VEGA 科学论文图文数据理解数据集
收藏超神经2024-07-16 更新2024-07-13 收录
下载链接:
https://hyper.ai/cn/datasets/32831
下载链接
链接失效反馈资源简介:
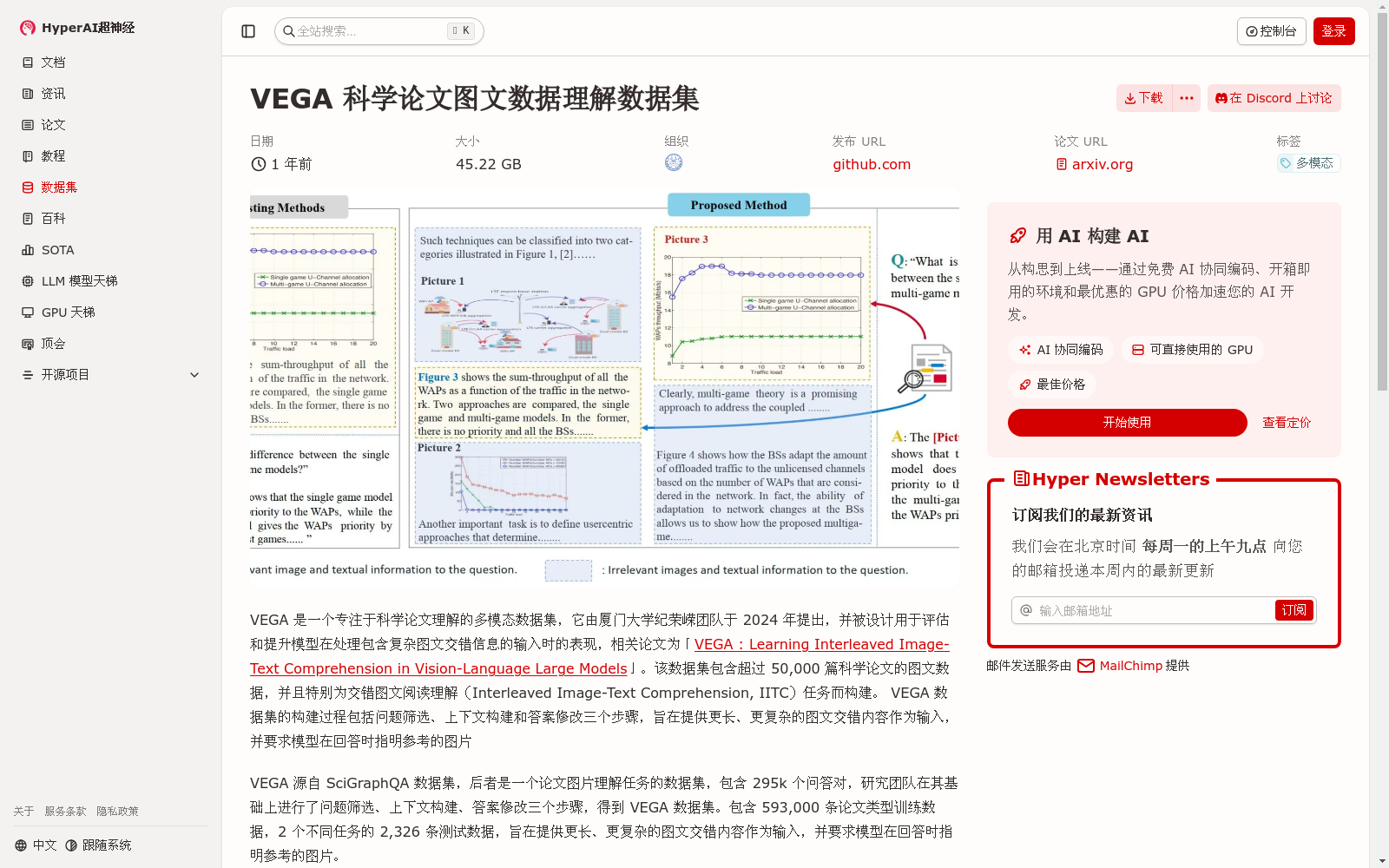
VEGA 是一个专注于科学论文理解的多模态数据集,它由厦门大学纪荣嵘团队于 2024 年提出,并被设计用于评估和提升模型在处理包含复杂图文交错信息的输入时的表现,相关论文为「VEGA : Learning Interleaved Image-Text Comprehension in Vision-Language Large Models」。该数据集包含超过 50,000 篇科学论文的图文数据,并且特别为交错图文阅读理解(Interleaved Image-Text Comprehension, IITC)任务而构建。 VEGA 数据集的构建过程包括问题筛选、上下文构建和答案修改三个步骤,旨在提供更长、更复杂的图文交错内容作为输入,并要求模型在回答时指明参考的图片
VEGA is a multimodal dataset focused on scientific paper comprehension. It was proposed in 2024 by the team led by Ji Rongrong from Xiamen University, and is designed to evaluate and enhance the performance of models when processing inputs containing complex interleaved image-text information. The associated paper is titled "VEGA: Learning Interleaved Image-Text Comprehension in Vision-Language Large Models". This dataset contains image-text data from over 50,000 scientific papers, and is specifically constructed for the Interleaved Image-Text Comprehension (IITC) task. The construction process of the VEGA dataset includes three steps: question screening, context construction, and answer revision. It aims to provide longer and more complex interleaved image-text content as input, and requires models to indicate the referenced images when generating responses.
创建时间:
2024-07-10
AI搜集汇总
数据集介绍
背景与挑战
背景概述
VEGA是一个专注于科学论文理解的多模态数据集,由厦门大学纪荣嵘团队于2024年提出,包含超过50,000篇科学论文的图文数据,专门用于评估模型在交错图文阅读理解任务中的表现。该数据集通过问题筛选、上下文构建和答案修改三个步骤构建,提供复杂图文交错内容,要求模型在回答时指明参考图片,以提升多模态理解能力。
以上内容由AI搜集并总结生成


