Wikipedia-Vision-JA
收藏数据集卡片 - Wikipedia-Vision-JA
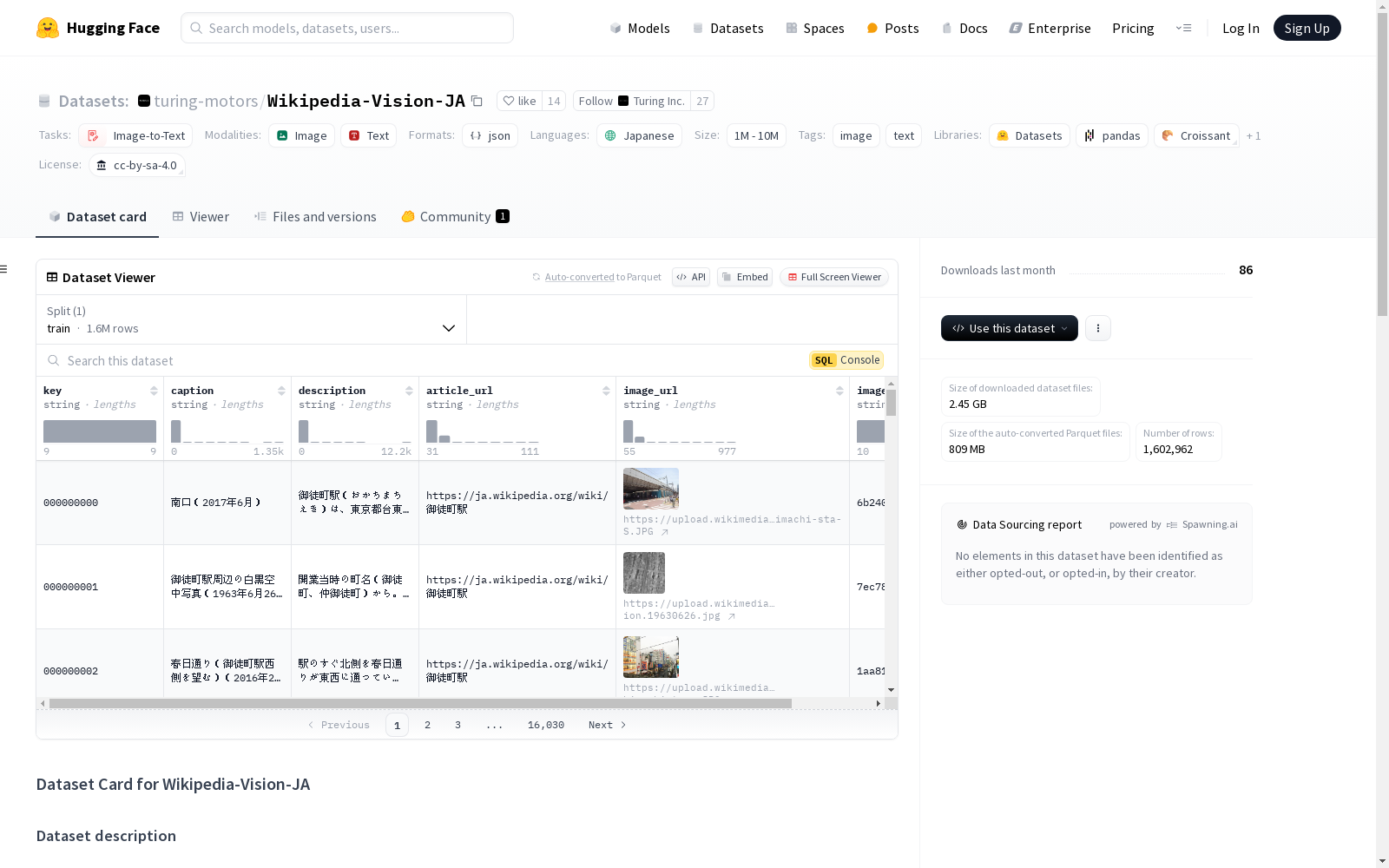
数据集描述
Wikipedia-Vision-JA 是一个从日本维基百科生成的视觉语言模型数据集,包含160万对图像、标题和描述。该数据集本身不包含原始图像数据,而是为每个项目提供一个 image_url。
格式
Wikipedia_Vision_JA.jsonl 包含以下键的JSON格式行:
key: 唯一的JSON IDcaption: 图像的简短标题description: 与图像最接近的文章段落article_url: 包含图像的文章的URLimage_url: 图像的URLimage_hash:image_url的哈希值
示例
json { "key": "000057870", "caption": "アラン・チューリング", "description": "アラン・マシスン・チューリング(Alan Mathison Turing、英語発音: [tjúǝrɪŋ]〔音写の一例:テュァリング〕, OBE, FRS 1912年6月23日 - 1954年6月7日)は、イギリスの数学者、暗号研究者、計算機科学者、哲学者である。日本語において姓 Turing はテューリングとも表記される。 電子計算機の黎明期の研究に従事し、計算機械チューリングマシンとして計算を定式化して、その知性や思考に繋がりうる能力と限界の問題を議論するなど情報処理の基礎的・原理的分野において大きな貢献をした。また、偏微分方程式におけるパターン形成の研究などでも先駆的な業績がある。 経歴・業績の基盤となる出発点は数学であったが、第二次世界大戦中に暗号解読業務に従事した。また黎明期の電子計算機の開発に携わった事でコンピューター・情報処理の基礎理論である計算可能性等に関する仕事をすることとなった。", "article_url": "https://ja.wikipedia.org/wiki/アラン・チューリング", "image_url": "https://upload.wikimedia.org/wikipedia/commons/thumb/7/79/Alan_Turing_az_1930-as_%C3%A9vekben.jpg/400px-Alan_Turing_az_1930-as_%C3%A9vekben.jpg", "image_hash": "52fcf6db07" }
许可证
该数据集继承维基百科的CC-BY-SA 4.0许可证,并以CC-BY-SA 4.0许可证分发。请注意,在使用原始图像数据时,您可能还需要遵守每个图像的许可证,即使该数据集中提供了URL。
致谢
该数据集基于从新能源和工业技术开发组织(NEDO)资助的项目JPNP20017获得的结果。