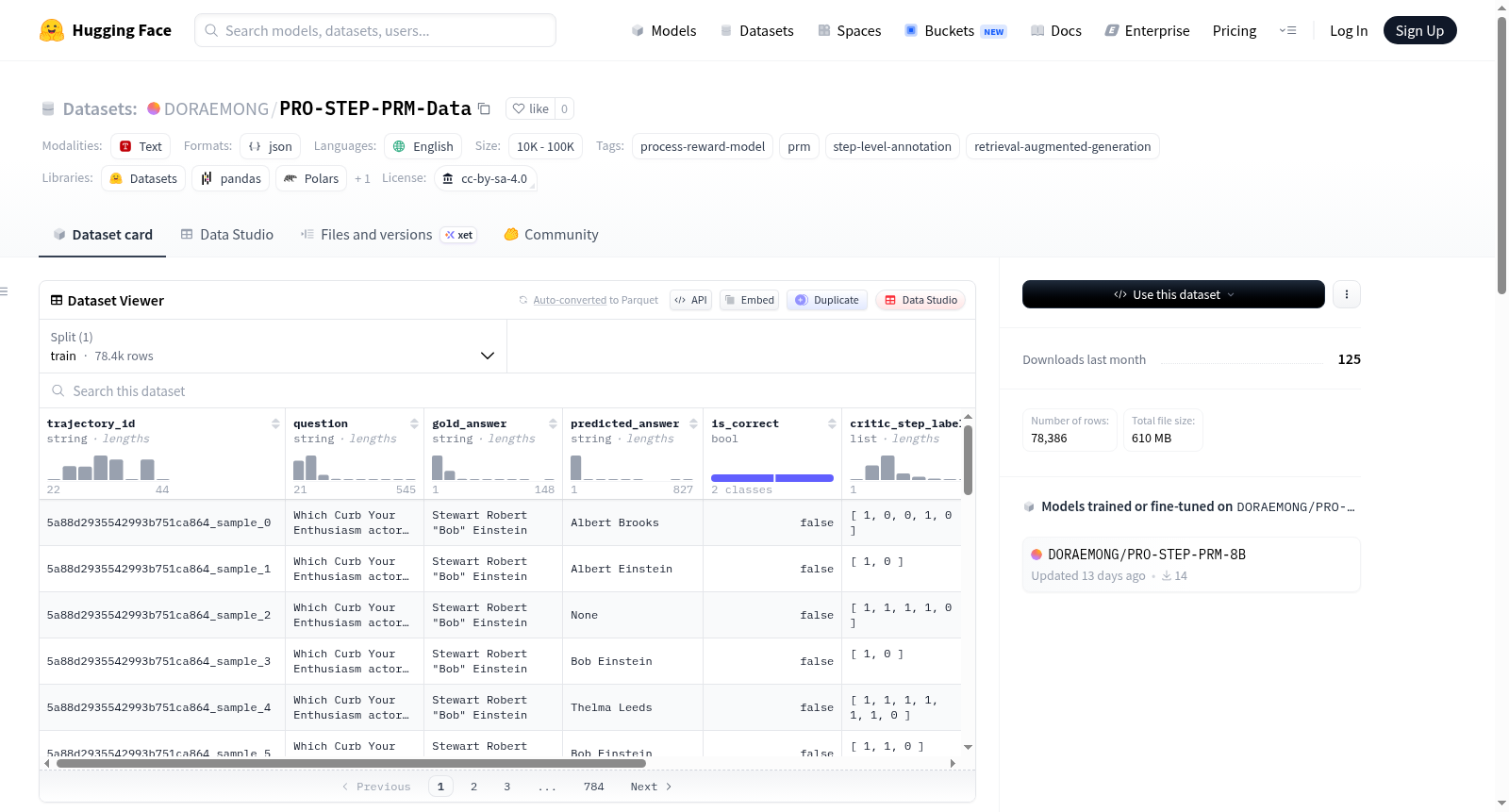
PRO-STEP数据集是一个用于训练PRO-STEP PRM模型的步级注释数据集。它包含约109K步级注释,覆盖31,728条轨迹,数据来源于HotpotQA和MuSiQue训练集的2,000个问题。每个问题生成16条轨迹,注释由QwQ-32B模型根据6个标准(R1实体基础、R2搜索质量、R3推理、R4答案、R5恢复、R6过度自信)进行标注。在50条轨迹的随机样本上,注释达到了84%的人类一致性(95%置信区间[72%, 92%])。数据集以JSONL格式存储,包含问题ID、问题文本、正确答案、步骤注释等字段。
PRO-STEP is a dataset of step-level annotations used to train the PRO-STEP PRM model. It contains ~109K step annotations across 31,728 trajectories, sourced from 2,000 questions (HotpotQA + MuSiQue training splits). Each question has 16 sampled trajectories generated by Qwen2.5-7B-Instruct, annotated by the QwQ-32B model using a 6-criterion rubric (R1 entity grounding, R2 search quality, R3 reasoning, R4 answer, R5 recovery, R6 overconfidence). The annotations achieved 84% human agreement on a 50-trajectory random sample (95% CI [72%, 92%]). The dataset is stored in JSONL format with fields including question_id, question, gold_answer, and step annotations.
提供机构:
DORAEMONG
搜集汇总
数据集介绍
构建方式
该数据集专为训练过程奖励模型(Process Reward Model, PRM)而设计,构建于检索增强生成(Retrieval-Augmented Generation, RAG)这一前沿领域。数据集的构建始于从HotpotQA和MuSiQue的训练集分片中精选2000个问题,随后以Qwen2.5-7B-Instruct为生成器,对每个问题采样16条推理轨迹,最终累积了31,728条轨迹。每条轨迹中的步骤级标注由开源推理模型QwQ-32B依据六项标准(包括实体锚定、搜索质量、推理合理性等)进行自动化评估,生成“GOOD”或“BAD”的二元标签及对应的推理依据,总计约109K条步骤级标注。
特点
PRO-STEP-PRM-Data的核心特点在于其步骤级细粒度标注与自动化验证机制的有机结合。每个步骤不仅包含二元正确性标签,还附带了由QwQ-32B模型生成的详细推理理由,并区分了操作类型(如搜索、推理或回答),这为模型提供了丰富的上下文信号。数据集通过了84%的人工一致性验证(基于50条轨迹的随机样本,95%置信区间为[72%, 92%]),确保了标注的高可靠性。此外,其多源问题覆盖与多样化的生成策略增强了数据的泛化能力。
使用方法
该数据集以JSONL格式存储,每条轨迹包含问题标识符、原始问题、标准答案以及步骤级标注列表,可直接通过HuggingFace的datasets库加载。用户可通过load_dataset函数指定数据文件为“prm_training_steps.jsonl”并选择训练集分割进行访问,输出结果中每个步骤包含索引、标签、推理文本及动作类型字段。该设计旨在支持生成式PRM的训练,使模型能够同时输出步骤级合理性解释与二元正确性判断,适用于RAG场景下的过程监督优化任务。
背景与挑战
背景概述
PRO-STEP-PRM-Data数据集由DORAEMONG团队于2026年创建,聚焦于检索增强生成(RAG)中的过程奖励模型(PRM)训练。该数据集包含约10.9万条步骤级标注,覆盖31,728条轨迹,基于HotpotQA和MuSiQue训练集提取的2,000个问题,利用Qwen2.5-7B-Instruct为每个问题采样16条轨迹,并通过开源推理模型QwQ-32B依据六准则评估框架(涵盖实体锚定、搜索质量、推理、答案、恢复及过度自信)进行标注,经84%的人机一致性验证。该数据集填补了RAG系统中步骤级过程监督数据稀缺的空白,为提升多步推理的细粒度奖励建模提供了关键资源,显著推动了大语言模型在复杂知识密集型任务中的可靠性和可解释性研究。
当前挑战
PRO-STEP-PRM-Data所解决的领域核心挑战在于RAG系统的过程级监督不足——传统结果奖励模型难以准确衡量多步推理中各步骤的局部正确性,导致模型在需要外部知识检索的复合任务中易积累错误。构建过程中面临三大挑战:一是标注成本高昂,需对23万个步骤逐一生成理由并验证二值标签,依靠推理模型QwQ-32B自动标注以降低成本;二是质量保证困难,通过六准则评价框架和随机抽样84%的人类一致性验证确保标注可靠性;三是数据多样性不足,仅依赖HotpotQA和MuSiQue两个数据集,可能限制模型在更广泛RAG场景下的泛化能力。
常用场景
经典使用场景
在检索增强生成与过程奖励模型交叉的研究领域中,PRO-STEP-PRM-Data数据集扮演着基石角色。其经典使用场景聚焦于训练能够对生成链路中每一步进行细粒度质量判别的过程奖励模型。具体而言,研究人员利用该数据集提供的约10.9万条步骤级标注,涵盖来自HotpotQA和MuSiQue的2000道源问题及其31,728条轨迹,通过QwQ-32B模型依据六项准则(实体锚定、检索质量、推理、答案、恢复、过度自信)进行标注,从而训练生成式PRM,使其不仅输出二元正确性判断,还能生成清晰推理过程。这一范式显著提升了模型对复杂推理链中局部步骤的监控与反馈能力。
衍生相关工作
围绕PRO-STEP-PRM-Data,学术界已衍生出多个具有影响力的研究方向。经典的衍生工作包括利用该数据集生成的步骤级标注迁移至其他领域特定过程奖励模型的训练,如科学文献问答与多跳推理场景。此外,研究者探索了基于该数据集微调不同规模的语言模型(从70亿参数到320亿参数),验证了步骤级过程监督在模型规模扩展时的泛化能力。值得一提的是,该数据集的标注协议——六准则评估框架——已被后续工作采纳为过程奖励模型的标准评测基准,推动了公平比较与再现性研究。同时,部分工作关注于利用该数据集的训练范式压缩过程奖励模型,使其在资源受限的端侧设备上也能实现高效的步骤质量监控,拓展了其实用边界。
数据集最近研究
最新研究方向
在检索增强生成(RAG)领域,过程奖励模型(PRM)的训练数据构建正成为提升多步推理可靠性的关键前沿。PRO-STEP-PRM-Data数据集以约10.9万条步骤级标注覆盖3.1万条轨迹,源自HotpotQA与MuSiQue的2000道源问题,每条问题采样16条轨迹并由开源推理模型QwQ-32B依据六维度评估准则进行标注。其84%的人类一致性验证表明该标注体系具备较高可靠性,为RAG系统中实体校准、搜索质量、推理链条及过度自信抑制等环节的细粒度优化提供了可复用的监督信号。该数据集聚焦于生成式PRM的联合训练——同时输出推理依据与二值正确性,这标志着从传统结果级奖励向过程级奖励的范式转换,有望显著提升多跳问答、信息检索等复杂任务的中间步骤质量与最终准确性。PRO-STEP-PRM-Data的发布推动了过程监督在开放域RAG中的规模化应用,为构建更具解释性与鲁棒性的智能检索系统奠定了数据基石。
以上内容由遇见数据集搜集并总结生成


